



随着大模型技术的持续迭代,AI Agent(智能体)已从概念走向落地,而开发框架作为构建Agent的核心基础设施,也呈现出百花齐放的态势。然而,不同框架的设计理念、核心能力与适用场景差异显著,让许多开发者在技术选型时面临“选择困难”——究竟哪种框架更适配自身项目需求?如何利用框架特性提升Agent的协作效率与稳定性?
为此,我们通过深度拆解项目文档、对比技术架构,梳理出当前最受关注的7大主流AI Agent开发框架:LangGraph、AutoGen、CrewAI、OpenAI Agents SDK、Google Agent Development Kit (ADK)、MetaGPT及PydanticAI。这些框架不仅代表了当前Agent开发的技术前沿,其设计逻辑更能为开发者提供从“单一智能体”到“多智能体协作”的完整思路启发。例如MetaGPT创新性地模拟软件公司的角色分工与标准化流程(SOP),让复杂任务的自动化执行具备了“工业化生产”的特性,大幅降低了多智能体协同的复杂度。
LangGraph:有状态智能体的“底层编排引擎”

LangGraph是LangChain团队推出的开源底层编排框架,核心定位是解决传统LangChain在“动态流程控制”上的短板——例如无法灵活实现循环执行、条件分支等复杂逻辑,从而为构建“长时间运行、有状态管理”的智能体提供技术支撑。它不预设固定的提示词模板,而是以“开放架构”赋予开发者最大控制权,尤其适合需要多智能体协作、状态持续流转的复杂场景。
核心技术特性:以“图结构”重构工作流
LangGraph的核心创新在于采用有向图(Graph)结构组织任务流程,通过“节点(Nodes)”定义具体操作、“边(Edges)”控制流程走向,天然适配非线性执行逻辑:
- 持久化执行(Durable Execution):支持智能体系统从任意中断点精准恢复,避免因网络波动、资源不足导致的任务失败,保障长周期任务(如多轮数据分析、复杂文档生成)的稳定性。
- 人在回路(Human-in-the-loop):允许人工在关键节点介入干预,例如审核智能体决策、修正执行方向,平衡自动化效率与结果安全性,尤其适用于医疗咨询、法律文书处理等对准确性要求极高的场景。
- 全维度记忆管理(Comprehensive Memory):融合“短期推理记忆”(如当前任务上下文)与“长期跨会话记忆”(如历史交互数据),让智能体具备“持续学习”能力,例如客服Agent可记住用户过往需求,提供个性化服务。
- LangSmith深度调试:与LangSmith观测平台无缝衔接,支持可视化查看执行轨迹、监控状态变化、生成性能指标(如调用耗时、成功率),快速定位多智能体协作中的“卡点”。
- 生产级部署能力:针对有状态长流程优化架构,支持弹性扩展,可直接部署至云服务器、容器化环境,满足高并发场景(如电商平台的智能推荐Agent集群)。
生态协同:构建完整Agent开发链路
LangGraph并非孤立工具,而是LangChain生态的重要组成部分,建议与以下工具搭配使用以提升开发效率:
- LangSmith:聚焦Agent性能评估与可观测性,帮助识别LLM调用的低效环节(如重复请求、冗余计算),优化整体系统响应速度。
- LangGraph Platform:提供工作流部署与团队协作功能,支持智能体的复用、配置与共享,搭配LangGraph Studio可视化编辑器,无需复杂编码即可拖拽设计多智能体流程。
- LangChain:借助其模块化组件(如工具调用模块、文档加载模块),快速扩展Agent能力,例如为数据分析Agent集成Excel读取工具、为客服Agent集成知识库检索功能。
AutoGen:多智能体协作的“分布式通信中枢”

