









深入理解FPGA加速原理——不是随便写个C代码去HLS一下就能加速的 - becomequantum的文章 - 知乎 https://zhuanlan.zhihu.com/p/149221232
对于片上内存这一项,FPGA则有着显著更高的计算容量,而片上内存在深度学习等应用中对于减少延时是至关重要的。大量的片上cache缓存减少了外部内存读取带来的内存瓶颈,也减少了高内存带宽解决方案所需要的功耗和成本。
要知道访问外部存储,比如读写DDR,是非常耗能的,可能数据在DDR和芯片之间跑来跑去的能耗比芯片本身做计算的能耗还要高。FPGA片上内存的大容量和灵活配置能力能减少对外部DDR的读写,这自然能缓解内存瓶颈,也就是减少延时并降低功耗。那FPGA具体是如何做到这点的呢?
啥叫实时呢?实时的意思就是我的运算速度和数据来的速度是一样的,不比它快,也不比它慢。快了也没用,数据都没来你也算不了。慢了就不能叫实时了。比如1920×1080×60帧的视频流,像素时钟频率约是150MHz,FPGA在对它进行处理的时候运算时钟频率就是150MHz,用的就是像素时钟。一个时钟周期来一个像素处理一个像素,来一行处理一行。
流水线的意思是,第一阶段的处理和第二阶段的处理不是第一全部完成了再第二,而是大部分重叠在一起的:
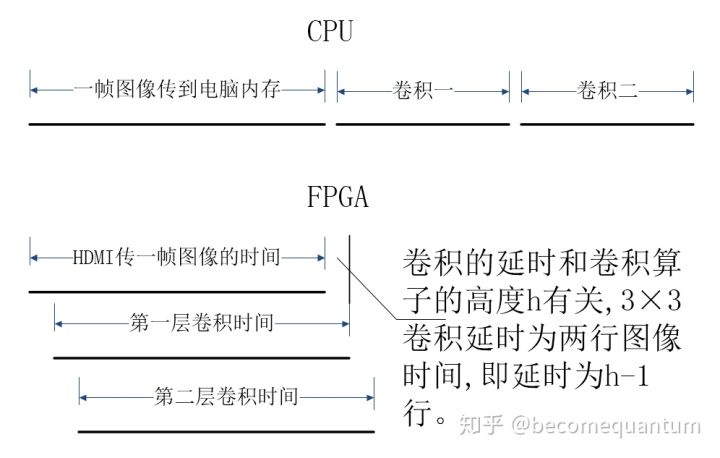
如上图所示,CPU做图像处理一般要等到一帧图像传到电脑内存之后才开始,如果要算两次卷积,那就只能先算第一个,再算第二个。
FPGA做运算就不是这样。首先FPGA能在图像一边从HDMI或传感器芯片传过来的时候一边就开始做处理。而CPU一般是等一帧图像传完了之后才开始处理的(嵌入式处理器能不能做到一边传一边处理我也不知道)。比如说每秒60帧的图像从传感器传出来一帧要1/60秒时间,CPU只能等着1/60秒完了之后才开始处理,而FPGA则是可以从图像开始传的0时刻开始,等图像1/60秒传完时也几乎处理完了,能达到最高的实时性。
如上图所示,CPU做一次卷积的时间是要小于FPGA的,但FPGA能充分利用图像正在传输的时间,还能并行流水线的进行第二次卷积,所以FPGA运算的延时最小,能达到最高的实时性。当然条件是把两次卷积并行起来需要两倍的运算单元,所以如果能够不惜代价的增加运算单元,也就是裸堆FPGA芯片,是可以把大量计算全都并行起来达到实时速度的。
最高效的计算方式应该是怎样的?
