







RCNN详解
1. 背景与介绍
目标检测
在学习目标检测算法之前,我们先来了解一下到底什么是目标检测。
对于我而言,我学习神经网络的入门项目就是手写数字体识别(我相信对于大部分人来说,入门应该都是从这个项目做起的)。数字体的识别的数据集以及最后测试所用的数据,都是一张只有一个数字的图像,然后将这张图像作为输入,送入模型中进行预测。对于猫狗识别而言同样如此(详情可以见吴恩达老师的课程),我们的数据集中要么只包含狗,要么只包含猫,然后模型最后的预测往往只是给一个结果,是猫或是狗。这样的分类任务通常被称为对象识别任务。(如下图中输入一个猫咪图片,经过模型的预测之后会给出是“猫”的结果)

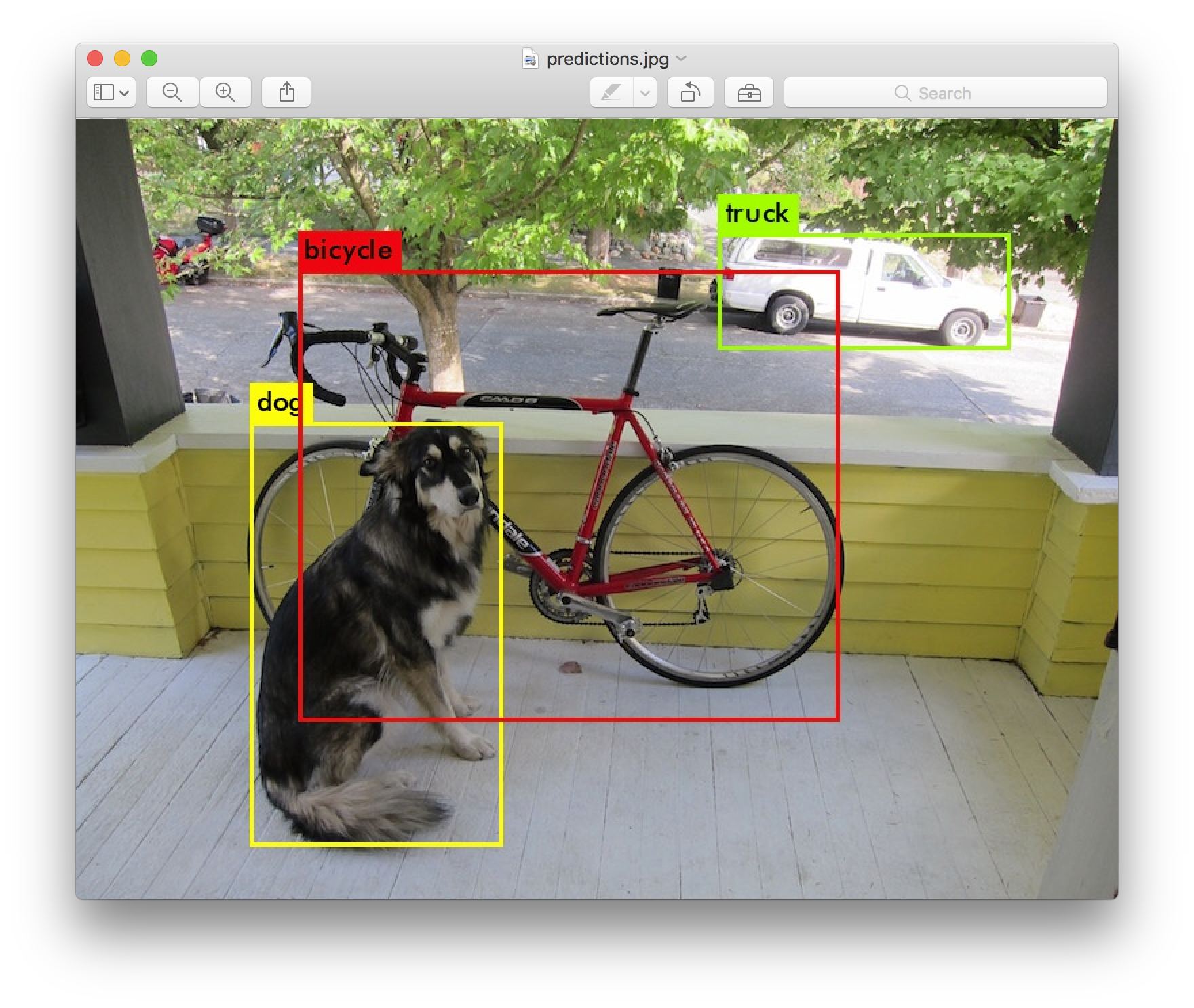
而目标检测的任务是在识别所需要分类物体的同时,在图片中定位目标的位置。(如下图所示)
RCNN的横空出世
RCNN全称是Regions with CNN Features, 是由Ross Girshick在论文《Rich feature hierarchies for accurate object detection and semantic segmentation》提出的一个将深度学习应用到目标检测领域的开山之作。
RCNN在PASCAL VOC2012数据集上将检测率从35.1%提升至53.7%,使得CNN在目标检测领域成为常态,也使得大家开始探索CNN在其他计算机视觉领域的巨大潜力。同时,不得不提的是,该算法是二阶段目标检测算法。
作者给出的源码:RCNN
2. RCNN算法详解
2.1 初识RCNN网络结构
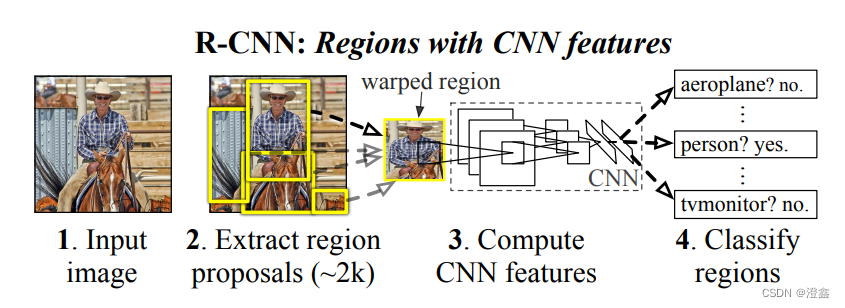
该图片源自于作者Ross Girshick提出的RCNN这篇论文中。从图中我们可以清晰的看到,输入的图片会先经过提取预选框(Region Proposals)的方法,从原图中获取了2000个这样的预选框,然后将包含目标的预选框送入CNN网络中进行特征提取,然后将获得的特征送入某个分类器中进行目标分类。