AutoGen是微软研究院推出的开源多智能体协作框架,核心目标是通过LLM驱动多个智能体“分工协作”,解决单一智能体难以应对的复杂任务(如多模态内容创作、跨领域问题分析)。它以“消息传递”为核心机制,支持智能体自主交互或与人类协同,同时兼顾灵活性与工业化落地能力。
核心特性:让多智能体“高效对话”
AutoGen的设计围绕“降低多智能体协作门槛”展开,关键特性包括:
- 异步消息传递:支持智能体间非实时通信,避免因某一智能体响应延迟导致整体流程阻塞,例如数据分析Agent生成报告时,文档整理Agent可同步处理其他任务。
- 模块化与可扩展性:采用“插件化”设计,开发者可自定义智能体类型(如对话Agent、工具调用Agent)、通信协议,轻松接入第三方工具(如API接口、本地服务)。
- 全链路可观测:内置日志系统与追踪工具,记录智能体交互过程中的消息内容、调用路径,便于调试多智能体协作中的“信息断层”问题(如指令传递偏差)。
- 分布式部署:支持构建跨节点的智能体网络,例如将计算密集型Agent部署在GPU服务器,轻量型对话Agent部署在边缘节点,优化资源分配。
- 跨语言支持:同时兼容Python与.NET开发环境,满足不同技术栈团队的需求,例如后端用Python开发核心Agent,前端用.NET调用Agent接口实现交互。
- 类型安全保障:提供完整的类型检查功能,减少因数据格式错误导致的协作失败,尤其适合大型团队的规范化开发。
框架架构:三层API满足不同开发需求
AutoGen采用分层设计,从底层核心能力到上层应用封装,覆盖从原型开发到生产落地的全流程:
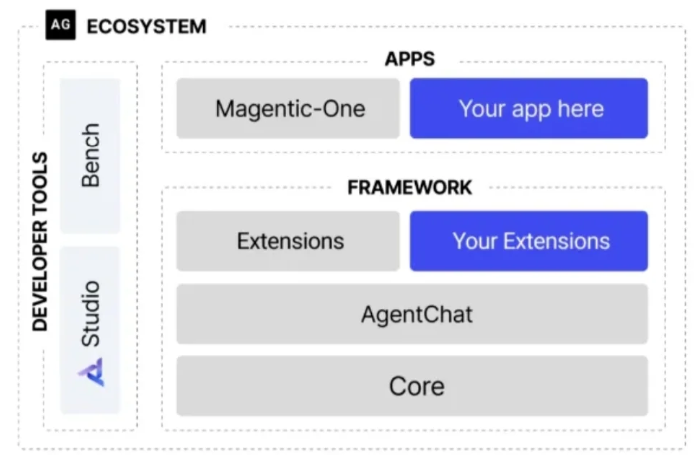
- Core API(核心API):提供消息传递与事件驱动的底层能力,支持智能体在本地及分布式环境运行,兼顾高性能与灵活性,是自定义多智能体系统的基础。
- AgentChat API(智能体聊天API):基于Core API封装预设协作模式(如“专家问答Agent+文档总结Agent”组合),简化原型设计流程,开发者无需从零搭建通信逻辑。
- Extensions API(扩展API):开放第三方扩展接口,支持集成不同LLM(如OpenAI GPT-4、Azure OpenAI)、工具(如代码执行器、数据库查询工具),丰富Agent功能边界。
此外,AutoGen还提供两大开发者工具:
- AutoGen Studio:无代码GUI平台,通过拖拽组件即可配置多智能体流程,适合非技术人员快速搭建demo(如市场调研Agent集群)。
- AutoGen Bench:性能评估套件,提供标准化测试用例(如多轮对话连贯性、任务完成率),帮助开发者对比不同Agent配置的效果。
CrewAI:轻量灵活的“全场景Agent构建工具”