现在大家应该都知道了,计算的瓶颈往往不在于运算单元数量的不够或是速度不够高,而是在内存带宽上,也就是数据读写来不及,运算单元喂不饱。那最高效的计算方式自然就是能充分利用片上高速内存,让运算单元等待数据的情况从不发生,同时尽可能的减少了对外部DDR的读写,这也同时降低了功耗,所以既要速度快又要功耗低这两者其实并不矛盾。
为什么FPGA比GPU的能耗更低呢?上面讲的是原因之一,还有一个原因是FPGA是硬件可编程,所以它的数据通路是最直接的。比如说用FPGA算两个数相加,那直接把两个数从内存读进来送到加法器那去加就行了。但在GPU中还要进行指令译码,知道是做加法之后还要把这两个数往加法器那里送,这中间数据要经过一些选通器才会被正确的送到加法器那而不是别的运算单元那里。译码,数据经过选通,这些都会产生额外的功耗。而FPGA每次要做的运算都是固定的,所以不需要指令译码,也基本不需要数据的选通。
最高效的方式往往只有一种,低效的方式有无数种
两点之间直线最短,所以从A到B除非你会瞬间穿越,否则就是走直线这一条路径是最短的。而如果你想绕弯则可以有无数种绕法。同样的道理,进行一种运算的最高效方法在某种运算平台或框架下往往也只有一种。就拿3x3的图像卷积为例,怎样算才最高效呢?
3×3的卷积每次需要同时取三行图像中的三个像素值,也就是做第1行的卷积时需要取第0,1,2行的数据,第二行时需要取1,2,3行,再是2,3,4行。算了三行数据,就要读取9次行数据,那么在最低效的情况下,一副图片卷积完,图像数据实际上是要被读取三遍的。那要是5x5的卷积就是要读取5遍了。这个读内存的操作就太多了,自然会成为瓶颈。
那最高效的方法是什么呢?自然是只需要读取一遍图像就把不管3x3还是5x5的卷积都算完。实现的方法就是用片上内存把前h-1(h为算子高度)行的图像数据都缓存着,这样第h行数据来的时候就可以直接从片上内存中把前几行的数据读出来,不用都从外部DDR中读取。而能完美实现这种运算操作的就只有FPGA了,CPU Cache小,肯定是不行的。GPU行不行我不清楚,就算计算一层卷积GPU效率也可以很高,那要接着再算一层呢?
再回到上面那幅图,CPU算两次卷积是先读一次图像,算出结果存回去,算完一遍后再把刚才存的结果读出来进行第二遍计算。也就是说CPU在进行连续图像处理的时候必须把中间结果存回DDR去再读出来。GPU估计也得这样,但FPGA如果片上内存足则可以不这样。FPGA可以把第一层卷积的结果也缓存在片上内存中,然后流水线式的进行第二层卷积。以3×3的卷积为例,当第一层算到出第三行结果的时候,就可以和之前缓存的两行结果开始进行第二层卷积了。那么第二层卷积的第一行结果就能在原始数据读到第五行的时候出来,如下图所示:
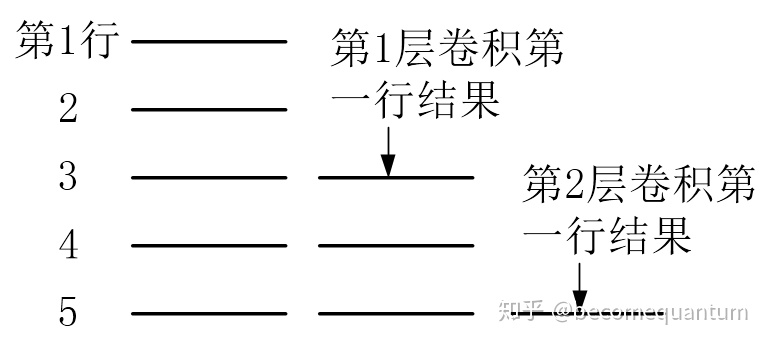
所以说如果FPGA片上内存和运算单元够足,数量也管够,它是可以实现图像只传输或读取一遍,就把好几层的卷积都算出来,中间结果和图像都无需再存到DDR中然后再读出来。既能实现最高的实时性,(16层3x3卷积只需延时32行,才十几分之一帧的时间),也能实现最小的能耗。

















 234
234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









