







Challenge:
之前的研究都是在假设模型总是可以访问两个无错误传感器输入的情况下,MVDNet多模态输入模型其中一个传感器不可用或丢失,模型可能会寄。
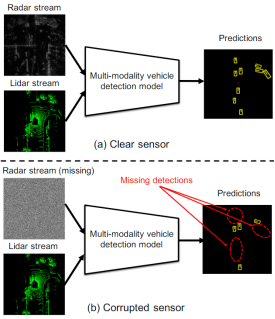
而直接屏蔽一个输入流的强数据增强,将使模型依赖于一个清晰的蒸汽而忽略缺失的流,直接随机缺失传感器训练的模型不能有效地融合两个传感器的两个特征。模型学习更多的是每个模态单独工作,以便即使缺少一个传感器,它也能够生成预测。
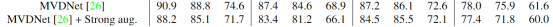
Contribution:
1.提出了一个基于 Mean Teacher 的框架,利用强传感器缺失数据增强来解决缺失传感器的问题。
2.开发的模型不仅能够处理噪声/缺失传感器,而且能够在多个实验设置的ORR数据集上大大优于现有的最先进的(5%)。
Method:
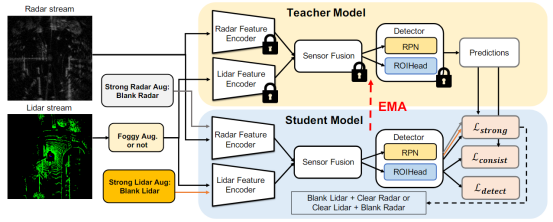
学生模型接受激光雷达数据雾化增强、强缺失雷达增强和强缺失激光雷达增强,使用Mean teachers,定义一致性损失与强增强损失知识蒸馏学习,使一个缺失传感器的学生模型获得与清晰传感器教师模型一致的输出。
Lconsist
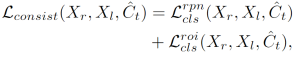
(没有对边界框回归应用损失,不太懂?)
使用教师模型对学生模型进行正则化。
Lstrong
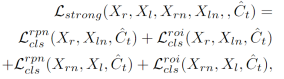
n表示缺失的传感器输入
通过强制学生单一清晰模态的预测结果靠近两种清晰模态教师的预测结果,训练模型从缺失的模态中恢复特征以生成更好的检测,而不是学习模态之间独立预测。
Experiments:
直接性能比较,未缺失的情况下很大一部分性能应该来自于Self-training提高的泛化能力。
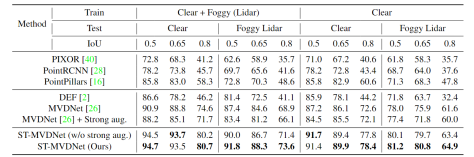
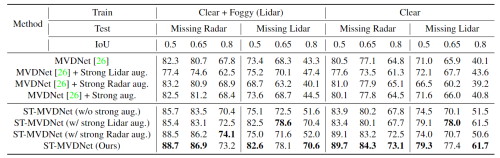
缺失传感器数据性能比较
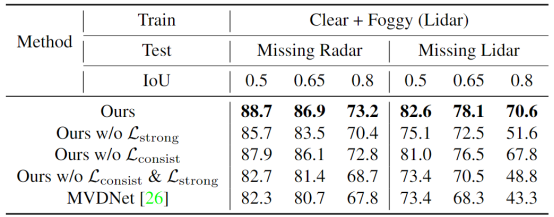
模块消融:Lstrong的性能提升最大,Lconsist作为正则化有略微提升(本身也缺少回归loss)。

















 3195
3195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