CrewAI是一款轻量级Python原生框架,最大特点是“不依赖任何第三方Agent框架”(如LangChain),从零构建核心能力。它既提供高层抽象的简洁接口(如一键创建智能体小组),又支持底层细节的深度定制(如自定义执行逻辑、提示词模板),平衡了开发效率与灵活性,适合从简单工具调用到企业级复杂系统的全场景需求。
核心价值:为什么选择CrewAI?
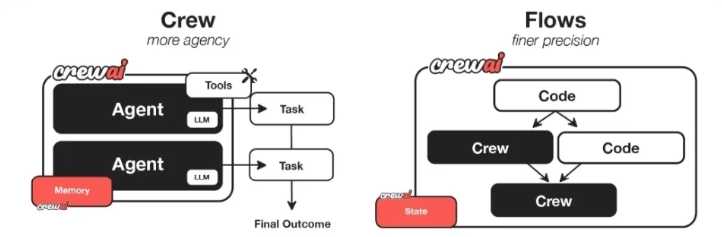
CrewAI通过“智能体小组(Crews)”与“事件流程(Flows)”两大核心概念,释放多智能体自动化潜力,关键优势包括:
- 完全独立的框架设计:不依赖外部Agent工具链,避免“框架嵌套”导致的性能损耗与兼容性问题,同时降低学习成本(无需掌握其他框架的抽象逻辑)。
- 极致性能优化:针对LLM调用、任务调度进行轻量化设计,减少资源占用(如内存消耗、API调用次数),例如简单文档总结任务的执行速度比传统框架提升30%以上。
- 全维度自定义能力:支持从“系统架构”到“细粒度行为”的全链路定制——既可以设计多智能体协作流程(如“产品经理Agent→研发Agent→测试Agent”的软件开发链路),也能修改单个Agent的内部提示词、工具调用规则。
- 场景普适性强:无论是个人开发者的小工具(如智能邮件分类),还是企业级的复杂系统(如供应链数据分析平台),均能稳定适配,且无需大幅调整架构。
- 庞大社区支持:拥有超10万名认证开发者的社区,提供丰富的开源插件(如第三方工具集成包、预设Agent模板)、教程文档与问题解答,降低落地门槛。
此外,CrewAI的“事件驱动流程(CrewAIFlows)”支持通过单次LLM调用实现精准任务编排,例如仅需向LLM发送“生成季度销售报告”指令,Flows会自动分配“数据采集Agent→数据清洗Agent→报告生成Agent”的协作流程,大幅简化开发步骤。
OpenAI Agents SDK:生产级多智能体的“极简开发工具”
OpenAI Agents SDK是OpenAI在其早期项目Swarm基础上优化的生产级框架,继承了Swarm的“多智能体协作”与“任务移交”核心理念,同时新增安全护栏、会话管理等企业级特性。它以“极简原语”为设计核心,让开发者无需复杂编码即可构建稳定的多智能体系统。
核心原语:4个概念掌握SDK精髓
OpenAI Agents SDK的核心能力围绕4个基础原语展开,概念简洁且覆盖多智能体开发关键需求:
- 智能体(Agents):配备特定指令(如“客服专员”“数据分析专家”)与工具(如知识库检索、API调用)的LLM实例,是协作的基本单元。
- 交接(Handoffs):支持智能体将任务委托给更擅长的同伴,例如“通用客服Agent”无法解答的技术问题,可自动移交“技术支持Agent”,避免用户重复描述需求。
- 护栏(Guardrails):与智能体并行运行的输入验证机制,例如过滤违法违规请求、校验用户输入格式(如邮箱、手机号),若检查失败则立即中断流程,保障系统安全。
- 会话(Sessions):自动维护跨智能体的对话历史,无需开发者手动存储上下文,例如用户与“产品咨询Agent”沟通后转至“订单处理Agent”,后者可直接获取前者的交互记录。
核心特性:平衡功能与易用性
OpenAI Agents SDK遵循“功能丰富但概念精简”“开箱即用且灵活定制”两大原则,关键特性包括:
- 内置智能体循环(Agent Loop):自动处理“工具调用→结果返回→LLM决策”的循环流程,直至任务完成,例如“数据查询Agent”会自动重复“调用数据库→分析结果→补充查询”步骤,无需手动触发。
- Python优先设计:直接利用Python原生语法(如函数、类)编排智能体,无需学习新的抽象概念,例如通过
agent1.handoff(agent2, task)即可实现任务移交。 - 函数工具快速集成:支持将任意Python函数转化为智能体工具,并自动生成参数校验规则(基于Pydantic),例如将“Excel数据读取函数”封装为工具,Agent可直接调用并处理格式错误。
- 全链路追踪能力:内置追踪系统,支持可视化查看智能体交互路径、工具调用记录,同时可对接OpenAI的评估工具(如LLM评估API)、模型蒸馏套件,优化系统性能。
- 生产级稳定性:经过OpenAI内部大规模场景验证,支持高并发、低延迟部署,适合电商大促、在线客服等流量峰值场景。
Google Agent Development Kit (ADK):谷歌生态下的“智能体工程化工具链”

