









Cost-Effective Active Learning from Diverse Labelers(IJCAI’17)
这篇文章指出在主动学习过程中标注数据时要考虑“Oracle are cost-sensitive”,有高质量、高成本的专家和低质量、低成本的专家可以选择来标注。这篇文章是的假设是:有多个专家,擅长的领域知识不同、质量也不同。
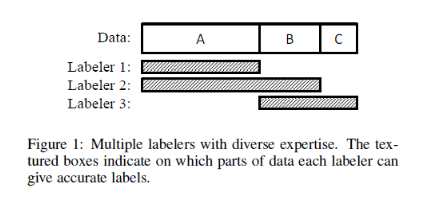

假设现在又一个小的有标签数据集 L = { ( x i , y i ) } i = 1 n l L=\left\{\left(\mathrm{x}_{i}, y_{i}\right)\right\}_{i=1}^{n_{l}} L={(xi,yi)}i=1nl,有 n l n_l nl个样本;无标签样本集 U = { x j } j = n l + 1 n l + n u U = \left\{\mathrm{x}_{j}\right\}_{j=n_{l}+1}^{n_{l}+n_{u}} U={xj}j=nl+1nl+nu 有 n u n_u nu个样本,一般 n l ≪ n u n_{l} \ll n_{u} nl≪nu,还有一个标注专家待选集 A = { a 1 , ⋯ , a m } A=\left\{a_{1}, \cdots, a_{m}\right\} A={a1,⋯,am}。令 y ^ i j \hat{y}_{i j} y^ij时专家 a i a_i ai给样本 x j x_j xj提供的标签。
主动学习的每次迭代中,算法选择一个样本-专家对
(
x
∗
,
a
∗
)
\left(\mathrm{x}^{*}, a^{*}\right)
(x∗,a∗),然后向专家
a
∗
a^*
a∗查询
x
∗
x^*
x∗的标签,选择样本和标注者都基于一个评价函数
Q
Q
Q:
(
x
∗
,
a
∗
)
=
arg
max
x
∈
U
,
a
∈
A
Q
(
x
,
a
)
\left(\mathrm{x}^{*}, a^{*}\right)=\underset{\mathrm{x} \in U, a \in A}{\arg \max } Q(\mathrm{x}, a)
(x∗,a∗)=x∈U,a∈AargmaxQ(x,a)
所以任务就是设计评价函数
Q
(
x
,
a
)
Q(\mathrm{x}, a)
Q(x,a),来衡量
(
x
,
a
)
(\mathrm{x}, a)
(x,a)的cost-effectiveness。
如何设计函数 Q Q Q?要综合考虑三个因素:样本有用、标签准确、专家性价比。结合起来
1、Usefulness of the Instance
对于二分类问题,就选概率接近0.5的:
r
(
x
)
=
∣
p
(
y
=
1
∣
x
)
−
0.5
∣
(1)
r(\mathrm{x})=|p(y=1 \mid \mathrm{x})-0.5|\tag {1}
r(x)=∣p(y=1∣x)−0.5∣(1)
用logistic regression来分类:
p
(
y
=
1
∣
x
)
=
1
1
+
exp
(
−
f
(
x
)
)
p(y=1 \mid \mathrm{x})=\frac{1}{1+\exp (-f(\mathrm{x}))}
p(y=1∣x)=1+exp(−f(x))1
其中
f
(
x
)
=
w
⊤
x
+
b
f(\mathrm{x})=\mathrm{w}^{\top} \mathrm{x}+b
f(x)=w⊤x+b。对于多分类问题:
r
(
x
)
=
1
−
max
y
∈
Y
p
(
y
∣
x
)
(2)
r(\mathrm{x})=1-\max _{y \in \mathcal{Y}} p(y \mid \mathrm{x})\tag {2}
r(x)=1−y∈Ymaxp(y∣x)(2)
2、Accuracy of the Labeling
q i ( x j ) = 1 t ∑ x k ∈ N ( x j , t ) S ( x j , x k ) I [ y k = = y ^ i k ] (3) q_{i}\left(\mathrm{x}_{j}\right)=\frac{1}{t} \sum_{\mathrm{x}_{k} \in N\left(\mathrm{x}_{j}, t\right)} S\left(\mathrm{x}_{j}, \mathrm{x}_{k}\right) I\left[y_{k}==\hat{y}_{i k}\right]\tag {3} qi(xj)=t1xk∈N(xj,t)∑S(xj,xk)I[yk==y^ik](3)
其中 N ( x j , t ) N\left(\mathrm{x}_{j}, t\right) N(xj,t)返回原始有标签数据集中 x j x_j xj最附近的 t t t个邻居, S ( x j , x k ) S\left(\mathrm{x}_{j}, \mathrm{x}_{k}\right) S(xj,xk)衡量 x j x_j xj个 x k x_k xk的相似度, I [ ⋅ ] I[\cdot] I[⋅]是指示函数,相等返回1,否则返0。这篇文章里就用欧氏距离。显然, x j x_j xj的 t t t个邻居中,更像 x j x_j xj的贡献更多的estimation of q i ( x j ) q_{i}\left(\mathrm{x}_{j}\right) qi(xj)。
3、Cost of the Query
高质量标注者高成本。标注者
a
i
a_i
ai标注一个标签的成本
c
i
c_i
ci:
c
i
=
g
(
1
n
l
∑
j
=
1
n
l
I
[
y
j
=
=
y
^
i
j
]
)
(4)
c_{i}=g\left(\frac{1}{n_{l}} \sum_{j=1}^{n_{l}} I\left[y_{j}==\hat{y}_{i j}\right]\right)\tag {4}
ci=g(nl1j=1∑nlI[yj==y^ij])(4)
其中
1
n
l
∑
j
=
1
n
l
I
[
y
j
=
=
y
^
i
j
]
\frac{1}{n_{l}} \sum_{j=1}^{n_{l}} I\left[y_{j}==\hat{y}_{i j}\right]
nl1∑j=1nlI[yj==y^ij]计算标注者
a
i
a_i
ai在
L
L
L的准确率,
g
(
⋅
)
g(\cdot)
g(⋅)表述了成本和准确率之前的关系,比如:
g
(
z
)
=
z
g(z)=z
g(z)=z
三合一,Cost-Effectiveness
综合以上三点,
Q
Q
Q函数就设计出来了:
Q
(
x
j
,
a
i
)
=
q
i
(
x
j
)
⋅
r
(
x
j
)
c
i
(5)
Q\left(\mathrm{x}_{j}, a_{i}\right)=\frac{q_{i}\left(\mathrm{x}_{j}\right) \cdot r\left(\mathrm{x}_{j}\right)}{c_{i}}\tag {5}
Q(xj,ai)=ciqi(xj)⋅r(xj)(5)
选instance-labeler pair:
(
x
∗
,
a
∗
)
=
arg
max
x
j
∈
U
,
a
i
∈
A
Q
(
x
j
,
a
i
)
(6)
\left(\mathrm{x}^{*}, a^{*}\right)=\underset{\mathbf{x}_{j} \in U, a_{i} \in A}{\arg \max } Q\left(\mathrm{x}_{j}, a_{i}\right)\tag {6}
(x∗,a∗)=xj∈U,ai∈AargmaxQ(xj,ai)(6)
算法流程:

实验结果:

黑线ALC是每次只选在全局数据最可靠的标注者。在UCI数据集上本文的效果最好,在现实世界数据集上也没好太多。















 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









