







最近在学习关于强化学习的相关知识,因此在此总结自己的心得体会。但由于小弟学识浅薄,内容难免存在错误,还望各路大神批评指正。
1、模型相关的强化学习
模型相关的强化学习是强化学习的一个分支,它需要我们完全知道问题背后的马尔科夫决策过程。
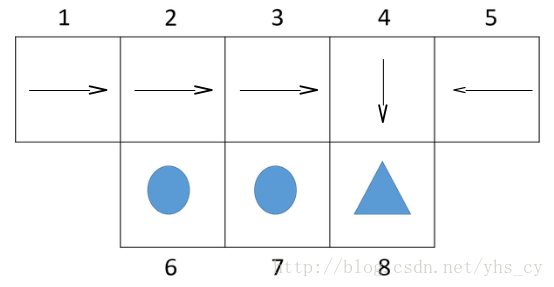
本节仍以机器人寻找三角形的例子进行相关概念的理解,如下图所示。
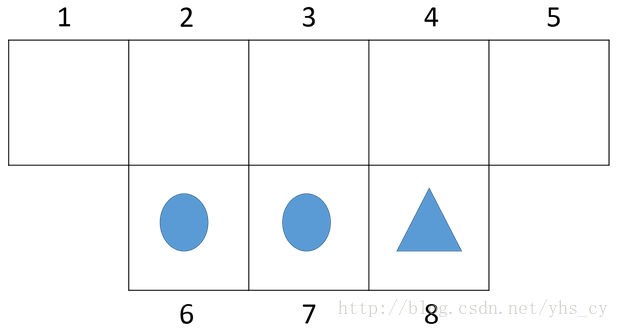
在该问题中,图中的不同位置为不同的状态,因此状态集合为
S={1,2,...,8}
,机器人在每个状态可采取的动作是向东南西北四个方向走,因此动作集合
A={′n′,′e′,′s′,′w′}
。状态转移的规则为:机器人碰到墙壁会停在原来的位置;奖励的设置,由于找到三角形则奖励1,找到圆形则损失1,其他均不奖励不惩罚。因此有
R2,s=−1
,
R3,s=−1
,
R4,s=1
,其余情况有
R∗,∗=0
。
模型相关的强化学习的学习算法主要有:策略迭代(Policy Iteration)和价值迭代(Value Iteration),下面分别介绍这两个算法。
2、策略迭代
策略迭代的思想如下:先随机初始化一个策略 π0 ,计算这个策略下每个状态的价值 v0 ;根据这些状态价值得到新的策略 π1 ,然后计算在新策略下每个状态的价值 v1 ,…,如下迭代直至状态价值收敛;其中在特定策略下计算每个状态的价值称为策略评估(Policy Evaluation);根据状态价值得到新的策略称为策略改进 (Policy Improvement)。
2.1、策略评估
策略评估主要是基于贝尔曼等式,如下式所示:
可以发现,状态的价值 v(s) 与其后续状态 s′ 的状态价值 v(s′) 有关,而由于状态 s 与状态
2.2、策略改进
根据状态价值得到新策略,被称为策略改进。对于一个状态
s
,让策略选择一个动作
由于在前面有定理已经证明是存在最优策略的,而该策略改进方法又可以保证 ∀s,vπt+1(s)≥vπt(s) ,因此策略改进可以获得最优策略。
2.3、策略迭代代码
# -*- coding:utf-8 -*-
from Mdp import Mdp
class Policy_Iteration:
# 初始化
def __init__(self, mdp):
# 保存状态价值
self.v = [0.0 for state in xrange(len(mdp.state)+1)]
# 策略保存
self.pi = dict()
for state in mdp.state:
if state in mdp.terminalstate:
continue
self.pi[state] = mdp.action[0] # 随机初始化策略
def __policy_evaluate(self, mdp):
max_iteration_num = 1000
for i in xrange(max_iteration_num):
delta = 0.0
for state in mdp.state:
if state in mdp.terminalstate:
continue
action = self.pi[state]
is_terminal, next_state, reward = mdp.transform(state, action)
value = reward + mdp.gamma * self.v[next_state]
delta += abs(value - self.v[state])
self.v[state] = value
if delta < 1e-6:
break
def __policy_imporve(self, mdp):
for state in mdp.state:
if state in mdp.terminalstate:
continue
a = mdp.action[0]
is_terminal, next_state, reward = mdp.transform(state, a)
value = reward + mdp.gamma * self.v[next_state]
for action in mdp.action:
is_terminal, next_state, reward = mdp.transform(state, action)
if value < reward + mdp.gamma * self.v[next_state]:
value = reward + mdp.gamma * self.v[next_state]
a = action
self.pi[state] = a
# 策略迭代方法
def policy_iteration(self, mdp):