Google Agent Development Kit(简称ADK)是谷歌推出的模块化框架,核心优化方向是“让智能体开发成为标准化软件工程”。尽管它深度适配Gemini模型与谷歌云生态(如Cloud Run、Vertex AI),但通过“模型无关性”“部署无关性”设计,仍可兼容其他LLM与部署环境,降低跨平台开发门槛。
核心特性:从开发到部署的全流程支持
ADK的核心能力聚焦“简化智能体工程化落地”,关键特性包括:
- 完善的工具生态(Rich Tool Ecosystem):提供三类工具集成方式——预置谷歌生态工具(如Google Sheets读取、Google Search API)、自定义Python函数工具、OpenAPI标准工具,帮助智能体快速扩展功能(如实时获取天气数据、调用第三方服务)。
- 以代码为核心的开发模式(Code-First Development):通过Python直接编写智能体逻辑、工具调用规则与流程调度代码,支持版本控制(如Git)、单元测试(如pytest),符合软件工程最佳实践,避免“无代码工具”带来的灵活性不足问题。
- 可扩展的多智能体架构(Modular Multi-Agent Systems):支持将智能体按功能拆分为“专业化模块”(如“图像识别Agent”“文本总结Agent”),再按需组合为层级结构(如“父Agent负责任务分配,子Agent负责具体执行”),适配复杂业务场景(如智能医疗诊断系统)。
- 全场景部署能力(Deploy Anywhere):支持两种部署方式——一键容器化部署至谷歌Cloud Run(适合轻量场景)、依托Vertex AI智能体引擎实现弹性扩展(适合高并发场景),同时也可导出为Docker镜像部署至私有服务器。
此外,ADK还支持Agent2Agent(A2A)协议,允许不同团队开发的ADK智能体跨系统协作,例如电商平台的“商品推荐Agent”可与物流服务商的“配送查询Agent”通过A2A协议交互,为用户提供“推荐商品→查询配送时间”的一站式服务。
MetaGPT:模拟“软件公司”的“工业化Agent框架”

MetaGPT是一款以“模拟真实软件公司运作”为核心理念的多智能体框架,它将复杂任务拆解为“角色分工+标准化流程(SOP)”,例如将“开发一款APP”任务分配给“产品经理Agent”“架构师Agent”“研发工程师Agent”“测试工程师Agent”,并通过SOP规范各角色的协作流程,最终实现从“单行需求输入”到“完整交付物输出”的自动化。
核心设计理念:让Agent具备“工业化协作”能力
MetaGPT的核心创新在于将“软件公司管理逻辑”融入多智能体系统,关键概念包括:
- Code=SOP(Team):将标准化流程(SOP)转化为可执行代码,适配LLM组成的“智能体团队”,例如“需求分析SOP”会定义“产品经理Agent需输出用户故事、竞品分析报告,架构师Agent需基于报告设计技术方案”的协作规则。
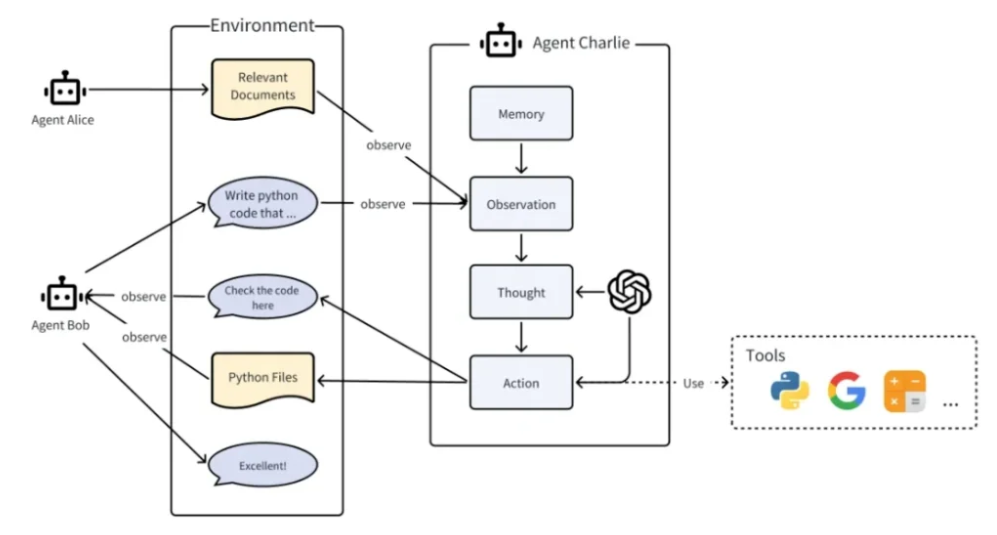
- 智能体(Agent)定义:MetaGPT中的Agent不仅是LLM实例,而是“LLM+观察(Observation)+思考(Thought)+行动(Action)+记忆(Memory)”的综合体——例如“研发工程师Agent”会通过“观察”获取需求文档,“思考”技术实现方案,“行动”生成代码,“记忆”存储历史开发经验。
- 多智能体系统(MultiAgent)定义:由“智能体+环境+SOP+通信+经济模型”组成,其中“经济模型”是MetaGPT的特色设计——通过虚拟“代币”激励Agent高效完成任务(如优质代码生成可获得更多代币),避免消极协作。
实战能力:从需求到交付的全链路自动化
MetaGPT的核心价值在于“降低复杂任务的落地门槛”,以“开发一款简单的待办APP”为例:
- 输入单行需求:“开发一款支持添加、删除、标记待办事项的手机APP”;
- 角色分配:自动创建“产品经理、架构师、前端工程师、后端工程师、测试工程师”Agent;
- 流程执行:按SOP依次完成“需求分析(输出PRD)→架构设计(输出技术方案)→代码开发(输出前后端代码)→测试(输出测试报告)”;
- 输出交付物:最终生成可运行的APP代码、需求文档、测试报告,开发者无需手动干预中间环节。
PydanticAI:强类型保障的“生产级Generative AI框架”

