









 本文介绍了度量学习,其目的是调整样本特征向量距离,可用于人脸识别。与经典识别网络相比,它能适应特定图像识别场景。文中阐述了度量学习基本流程和关键问题,介绍了典型网络Prototypical Network,还详细讲解了多种损失函数,如Triplet Loss、N - pair loss等。
本文介绍了度量学习,其目的是调整样本特征向量距离,可用于人脸识别。与经典识别网络相比,它能适应特定图像识别场景。文中阐述了度量学习基本流程和关键问题,介绍了典型网络Prototypical Network,还详细讲解了多种损失函数,如Triplet Loss、N - pair loss等。
文章目录
introduction
度量学习的对象通常是样本特征向量的距离,度量学习的目的是通过训练和学习,减小或限制同类样本之间的距离,同时增大不同类别样本之间的距离。
度量学习 (Metric Learning) == 距离度量学习 (Distance Metric Learning,DML) == 相似度学习
是人脸识别中常用的机器学习方法,由Eric Xing在NIPS 2002提出。既可基于监督学习的,也可以基于非监督学习。
与经典识别网络的区别
经典识别网络有一个bug:必须提前设定好类别数,例如softmax loss。
这也就意味着,每增加一个新种类,就要重新定义网络模型,并从头训练一遍。
比如我们要做一个门禁系统,每增加或减少一个员工(等于是一个新类别),就要修改识别网络并重新训练。很明显,这种做法在某些实际运用中很不科学。
科普一下在训练和测试人脸识别分类器的时候经常被提到的Open-set 和Close-set:—
close-set,就是所有的测试集都在训练集中出现过。所以预测结果是图片的ID,如果想要测试两张图片是否是同一个,那么就看这两张图片的预测ID是否一样即可。
open-set,就是测试的图片并没有在训练集中出现过,那么每张测试图片的预测结果是特征向量,如果想要比较两张图片的人脸是否属于同一个人,需要测试图像特征向量的距离。理想的Open-set就需要度量学习,人脸识别学习到的特征应当在特定的度量空间中,满足同一类的最大类内距离小于不同类的最小类间距离。然后再使用最近邻检索就可以实现良好的人脸识别和人脸验证性能。
然而softmax loss仅仅能够使得特征可分,还不能够使得特征具有可判别性,所以需要对softmax loss进行改造。
因此,Metric Learning作为经典识别网络的替代方案,可以很好地适应某些特定的图像识别场景。一种较好的做法,是丢弃经典神经网络最后的softmax层,改成直接输出一个feature vector,去特征库里面按照Metric Learning寻找最近邻的类别作为匹配项。
基本流程:
一般的度量学习包含以下步骤:
- Encoder编码模型:用于把原始数据编码为特征向量(重点如何训练模型)
- 相似度判别算法:将一对特征向量进行相似度比对(重点如何计算相似度,阈值如何设定)
关键问题:
- 网络设计:代表有孪生神经网络(Siamese network)
- hard negative mining:找出难以区分的样本,更利于训练收敛。
- pairs weighting/pair-based loss functions:改进loss函数,促使网络优化, 使具有相同标签的样本在嵌入空间中尽量接近 ,具有不同标签的样本在嵌入空间中尽量远离。
典型网络
Prototypical Network(ProtoPNet)
Prototypical Network(ProtoPNet)是一种用于图像识别的深度学习模型,它通过原型(prototypes)来实现对类别的解释和分类。以下是ProtoPNet的神经网络结构的基本组成部分:
-
输入层:接收原始图像数据。
-
特征提取器(Feature Extractor):通常使用预训练的卷积神经网络(CNN)作为特征提取器,例如ResNet、VGG等。这一层将图像转换为特征向量或特征图。
-
特征序列化(Feature Serialization):将特征图展平或分割成序列化的形式,形成视觉序列(visual sequence),这些序列将作为后续处理的输入。
-
原型层(Prototype Layer):在ProtoPNet中,原型层是核心组件,它包含了一组可学习的原型向量,每个类别有多个原型。这些原型通过与输入特征序列计算相似度来学习类别的代表性特征。
-
相似度计算:使用特定的相似度函数(如余弦相似度或欧几里得距离)来计算输入特征与每个类别原型之间的相似度。
-
池化(Pooling):通常采用最大池化(Max Pooling)来从每个类别的多个原型中选择最具代表性的原型。
-
全连接层(Fully Connected Layer, FC):将池化后的相似度分数转换为类别的预测对数几率(logits)。
-
分类头(Classification Head):通常使用softmax函数来将对数几率转换为类别概率,实现最终的分类。
-
损失函数:使用交叉熵损失函数来训练模型,使其能够正确分类图像。
-
原型集中(Prototype Concentration):为了提高模型的可解释性,可能会添加额外的损失函数来鼓励原型集中在类别的显著特征上。
-
训练过程:在训练过程中,通过反向传播算法和优化器(如SGD或Adam)来更新网络的权重。
-
可视化:ProtoPNet的原型可以被可视化,以展示模型是如何通过关注图像的特定部分来进行分类的。
ProtoPNet的结构设计使其在分类的同时提供了一种解释模型决策的方式,这对于需要模型透明度和可解释性的应用场景非常重要。通过原型的可视化,用户可以直观地理解模型识别不同类别的关键特征。
在ProtoPNet中,原型层是全连接网络吗?