看到这里,相信大家一定会产生不少的疑问,当初的我也是这样,对于这些候选框的产生方式以及如何选取合适的包含目标的候选框送入CNN网络中训练,以及最终分类的方式等等,都会产生很大的疑问,接下去我们就逐步揭开RCNN这个目标检测算法的神秘面纱。
2.2 RCNN算法的训练过程
流程:输入图像——>候选框的生成——>将每一个候选框resize成227*227的尺寸(因为选择的特征提取网络是AlexNet)——>将其送入特征提取网络中——>训练每一类的SVM分类器对CNN的输出特征进行分类——>bbox的回归
2.2.1 Region proposals(候选框)的产生
Region proposals的生成方式有很多种,比如:
objectness
selective search
category-independen object proposals
constrained parametric min-cuts
multi-scale combinatorial grouping
Ciresan
其中,在RCNN中采用的方法是selective search方法。selective search方法的优势是又快,召回率又高,因此是最常用的区域产生的方法。selective search算法主要分为以下几个步骤:
step1:生成region proposals的区域集R(~2k)。
step2:计算区域集R里每个相邻区域的相似度S={s1,s2,…}。
step3:找出相似度最高的两个区域,将其合并成新集,添加进R。
step4:从S中移除所有与step3相关的子集。
step5:计算新集合与所有子集的相似度。
step6:循环操作,直至S为空,跳出循环。
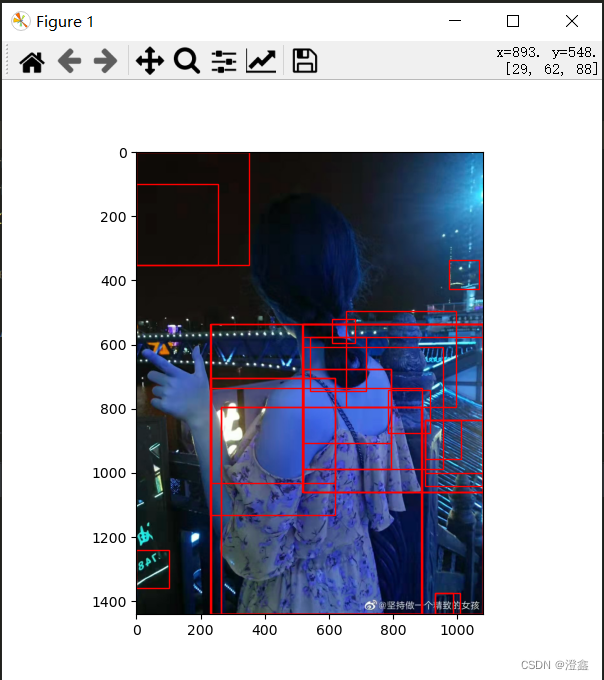
其中,step2中的计算区域之间相似的方法中,包括了计算区域之间的颜色距离,纹理距离等,综合各种距离之后,加权获得最终的区域之间的相似度。具体的实现可以在此博客中学习。下图为演示效果:
2.2.2 CNN卷积网络的选择与预训练
对于CNN特征提取网络,RCNN选择的是经典的AlexNet网络(或者VGG16),可以通过使用一个较大的开源数据集训练网络模型,例如ImageNet ILSVC2012, 然后会得到一个1000分类的一个预训练模型。
保存好这样的模型权重之后,我们可以通过迁移学习的方式来微调网络权重,来适应我们所需要的分类任务,即通过重新训练全连接层的方式来获得网络的泛化能力,即fit-tune技术的应用。
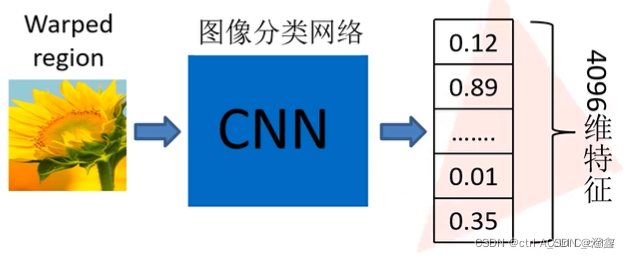
由于这里我们选择的是AlexNet网络,因此最后网络的输出层会将每一个输入的Warped region(即选择送入提取特征的候选区域图,这里需要将我们送入的每个候选框的图都resize到227*227的尺寸)以4096维度的特征向量的形式输出,对于产生2000个候选框而言,就会产生2000 * 4096维度的输出。
需要注意的是,利用ImageNet来预训练网络结构层是为了是网络获得识别的类别的能力,而不是bbox回归的能力。
此外,ImageNet中包含了1000类,而RCNN在VOC数据集上进行迁移学习时,所需要分的类别为21类(20个类别加背景一类,一共为21类)。
(图片来自)
RCNN将候选框的区域与Ground-truth中标签的box进行IOU的计算,如果IOU>0.5,说明候选款与标签框的重叠部分较多,可以视为正例(positive),反之则视为反例。
训练策略是采用SGD(随机梯度下降法),学习率为0.001,mini-batch为128。
2.2.3 提取并且保存RP的特征向量
经过2.2.2节中的网络训练之后,我们就可以调用保存的模型权重了,将候选区域输入,然后AlexNet的第七层会输出一个4096维度的特征矩阵,2000个候选区域就会输出2000个4096维度的特征矩阵。这些特征矩阵将被送到下一个环节中帮助我们识别目标并进行分类。
2.2.4 SVM对RP的内容进行分类
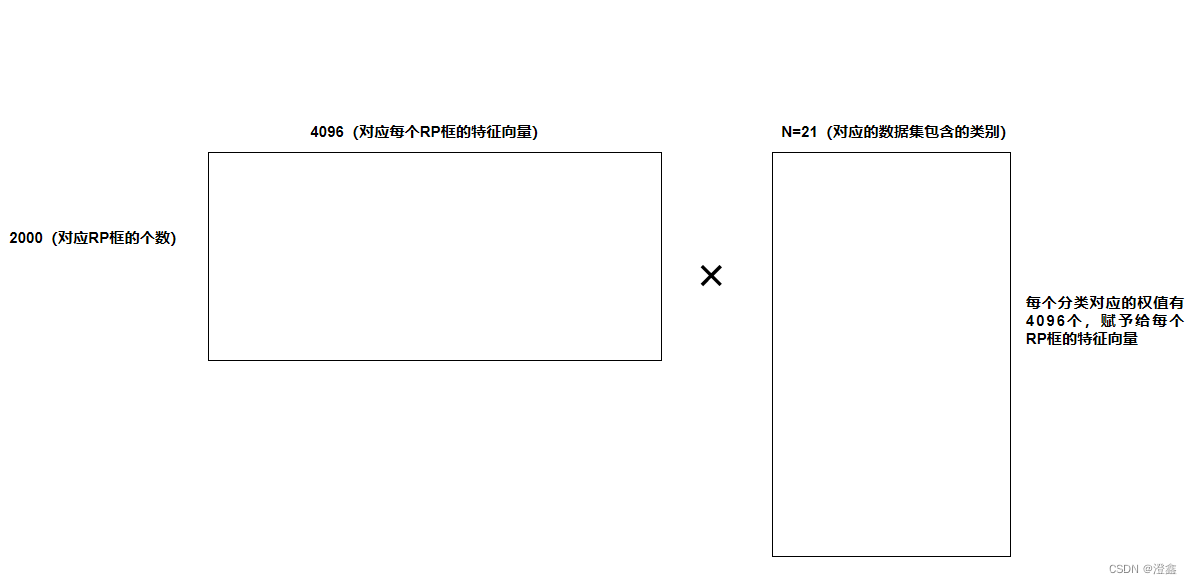