PydanticAI是由Pydantic核心团队打造的Python智能体框架,核心定位是“降低生成式AI(Generative AI)在生产级应用中的开发门槛”。它继承了Pydantic标志性的“强类型校验”能力,同时借鉴FastAPI的“直观高效”设计哲学,让开发者能以“写传统Python项目”的方式构建稳定、可维护的AI Agent系统,尤其适配对数据准确性、代码规范性要求极高的企业场景。
核心价值:解决生产级AI开发的“痛点”
在传统LLM开发中,开发者常面临“数据格式混乱”“模型输出不可控”“调试困难”等问题,而PydanticAI通过以下特性针对性解决:
- Pydantic团队背书的可靠性:其底层验证逻辑与Pydantic核心框架同源,该验证层已被OpenAI SDK、Anthropic SDK、LangChain、LlamaIndex等数十款主流工具集成,经过大规模生产环境验证,稳定性无需担忧。
- 全场景模型兼容:不仅支持OpenAI GPT-4、Anthropic Claude等主流闭源模型,还兼容Gemini、Deepseek、Ollama本地模型、Mistral开源模型,且提供统一调用接口——开发者切换模型时无需修改核心代码,仅需调整配置参数。
- Logfire深度协同的可观测性:与Pydantic Logfire监控工具无缝对接,支持实时追踪LLM调用链路(如请求参数、响应内容、耗时)、校验错误日志、性能指标(如Token消耗、成功率),例如可快速定位“某Agent输出格式错误”是源于模型响应还是参数配置问题。
- 强类型校验保障数据安全:通过Python类型注解定义Agent的输入/输出格式(如
class UserQuery(BaseModel): question: str; user_id: int),自动校验数据合法性——若用户输入非整数的user_id,框架会直接拦截并返回错误,避免非法数据流入LLM导致输出异常。 - Pythonic开发体验:沿用Python原生控制流(如
if/for)与函数定义方式,无需学习新的抽象语法。例如创建“天气查询Agent”时,可直接用def get_weather(agent: WeatherAgent, city: str) -> WeatherResponse的形式定义逻辑,与非AI项目开发习惯一致。 - 标准化响应格式:基于Pydantic模型强制规范LLM输出结构,例如要求“产品推荐Agent”必须返回
{"product_id": str, "reason": str, "price": float}格式,避免多轮对话中输出格式混乱(如有时缺price字段、有时reason为空),保障下游系统(如电商平台)能稳定接收数据。 - 可插拔依赖注入:支持动态注入依赖资源(如Agent的系统提示词、工具链、验证规则),例如在测试环境注入“模拟工具调用结果”,无需真实调用第三方API即可完成单元测试,大幅提升开发效率。
- 实时流式验证:针对LLM流式输出场景(如实时对话),支持“边接收响应边校验”——一旦发现某段输出不符合格式要求(如JSON语法错误),可立即中断接收并提示模型修正,避免用户等待完整响应后才发现错误。
典型适用场景
PydanticAI的强类型特性与稳定性,使其尤其适合以下生产级场景:
- 企业级API开发:构建AI驱动的后端接口(如智能客服API、订单咨询API),需严格保障输入输出格式合规,避免因数据错误导致业务异常。
- 多系统协同Agent:开发需与ERP、CRM等传统系统交互的Agent(如“销售数据分析Agent”),强类型校验可确保Agent与传统系统的数据交互无格式偏差。