在ProtoPNet中,原型层不是一个全连接网络,而是由一组可学习的原型向量组成,这些向量代表了各个类别的典型特征。每个类别有多个原型,它们是通过训练过程中的数据驱动学习得到的。
原型层的工作流程通常包括以下几个步骤:
特征提取:输入图像通过CNN等特征提取器转换为特征向量或特征图。
序列化:将提取的二维特征图展平或分割成一系列的一维特征序列。
相似度计算:对于每个类别的每个原型,计算输入特征序列与该原型之间的相似度。这通常通过计算特征向量和原型向量之间的点积来实现。
池化操作:使用池化(如最大池化)来从每个类别的所有原型相似度中选择最具代表性的相似度分数。
分类决策:根据池化后的相似度分数,通过一个全连接层或类似的机制,将这些分数转换为最终的类别预测。
在ProtoPNet中,原型层的设计是模型可解释性的关键,因为它允许模型通过可视化原型来解释其决策过程。原型层的原型向量通过学习与输入图像的特征序列之间的相似度来进行类别判别,而不是通过传统的全连接层来进行决策。这种方法使得ProtoPNet在保持准确性的同时,提供了一种直观的类别判别解释。
在ProtoPNet中,全连接层与特征提取器是直接相连的吗?
在传统的ProtoPNet架构中,全连接层(Fully Connected Layer, FC)并不直接与特征提取器相连。相反,它们之间存在一个原型层,这一层是ProtoPNet的核心,用于实现模型的可解释性。以下是ProtoPNet中各组件之间的连接方式:
1. **特征提取器**:首先,输入图像通过特征提取器(如CNN)来提取特征。这些特征通常是高维的,并且捕捉了图像中的视觉信息。
2. **特征序列化**:接着,特征提取器的输出(例如,二维特征图)被序列化为一维特征向量,形成视觉序列。
3. **原型层**:视觉序列随后被送入原型层。在原型层中,每个类别有多个原型向量,这些原型向量是通过学习过程中的优化目标来调整的。原型层不涉及权重参数的学习,而是通过计算输入特征向量与各个类别原型之间的相似度来工作。
4. **相似度聚合**:通过某种形式的聚合(如最大池化或平均池化)处理每个类别的相似度分数,以得到每个类别的代表性分数。
5. **全连接层**:聚合后的分数被送入一个全连接层,该层通常包含一个输出节点对应每个类别的逻辑单元。全连接层的权重是可学习的,并且这一层负责将原型层的输出转换为最终的类别预测。
6. **分类决策**:最后,全连接层的输出通过一个softmax或其他激活函数来生成每个类别的概率分布,从而实现最终的分类决策。
在ProtoPNet中,全连接层的作用是将原型层提供的类别相似度分数转换为类别概率,而不是直接处理特征提取器的原始输出。这种设计允许模型在保持准确性的同时,通过原型层提供的解释能力来增强其可解释性。
基于vit的原型网络
ProtoPFormer: Concentrating on Prototypical Parts in Vision Transformers for Interpretable Image Recognition(有源码)
损失函数
度量学习(metric learning)损失函数
常用度量学习损失函数
度量学习 度量函数 metric learning deep metric learning 深度度量学习
『深度概念』度量学习中损失函数的学习与深入理解
浅谈人脸识别中的loss 损失函数
| baseline | Softmax loss |
| 基于距离的算法 | Triplet loss, center loss |
| 基于角度的算法 | angular loss |
基本loss概述
1. Softmax loss
