






乾明 发自 凹非寺
量子位 出品 | 公众号 QbitAI
XL号的Transformer来了!
近日,CMU和谷歌联手发布一篇论文,介绍了一种新的语言建模方法Transformer-XL。
这里的XL,指的是extra long,意思是超长,表示Transformer-XL在语言建模中长距离依赖问题上有非常好的表现。同时,也暗示着它就是为长距离依赖问题而生。

长距离依赖问题,是当前文本处理模型面临的难题,也是RNN失败的地方。
相比之下,Transformer-XL学习的依赖要比RNN长80%。比Vanilla Transformers快450%。
在短序列和长序列上,都有很好的性能表现。更可怕的还在速度上,在评估过程中,比Vanilla Transformers快了1800倍以上。
效果?更是不消多数。在enwiki8、text8、WikiText-2、WikiText-103和One Billion Words等数据集实验中,都处于领先水平。

尤其是字符级别的enwiki8中,Transformer-XL是第一个突破1.0的。
Transformer-XL是怎么做的?
关键有两点,一是在Transformer中引入重用机制,二是使用相对位置编码。
但是,想弄清楚Transformer-XL,要先从Transformer的局限开始说起。
Transformer的局限
在将Transformer或者是自注意力机制(self-attention)应用到语言建模中,需要解决的核心问题是如何训练Transformer,将任意长度的语境有效地编码为固定大小的表征。
如果有无限的存储和计算资源,一个无条件的Transformer就能解决这个问题。但在实际的运用中,资源是有限的,这个思路就行不通了。
另一个思路,就是将序列分成可以管理的较短片段,在每个片段内训练模型,忽略来自先前片段的所有语境信息,如下图的中a部分所示。

这就是之前Rami Al-Rfou(谷歌AI高级软件工程师)等人采用的方法。
在这种训练范式下,信息不可能向前或向后穿过各个部分进行传递,这也就带来了新的麻烦。
首先,Transformer最大可能的依赖长度,将受到每个片段的长度限制。字符级的语言建模上通常是几百。所以,尽管与RNN相比,Transformer受梯度消失问题的影响较小,但在Vanilla 模型中,并不能充分利用这个优势。
而且,简单地将语料库分割成固定长度的片段,也会导致语境碎片的问题。
如上图中b部分所示,在评估期间的每个步骤,Vanilla模型也将会消耗与训练中相同长度的片段,但仅仅在最后位置进行一次预测。在下一步,的这个片段仅仅只是向右移动了一个位置,然后又从头处理新的片段。
虽然这样做有助于确保进行每个预测的时候,利用训练期间暴露的最长可能语境,还能减轻训练中遇到的语境碎片问题。但真的是太贵了。
引入重用机制
为了突破使用固定长度片段带来的语境限制,这篇论文在Transformer体系结构中引入了重复机制。
在训练期间,为模型处理下一个新的片段时,会缓存前一个片段计算的隐藏状态序列,并作为扩展语境重用,如下图中所示。
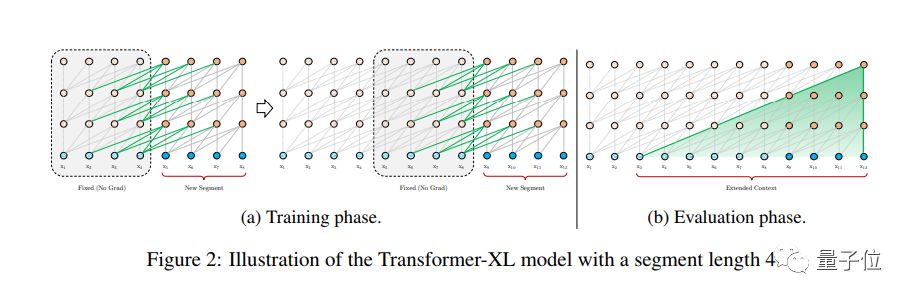
虽然梯度仍然保留在一个片段内,但这个额外的输入,允许网络利用历史信息,从而能够对长期依赖建模,并避免场景碎片。
除了这些好处之外,重复机制还能够加快评估速度。在评估期间,可以重复使用来自先前片段的表征,而不是像Vanilla模型从头开始。
在针对enwiki8数据集的实验中,Transformer-XL在评估过程中比Vanilla模型快1800倍。
相对位置编码
但是,想要重用隐藏状态,还需要解决一个关键的技术挑战:重用状态时,如何保持位置信息的一致性?
在标准的Transformer中,序列顺序的信息,都是由一组位置编码提供,每一个位置都有绝对的位置信息。但将这个逻辑应用到重用机制中时,会导致性能损失。
这个问题的解决思路是,对隐藏状态中的相对位置信息进行编码。从概念上讲,位置编码为模型提供了关于应如何收集信息的时间线索,即应该在哪里介入处理。
以相对的方式定义时间线索,将相同的信息注入每层的注意分数,更加直观,也更通用。
基于这个思路,可以创建一组相对位置编码,使得重用机制变得可行,也不会丢失任何的时间信息。
将相对位置嵌入Transformer之中,并配合重用机制,就得到了Transformer-XL的架构。
基于这些改进,Transformer-XL在相关的数据集上都取得了很好的成绩。论文中表示,这是第一个在字符级和单词级建模方面比RNN结果更好的自注意力模型。
谁写的?
这篇论文并列第一作者分别是来自CMU的Zihang Dai和谷歌大脑的杨植麟,都是博士生。
其中,Zihang Dai二年级的博士生,杨植麟是CMU的四年级博士生,师从苹果首任AI总监Ruslan Salakhutdinov。

其他作者分别是CMU的Yiming Yang教授、谷歌AI的研究与工程总监William W. Cohen、CMU语言技术研究所主任Jaime Carbonell、谷歌大脑的研究科学家Quoc V. Le、CMU的Ruslan Salakhutdinov。
从署名来看,可是说大牛云集,但这篇论文还是遭到了ICLR 2019的拒稿。
折戟ICLR 2019
在2018年9月28日的时候,论文提交给了ICLR 2019,得到了拒稿的意见。
ICLR 2019会议论文717区主席1给出了拒稿的意见。
TA表示,尽管语言建模有了(显着的)改进,但是更好的语言模型(在字符和单词级别)是否能够在下游任务中获得更好的性能,或者是否可以使用这种技术来构建更好的条件语言模型仍然是一个棘手的问题。
仅就目前的情况,看不到什么优点。需要将这种技术应用到文档中,看看能否在计算效率和性能之间取得良好的表现。
另一个给出拒稿意见的评审,也是来自717区。
TA给出了四点评审意见:
第一,WikiText-103上的实验结果很好,但在其他三个数据集中,几乎没有增益。
第二,比较速度,应该跟更多的LM模型比较,Al-Rfou的不是最快的。
第三,在方程周围,写的不太清楚, 而且在第3页的结尾等地方有拼写错误。
第四,整体而言,这篇论文有所贡献,重复机制只是一个类似于残留网络的想法,但更简化了。相对位置编码,也不是新的想法。
对于这些问题,以及其他的建议,论文作者都给出了回应。
现在放出来的论文是更新版,还附带Transformer-XL的实现代码、预训练模型和超参数。
如果你感兴趣,请收好传送门~
传送门
论文地址:
https://arxiv.org/abs/1901.02860
项目地址:
https://github.com/kimiyoung/transformer-xl
拒稿现场:
https://openreview.net/forum?id=HJePno0cYm
— 完 —
加入社群
量子位AI社群开始招募啦,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进专业群请在量子位公众号(QbitAI)对话界面回复关键字“专业群”,获取入群方式。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !















 874
874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