- 合规性要求高的领域:在金融(如智能投顾)、医疗(如病历分析)等领域,需通过验证机制确保LLM输出符合行业规范(如不泄露用户隐私、不生成违规建议),PydanticAI的护栏能力可提供关键保障。
框架选型建议:按需匹配,高效落地
7大框架各有侧重,开发者在选型时可结合项目规模、技术栈、核心需求综合判断,以下为针对性建议:
| 框架 | 核心优势 | 适用场景 | 技术栈要求 |
|---|---|---|---|
| LangGraph | 有状态管理、复杂工作流编排 | 长周期任务(如多轮数据分析、文档生成) | Python、LangChain生态 |
| AutoGen | 多智能体分布式协作、跨语言支持 | 分布式Agent系统(如跨团队协作的AI项目) | Python/.NET |
| CrewAI | 轻量独立、全维度自定义 | 从个人工具到企业级系统的全场景 | Python |
| OpenAI Agents SDK | 生产级稳定性、极简原语 | 依赖OpenAI生态、需快速落地的多Agent场景 | Python |
| Google ADK | 谷歌生态适配、工程化工具链 | 依托谷歌云(如Vertex AI)、Gemini的项目 | Python |
| MetaGPT | 模拟企业流程、全链路自动化 | 复杂任务(如软件开发、市场调研) | Python |
| PydanticAI | 强类型校验、生产级合规性 | 企业级API、多系统协同、高合规要求场景 | Python |
无论选择哪种框架,核心原则都是“不追求‘全能’,只适配‘需求’ ”——例如个人开发简单的智能助手,CrewAI的轻量灵活更合适;企业构建依赖谷歌云的工业级Agent,Google ADK的生态协同优势更突出。随着AI Agent技术的持续演进,框架的兼容性与生态融合也将成为重要趋势,未来跨框架协作(如LangGraph编排流程+PydanticAI做数据校验)或成为主流开发模式。
如何从零学会大模型?小白&程序员都能跟上的入门到进阶指南
当AI开始重构各行各业,你或许听过“岗位会被取代”的焦虑,但更关键的真相是:技术迭代中,“效率差”才是竞争力的核心——新岗位的生产效率远高于被替代岗位,整个社会的机会其实在增加。
但对个人而言,只有一句话算数:
“先掌握大模型的人,永远比后掌握的人,多一次职业跃迁的机会。”
回顾计算机、互联网、移动互联网的浪潮,每一次技术革命的初期,率先拥抱新技术的人,都提前拿到了“职场快车道”的门票。我在一线科技企业深耕12年,见过太多这样的案例:3年前主动学大模型的同事,如今要么成为团队技术负责人,要么薪资翻了2-3倍。
深知大模型学习中,“没人带、没方向、缺资源”是最大的拦路虎,我们联合行业专家整理出这套 《AI大模型突围资料包》,不管你是零基础小白,还是想转型的程序员,都能靠它少走90%的弯路:
- ✅ 小白友好的「从零到一学习路径图」(避开晦涩理论,先学能用的技能)
- ✅ 程序员必备的「大模型调优实战手册」(附医疗/金融大厂真实项目案例)
- ✅ 百度/阿里专家闭门录播课(拆解一线企业如何落地大模型)
- ✅ 2025最新大模型行业报告(看清各行业机会,避免盲目跟风)
- ✅ 大厂大模型面试真题(含答案解析,针对性准备offer)
- ✅ 2025大模型岗位需求图谱(明确不同岗位需要掌握的技能点)
所有资料已整理成包,想领《AI大模型入门+进阶学习资源包》的朋友,直接扫下方二维码获取~

