







vector
vector 应该是最常用的容器了,vector 即动态数组, 与 string 类似,vector 成员物理上也是连续存放的,支持随机迭代器。
内存机制:

vector 可自动扩充内存, vector 自动扩容并不是每次超过扩充一个成员的内存,而是将容量扩充为原来容量大小的 2 倍,扩充后的容量为: vector.capacity() = vector.capacity() * 2。
同时, vector 在扩容时会开辟一块新的较大内存,再将原有的成员复制到新的内存块,这会带来较大的性能。
vector<int> vec;
for(int i = 1; i < 10; ++i)
{
vec.push_back(i);
cout << "vec.size: " << vec.size() << ", vec.capacity: " << vec.capacity() << endl;
}
由下图所知:vector扩容大小为 2 的倍数。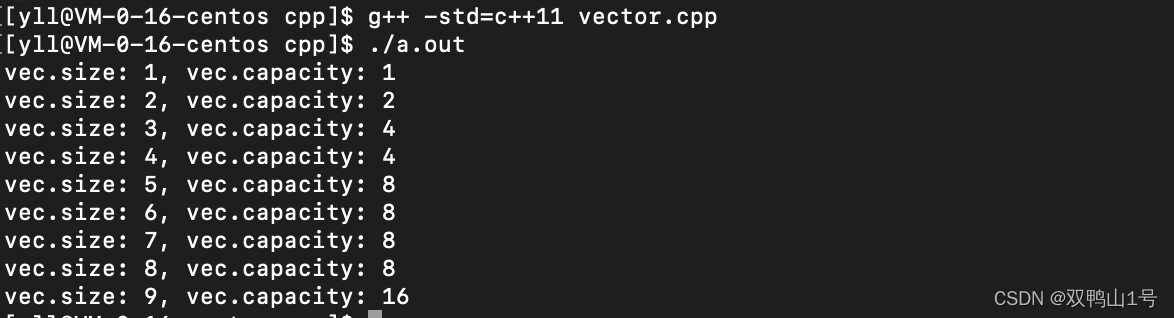
vector 常用 API
| 用法 | 解释 |
|---|---|
| reserve() | 当我们事先可以预估所需要存储的容量大小时可以首先调用 reserve() 预先分配内存,可以降低vector 扩容带来的性能损耗。 |
| data() | 获取指向元素本身的指针 |
| front()/back() | 返回 vector 中第一个/最后一个元素 |
| begin()/end() | 返回指向第一个元素/最后一个元素的后一内存单元的迭代器 |
| insert()/erase() | 可在 vector 任意位置插入/删除一个元素,参数:pos |
| push_back()/pop_back() | 插入一个元素在末尾/删除末尾元素 |
| emplace()/emplace_back() | 构造成员对象,并插入所需插入位置,参数:pos, Args |
| resize() | 重新分配内存大小,同样是按照 2 的倍数进行分配内存。 |
在使用 vector 常犯的错误就是没有考虑迭代器失效的问题。当我们删除元素节点时, 可能会触发底层的内存收缩操作,使得 vector 会另选一块较小的内存块,而先前使用的迭代器指向的内存块以及是原先分配的内存块,导致迭代器失效。如下例代码所示:
vector<int> vec {1, 2, 3};
cout << "size: " << vec.size() << " capacity: "<< vec.capacity() << endl;
for(vector<int>::iterator ite = vec.begin(); ite != vec.end(); )
{
// 1:错误版本
//vec.erase(ite);
//++ite;
//2: 正确使用方式,注意 for循环中不需要执行 ++ite,否则会导致越界问题,有兴趣可以试试
ite = vec.erase(ite);
}
cout << "size: " << vec.size() << " capacity: "<< vec.capacity() << endl;
使用第一种方法删除元素,导致迭代器失效,内存非法访问:

deque
deque 的意思就是 double - end queue,即双端队列。双端队列可以在队列的首端和未端任意的添加和删除元素。
deque 的接口与 vector 相比有以下不同:
deque 有 pop_front() 、push_front() 和 emplace_front() 接口用于在队列首端插入或删除元素;
deque 没有 data()、capacity() 和 reserve() 接口。
deque 内存布局并非完全连续,而是由固定大小的数组序列组成,一般如下:

list
list 即双向链表,内存布局不连续。可以以 o(1) 的复杂度在中间任意位置插入或删除元素节点,和 vector 相比, 无须大量移动元素节点。

list 较不同的接口如下:
merge():合并两个有序的 list,,示例如下:
std::list<int> list1 = { 5,10,2,4,3 };
std::list<int> list2 = { 9,7,2,3,5,4 };
list1.sort();
list2.sort();
list1.merge(list2);
splice(): 将元素从一个 list 转移到另一个 list,示例如下:
#include<iostream>
#include<list>
using namespace std;
ostream& operator<<(ostream& ost, list<int>& list)
{
for(auto & i : list)
{
ost << i <<" ";
}
return ost;
}
int main()
{
list<int> list1{1, 2 ,3, 4};
list<int> list2{5, 6, 7, 8};
cout << "list1: " << list1 << endl;
cout << "list2: " << list2 << endl;
//在 list1 的第一个位置迁移 list2 的前两个元素;
list1.splice(list1.begin(), list2, list2.begin(), ++++list2.begin());
cout << "after splice: " << endl;
cout << "list1: " << list1 << endl;
cout << "list2: " << list2 << endl;
return 0;
}
set / unordered_set
set 和 map 是关联性容器,关联容器实现了可快速搜索的排序数据结构(复杂度O(log n))。而 vector、list 、deque、array属于序列容器,实现了可以顺序访问的数据结构。
set 和 map 底层是由红黑树实现,红黑树是一种近似平衡二叉树,可以以 o(log n ) 的复杂度实现快速查找,元素间有序;
unordered_set 和 unordered_map 底层是由哈希表实现(空间换时间),可以以o(1) 的复杂度实现快速查找,但是元素间无序。
set 不能存放重复的 value 的节点,如果需要存放重复的 value 节点 ,可以使用 multiset 和 unordered_multiset。
set 常用 API
| begin() / end() | 返回指向第一个元素的迭代器 / 返回集合最后一个元素后面的元素的迭代器 |
|---|---|
| insert(value) /erase() | 在集合任意位置插入一个元素节点,如果集合中已经拥有该key值的节点,将会插入失败 |
| find(value) | 在集合中,查找对应的节点,并返回对应的迭代器 |
// insert
set<int> setInt{1, 3, 5, 4};
pair<set<int>::iterator, bool > result_1 = setInt.insert(1);
cout << * result_1.first << ", " << (result_1.second ? "insert successful." : "insert unsuccessful") << endl;
pair<set<int>::iterator, bool > result_2 = setInt.insert(2);
cout << * result_2.first << ", " << (result_2.second ? "insert successful." : "insert unsuccessful") << endl;

//set 有序, unordered_set 无序
set<int> setInt{2, 4, 5, 1, 3};
cout << "setInt output: ";
for(auto & i : setInt)
{
cout << i << " ";
}
cout << endl;
unordered_set<int> setInt2{2, 4, 5, 1, 3};
cout << "unordered_set output: ";
for(auto & i : setInt2)
{
cout << i << " ";
}
cout << endl;

multiset
cout << "multiset: ";
multiset<int> setMulti{1, 2, 1, 3, 5, 3};
for(auto & i : setMulti)
{
cout << i << ", ";
}
cout << endl;

map / unordered_map
map 的底层实现以及接口和 set 类似。但是 map 属于字典类型, 需要存放 <key, value> 的键值对。同时 map 支持下标访问:map[key] = value。
// map 常见用法
struct compare
{
bool operator()(const string& lhs, const string& rhs) const
{
return lhs.size() > rhs.size();
}
};
int main()
{
map<string, int, compare> Map{{"1", 1}, {"12", 2}, {"123", 3}};
for(auto & ref : Map)
{
cout << " first: " << ref.first << " second: " << ref.second << endl;
}
//查找
auto ite = Map.find("1");
if(ite != Map.end())
{
cout << "first: " << ite->first << " second: " << ite->second << endl;
}
return 0;
}
unordered_map 用法,自定义哈希函数:
struct Hash
{
size_t operator()(const pair<int, int> & key) const
{
size_t h1 = std::hash<int> {}(key.first);
size_t h2 = std::hash<int> {}(key.second);
return h1 ^ (h2 << 1); // or use boost::hash_combine
}
};
int main()
{
unordered_map<pair<int, int>, int, Hash> Map{{make_pair(1, 2), 1},
{make_pair(1, 3), 1}, {make_pair(1, 4), 1}};
for(auto & ite : Map)
{
cout << "key.first: " << ite.first.first << ", key.second: "
<< ite.first.second << ", value: " << ite.second << endl;
}
return 0;
}


















 1322
1322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