max_iteration_num = 100
for i in xrange(max_iteration_num):
self.__policy_evaluate(mdp)
self.__policy_imporve(mdp)
if "__main__" == __name__:
mdp = Mdp()
policy_value = Policy_Iteration(mdp)
policy_value.policy_iteration(mdp)
print "value:"
for state in xrange(1, 6):
print "state:%d value:%f"%(state, policy_value.v[state])
print "policy:"
for state in xrange(1, 6):
print "state:%d policy:%s"%(state, policy_value.pi[state])策略迭代交替执行策略评估和策略改进直到收敛,从而得到最优策略了。下图是策略迭代在机器人找三角形问题中找到的最优解。
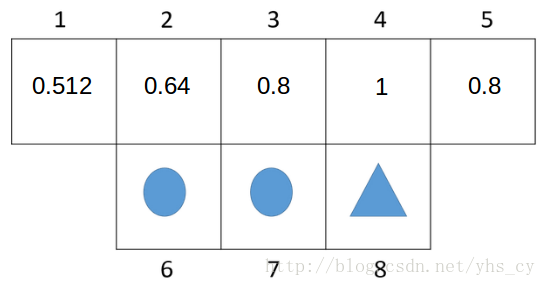
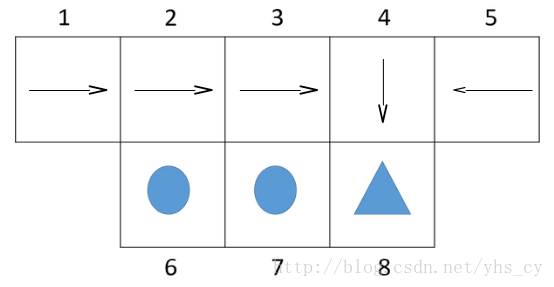
3、价值迭代
策略迭代需要反复执行策略评估和策略改进,其中策略改进部分其实就是根据贪婪原则选择最优的动作,问题主要在于策略评估需要反复迭代直至状态价值收敛。价值迭代则将策略评估和策略改进结合在同一个函数下,同时进行策略评估和策略改进。
3.1、价值迭代代码
# -*- coding:utf-8 -*-
from Mdp import Mdp
class Value_Iteration:
def __init__(self, mdp):
# 保存状态价值
self.v = [0.0 for state in xrange(len(mdp.state) + 1)]
# 保存策略
self.pi = dict()
for state in mdp.state:
if state in mdp.terminalstate:
continue
self.pi[state] = mdp.action[0] # 策略初始化
def value_iteration(self, mdp):
max_iteration_num = 1000
for i in xrange(max_iteration_num):
delta = 0.0
for state in mdp.state:
if state in mdp.terminalstate:
continue
a = mdp.action[0]
is_terminal, next_state, reward = mdp.transform(state, a)
value = reward + mdp.gamma * self.v[next_state]
for action in mdp.action:
is_terminal, next_state, reward = mdp.transform(state, action)
if value < reward + mdp.gamma * self.v[next_state]:
value = reward + mdp.gamma * self.v[next_state]
a = action
delta += abs(value - self.v[state])
self.v[state] = value
self.pi[state] = a
if delta < 1e-6:
break
if "__main__" == __name__:
mdp = Mdp()
policy_value = Value_Iteration(mdp)
policy_value.value_iteration(mdp)
print "value:"
for state in xrange(1, 6):
print "state:%d value:%f" % (state, policy_value.v[state])
print "policy:"
for state in xrange(1, 6):
print "state:%d policy:%s" % (state, policy_value.pi[state])在机器人寻找三角形的例子中的价值迭代代码执行结果如下图所示,证明价值迭代的结果与策略迭代的结果一致。
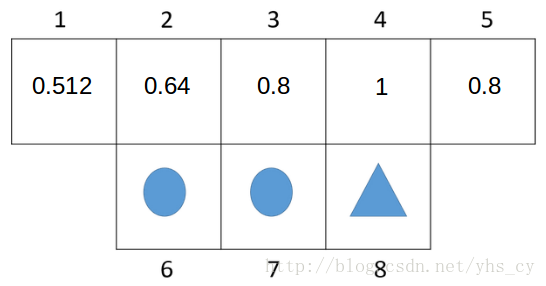















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