由2.2.3节我们能够得到2000*4096的一个特征矩阵(其中2000表示RP框的个数是2000,现实中不一定就是2000,4096代表每一个RP框的特征向量)。作者使用了SVM来进行分类。(选择SVM来分类的原因是,SVM支持小样本训练,在样本不平衡时依然不会发生过拟合)。
拿VOC数据集来举例,VOC数据集中除了20类目标分类,还有一类背景类别,所以一共是21类,因此我们需要训练21个SVM分类器,每一个分类器中都包含了4096个权值,赋予给每一个RP的特征向量:
在SVM的分类过程中,我们将IOU(PR框与标签框之间)低于0.3这个阈值的PR区域视为Negative,将IOU高于0.7这个阈值的PR区域视为positive,其余的全部丢弃。SVM会给出一个预测label,然后将这个label与true label比较,计算出loss,反向传播来调整每一个类别的权值。
作者使用了一种hard-negative mining的训练方法,该方法解决的问题就是提高SVM分类器的分类精确度。换句话说,在分类的开始,负样本往往是与正样本没有什么交集的,或者换句话说就是完全的负样本(也许这些负样本中根本没有一个能够包含目标或者部分包含的),因此经过这样的一番训练,我们的SVM分类器很有可能将很多接近正样本,但不是正样本的误判为正样本,此时讲这些误判的情况加入patch中,按照概率值排序后重新训练分类器,然后重复以上过程达到某种终止条件,即分类器的准确率达到某个阈值,停止训练。其实简单来说,hard-negative mining方法就是帮助我们的分类器找到那些容易分类错误的样本并且将其加入负样本中重复训练来增强我们分类器的能力。
2.2.5 预测框的回归
预测框回归与nms专栏
这一篇专栏写的十分的清晰,将预测框的平移与缩放的公式,以及训练时的loss都进行了列举。
















 2309
2309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











