







0.摘要
正畸治疗通常需要定期面对面检查以监测患者的牙齿状况。当面对面诊断不可行时,可以利用五张口内照片进行远程牙科监测。然而,它缺乏三维信息,如何从这些稀疏视角的照片中重建三维牙齿模型是一个具有挑战性的问题。
TeethDreamer是一种三维牙齿重建框架,旨在通过给定的五张口腔内照片重建上下牙齿的形状和位置。
在TeethDreamer中,首先利用大型扩散模型和先验知识生成具有已知姿态的新多视图图像以解决稀疏输入问题,然后通过神经表面重建技术重建高质量的三维牙齿模型。
为了确保生成视图之间的三维一致性,TeethDreamer在逆向扩散过程中集成了一个三维感知特征注意力机制。此外,还引入了几何感知法线损失到牙齿重建过程中, 以提高几何精度。大量实验表明,TeethDreamer模型优于当前最先进的技术,具有远程监测正畸治疗的潜力。
关键词:TeethDreamer 3D牙齿重建 扩散模型 神经表面重建
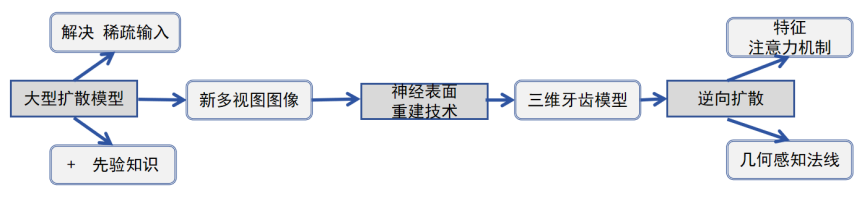
图1,用WPS PPT 制作
-
实验目的和背景介绍
1.1、临床背景:正畸治疗
正畸治疗主要针对牙齿错位,如咬合不正。这一过程通常需要较长时间,患者 需定期前往牙医处进行持续监测。
口腔内扫描(intra-oral scanning)获取高质量的3D牙科模型的方法通常耗时且成本高昂,而使用智能手机拍摄多张口内照片则提供了一种方便的替代方法。因此,从这些2D照片重建3D 牙科模型以实现远程监测成为一种有吸引力的研究方向。
1.2、传统方法的不足
传统 的多视图立体(MVS)方法和最近基于隐式神经表示的算法[22,23,8,2]在 三维视觉领域取得了令人印象深刻的结果。然而,这些方法都需要校准的相机 姿态以实现精确重建,在TeethDreamer的场景中这是不可行的。
此外,由于口腔内照片的稀疏性和小重叠,当前的结构从运动structure-from-motion(SfM)方法难以恢复准确的相机姿 态。最近在自然物体单图像3D重建方面的成功采用了预训练的扩散模型,从固定视角生成新的多视图图像来重建3D对象。
这些生 成方法通常依赖于单视图输入来生成更多图像,这导致了未见过区域的不准确重建。特别是它们大多生成没有正常信息的颜色图像,提供较差的几何信息。
1.3、TeethDreamer的意义
(1)采用预先训练的扩散模型,分割口腔内照片的牙齿图像,生成特定视点的彩色图像和相应的法线图;
(2)为确保不同视图之间的一致性,进一步从噪声彩色图像和法线图中构建 3D 感知特征,并在去噪过程中通过注意机制将其引入扩散模型;
(3)利用生成的彩色图像和法线图进行神经表面重建,重建三维牙齿模型。在重建过程中引入几何感知法向损失,提高了几何精度。
3D重建模型流程图:
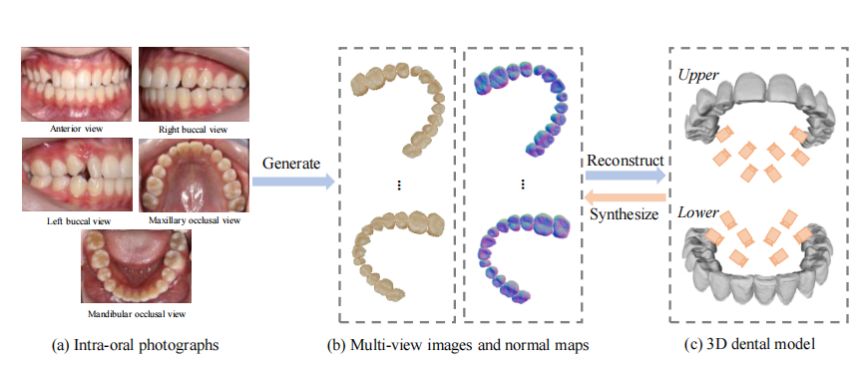