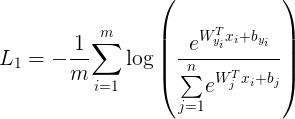

这种方式只考虑了能否正确分类,却没有考虑类间距离。所以提出了center loss 损失函数。
2. Center loss
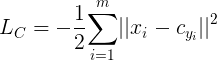
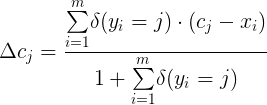
center loss 考虑到不仅仅是分类要对,而且要求类间有一定的距离。上面的公式中
C
y
i
C_{y_{i}}
Cyi表示某一类的中心,
X
i
\mathcal{X}_{i}
Xi表示每个人脸的特征值。作者在softmax loss的基础上加入了
L
C
L_{C}
LC,同时使用参数
λ
\lambda
λ来控制类内距离,整体的损失函数如下:
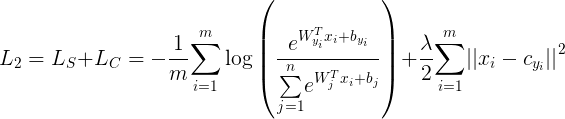

3. Triplet Loss
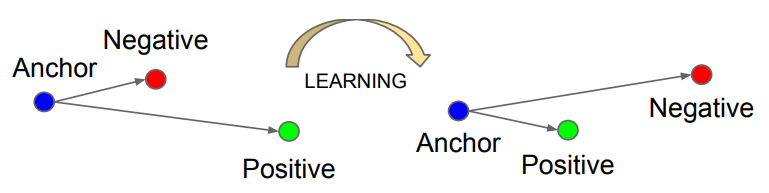
三元组损失函数,三元组由Anchor, Negative, Positive这三个组成。从上图可以看到,一开始Anchor离Positive比较远,我们想让Anchor和Positive尽量的靠近(同类距离),Anchor和Negative尽量的远离(类间距离)。
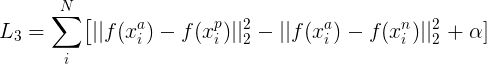
表达式左边为同类距离 ,右边为不同的类之间的距离。使用梯度下降法优化的过程就是让类内距离不断下降,类间距离不断提升,这样损失函数才能不断地缩小。
Triplet Loss和triplets挖掘
更多原理与细节请参考文章:
https://omoindrot.github.io/triplet-loss
中文翻译:Tensorflow实现Triplet Loss
对应tensorflow代码:https://github.com/omoindrot/tensorflow-triplet-loss
如何将triplet应用于分类:
https://github.com/adambielski/siamese-triplet
networks.py
EmbeddingNet — base network for encoding images into
embedding vector
ClassificationNet — wrapper for an embedding network,adds a fully connected layer and log softmax for classification
SiameseNet — wrapper for an embedding network, processes pairs of
inputs TripletNet - wrapper for an embedding network, processes triplets of inputs
triplet网络模型:
https://github.com/SpikeKing/triplet-loss-mnist
Triplet Loss的核心是锚示例、正示例、负示例共享模型,通过模型,将锚示例与正示例聚类,远离负示例。
Triplet Loss Model的结构如下:
输入:三个输入,即锚示例、正示例、负示例,不同示例的结构相同;
模型:一个共享模型,支持替换为任意网络结构;
输出:一个输出,即三个模型输出的拼接。
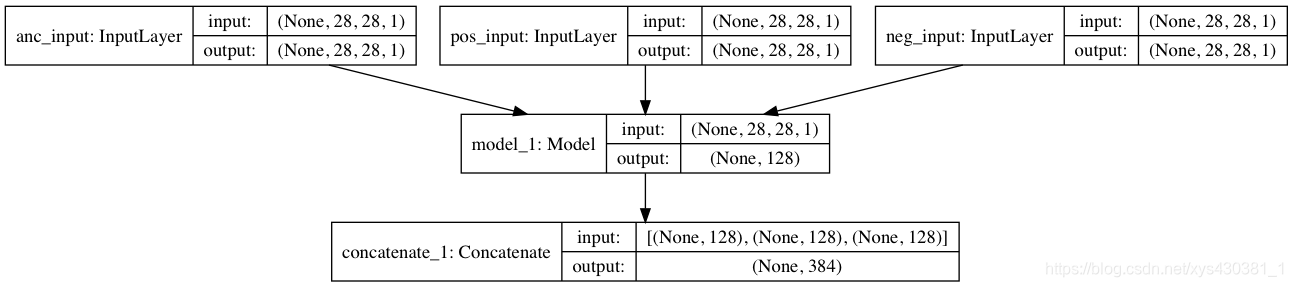
为什么不用softmax?