① 全套AI大模型应用开发视频教程:从“听懂”到“会用”
不用啃复杂公式,直接学能落地的技术——不管你是想做AI应用,还是调优模型,这套视频都能覆盖:
- 小白入门:提示工程(让AI精准输出你要的结果)、RAG检索增强(解决AI“失忆”问题)
- 程序员进阶:LangChain框架实战(快速搭建AI应用)、Agent智能体开发(让AI自主完成复杂任务)
- 工程落地:模型微调与部署(把模型用到实际业务中)、DeepSeek模型实战(热门开源模型实操)
每个技术点都配“案例+代码演示”,跟着做就能上手!

课程精彩瞬间

② 大模型系统化学习路线:避免“学了就忘、越学越乱”
很多人学大模型走弯路,不是因为不努力,而是方向错了——比如小白一上来就啃深度学习理论,程序员跳过基础直接学微调,最后都卡在“用不起来”。
我们整理的这份「学习路线图」,按“基础→进阶→实战”分3个阶段,每个阶段都明确:
- 该学什么(比如基础阶段先学“AI基础概念+工具使用”)
- 不用学什么(比如小白初期不用深入研究Transformer底层数学原理)
- 学多久、用什么资料(精准匹配学习时间,避免拖延)
跟着路线走,零基础3个月能入门,有基础1个月能上手做项目!

③ 大模型学习书籍&文档:打好理论基础,走得更稳
想长期在大模型领域发展,理论基础不能少——但不用盲目买一堆书,我们精选了「小白能看懂、程序员能查漏」的核心资料:
- 入门书籍:《大模型实战指南》《AI提示工程入门》(用通俗语言讲清核心概念)
- 进阶文档:大模型调优技术白皮书、LangChain官方中文教程(附重点标注,节省阅读时间)
- 权威资料:斯坦福CS224N大模型课程笔记(整理成中文,避免语言障碍)
所有资料都是电子版,手机、电脑随时看,还能直接搜索重点!

④ AI大模型最新行业报告:看清机会,再动手
学技术的核心是“用对地方”——2025年哪些行业需要大模型人才?哪些应用场景最有前景?这份报告帮你理清:
- 行业趋势:医疗(AI辅助诊断)、金融(智能风控)、教育(个性化学习)等10大行业的大模型落地案例
- 岗位需求:大模型开发工程师、AI产品经理、提示工程师的职责差异与技能要求
- 风险提示:哪些领域目前落地难度大,避免浪费时间
不管你是想转行,还是想在现有岗位加技能,这份报告都能帮你精准定位!
⑤ 大模型大厂面试真题:针对性准备,拿offer更稳
学会技术后,如何把技能“变现”成offer?这份真题帮你避开面试坑:
- 基础题:“大模型的上下文窗口是什么?”“RAG的核心原理是什么?”(附标准答案框架)
- 实操题:“如何优化大模型的推理速度?”“用LangChain搭建一个多轮对话系统的步骤?”(含代码示例)
- 场景题:“如果大模型输出错误信息,该怎么解决?”(教你从技术+业务角度回答)
覆盖百度、阿里、腾讯、字节等大厂的最新面试题,帮你提前准备,面试时不慌!

以上资料如何领取?
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么现在必须学大模型?不是焦虑,是事实
最近英特尔、微软等企业宣布裁员,但大模型相关岗位却在疯狂扩招:
- 大厂招聘:百度、阿里的大模型开发岗,3-5年经验薪资能到50K×20薪,比传统开发岗高40%;
- 中小公司:甚至很多传统企业(比如制造业、医疗公司)都在招“会用大模型的人”,要求不高但薪资可观;
- 门槛变化:不出1年,“有大模型项目经验”会成为很多技术岗、产品岗的简历门槛,现在学就是抢占先机。
风口不会等任何人——与其担心“被淘汰”,不如主动学技术,把“焦虑”变成“竞争力”!

最后:全套资料再领一次,别错过这次机会
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