图2.来源于(Xu等, 2024)。首先,使用数据(a)(五张口内照片)集中的3D牙科模型合成多视角图像和法线图(b)。随后,训练扩散网络,直接从口腔内照片生成这些图像和法线图,最终重建目标3D牙科模型(c)。
2. 实验原理简述
2.1TeethDreamer的框架
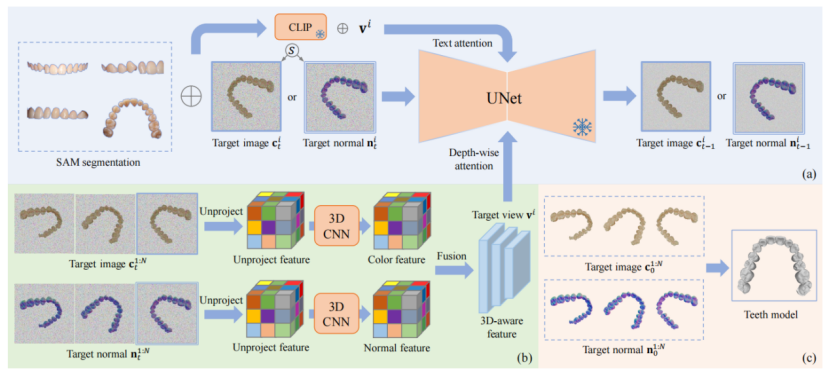
图2.TeethDreamer概览。
- 使用预训练的扩散模型,根据分割后的牙齿图像生成不同视 角的颜色图像和法线贴图。这里,扩散模型对目标视图进行一步去噪{cit,nit}。
- 从 潜在域中提取所有目标视图{c1:tN,n1:tN }的3D感知特征, 以确保生成视图之间的一 致性。
(c)从生成的颜色图像和法线贴图中进行几何感知的牙齿重建。
TeethDreamer是一种新的框架,仅通过五张口腔内照片重建3D牙齿模型。首先,TeethDreamer利用预训练的扩散模型,该模型由口腔内照片分割出的牙齿图像条件生成多视角彩色图像及相应的法线图。
这些新颖的视角帮助TeethDreamer缓解牙齿重建中输入数据的稀疏性。为了确保不同视角的一致性,我 们进一步从噪声彩色图像和法线图中构建3D感知特征,并在去噪过程中通过注意力机制将它们融入扩散模型中。
最后,TeethDreamer通过神经表面重建生成的颜色图像和法线图来重建3D牙齿模型,并在重建过程中引入了几何感知法线损失,以提高几何精度。
2.2模型原理
给定一组口腔内照片,TeethDreamer的目标是重建上下牙齿的高质量3D模型。TeethDreamer的重建框架分为两个阶段。
第一阶段,TeethDreamer训练一个扩散模型,生成多 视角一致图像和法线图,并结合一个3D感知特征注意力模块以强制多视角一致 性。
第二阶段,在生成的多视角图像和法线图的基础上,通过几何 感知神经隐式表面优化重建3D牙齿。
2.2.1 多视图跨域扩散模型
根据口腔内照片,TeethDreamer首先利用预训练的SAM模型对前景牙齿区域进行分割。请注意,在五张口腔内照片中,一个图像(即咬合视图)只包含上牙或下牙。如图2所示,TeethDreamer使用包含上牙的 四个分割图像作为模型输入,
记作x 1:4,x∈R3×H×W。
由于输入图像稀疏,很难重建高质量的3D牙齿模型。因此,TeethDreamer选择借助生 成扩散模型来增加观察视角。
除了RGB图像外,法线图是另一种重要的信号,用 于恢复3D模型。因此,TeethDreamer将分割后的牙齿图像x 1:4作为预训练扩散模型f的 输入条件,该模型来自Zero123 [11], 以在N个预定义的视角v 1:N生成彩色图 像c 1:N和法线图n 1:N,表示为:
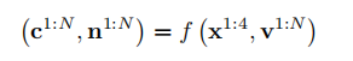
c和n的维度与x相同。请注意,真实颜色图像和法线图是根据口腔内扫描模型配 对预合成的,如图1所示。通过这种方式,TeethDreamer可以利用扩散先验的强大零样本 泛化能力。
此外,TeethDreamer还可以利用法线图中的丰富几何信息来提高牙齿重建的 准确性。