谷歌的论文FaceNet: A Unified Embedding for Face Recognition and Clustering最早将triplet loss应用到人脸识别中。他们提出了一种实现人脸嵌入和在线triplet挖掘的方法,这部分内容我们将在后面章节介绍。
在监督学习中,我们通常都有一个有限大小的样本类别集合,因此可以使用softmax和交叉熵来训练网络。但是,有些情况下,我们的样本类别集合很大,比如在人脸识别中,标签集很大,而我们的任务仅仅是判断两个未见过的人脸是否来自同一个人。
Triplet loss就是专为上述任务设计的。它可以帮我们学习一种人脸嵌入,使得同一个人的人脸在嵌入空间中尽量接近,不同人的人脸在嵌入空间中尽量远离。
定义损失
Triplet可以理解为一个三元组,它由三部分组成:
- anchor在这里我们翻译为原点
- positive同类样本点(与原点同类)
- negative异类样本点
针对三元组中的每个元素(样本),训练一个参数共享或者不共享的网络,得到三个元素的特征表达(embedings)

Triplet loss的目标:
- 使具有相同标签的样本在嵌入空间中尽量接近
- 使具有不同标签的样本在嵌入空间中尽量远离
值得注意的一点是,如果只遵循以上两点,最后嵌入空间中相同类别的样本可能collapse到一个很小的圈子里,即同一类别的样本簇中样本间的距离很小,不同类别的样本簇之间也会偏小。因此,我们加入间隔(margin)的概念——跟SVM中的间隔意思差不多。只要不同类别样本簇简单距离大于这个间隔就阔以了。
我们要求,在嵌入空间d中,三元组(a,p,n)的损失函数为:
L
=
max
(
d
(
a
,
p
)
−
d
(
a
,
n
)
+
margin
,
0
)
L=\max (d(a, p)-d(a, n)+\operatorname{margin}, 0)
L=max(d(a,p)−d(a,n)+margin,0)
最小化该L,则d(a,p)→0, d(a,n)>margin。
Triplets挖掘
基于前文定义的Triplet loss,可以将三元组分为一下三个类别:
- easy triplets:可以使loss = 0的三元组,即容易分辨的三元组
- hard triplets:d(a,n)<d(a,p)的三元组,即一定会误识别的三元组
- semi-hard triplets:d(a,p)<d(a,n)<d(a,p)+margin的三元组,即处在模糊区域(关键区域)的三元组

图中,a为原点位置,p为同类样本例子,不同颜色表示的区域表示异类样本分布于三元组类别的关系.
显然,中间的Semi-hard negatives样本对我们网络模型的训练至关重要。
N-pair loss
Sohn, K.: Improved deep metric learning with multi-class n-pair loss objective. In:
NIPS. (2016)
Improved Deep Metric Learning with Multi-class N-pair Loss Objective论文N-pair loss解读与实现
pytorch代码:1、https://github.com/ChaofWang/Npair_loss_pytorch/blob/master/Npair_loss.py
2、https://github.com/leeesangwon/PyTorch-Image-Retrieval/blob/public/losses.py
tensorflow代码(多种度量学习loss函数):https://github.com/tensorflow/tensorflow/blob/r1.10/tensorflow/contrib/losses/python/metric_learning/metric_loss_ops.py
Angular Loss
【2017_ICCV】Deep Metric Learning with Angular Loss
tensorflow代码:https://github.com/geonm/tf_angular_loss
pytorch代码:https://github.com/leeesangwon/PyTorch-Image-Retrieval/blob/public/losses.py
SphereFace论文学习:该文提到的A-softmax loss就是Angular Loss的源泉
- 提出了Angular Loss,用角度关系作为相似性度量。- 之前的方法主要用距离进行相似性度量,距离度量在尺度变化时比较敏感,并且对于不同的intra-class采用相同的margin也不合适,Angular Loss自带旋转不变和尺度不变。
- 优点:
- 引入尺度不变,提高了目标对于特征差异的鲁棒性;
- 增加了三阶几何限制,捕获了triplet triangles的附加局部结构;
- 收敛更好。
文章列表
Improved Deep Metric Learning with Multi-class N-pair Loss Objective论文N-pair loss解读与实现

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