TeethDreamer的 目标是学习所有这些视图p θ(c1:N,n 1:N |x1:4) 的联合分 布,这可以数学地表述为多视图扩散模型。反向过程可以简单地从普通的DDPM [5]扩展如下。
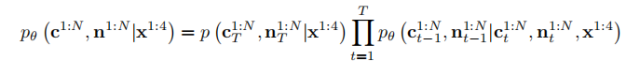
其中{c1:tN,n1:tN },t = 0,1 ,...,T是潜在变量。如图2(a)所示,TeethDreamer 将输入视图x1:4与带有噪声的目标视图{cit,nit}连接起来,i = 1 ,...,N 作为UNet的输入。此外,根据Zero123的方法,TeethDreamer还使用了稳定扩散中的注意力层来处理目标视点vi和输入视图x1:4的CLIP图像特征的连接。
然而,训练扩散模型同时生成彩色图像和法线图会影响预训练模型的性能, 因为输出通道数量存在差异。为了解决这一问题,TeethDreamer采用了一个域切换器∈R 1,它决定了输出类型,即彩色图像或法线图。总体而言,TeethDreamer训练了一个多视 图跨域扩散模型,并提出了等式的公式。1进行了如下修改。
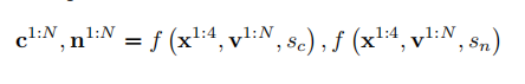
2.2.2 3D感知特征注意力
为了实现高质量的几何重建,保持图像和从不同视图生成的正常图像的一致性 至关重要。为此,TeethDreamer引入了一种方法,该方法结合了三维感知特征提取器和深度注意力机制。该策略在当前目标视图{cit,nit}的去噪过程中,整合了中 间状态{c 1: t N , n 1: t N}。
首先,生成的2D图像c1:tN和法线图n1:tN在潜在 空间中被反投影到预定义的643大小的3D体素网格上。然后,使用3D卷积神经网 络分别编码颜色和法线特征体积。接下来,3D U-Net将这些特征体积合并,确保输出在几何和外观上的一致性。为了提取特定于目标视图vi的特征,TeethDreamer创建了一个视图截面,并在生成的3D特征体积内进行插值。这些特定于视图的特 征随后通过深度注意力层整合到去噪过程中。这种方法有效地捕捉了不同视图 之间的空间关系,并整合了目标视图的重要信息,显著提高了生成视图之间的 一致性。
2.2.3 几何感知牙齿重建
由于口腔内照片缺乏相机参数,TeethDreamer仅依赖生成的颜色图像和预设视点的法线 图来进行牙齿表面重建,基于Neus。值得注意的是,TeethDreamer通过引入额 外的几何感知法线损失来增强这一过程。这使得TeethDreamer可以从二维法线图中提取 高质量的三维几何形状,同时减少噪声。
具体来说,TeethDreamer首先从生成的颜色图像c 1:N
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3256
3256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









