










23年6月份科大和腾讯发表的综述论文“A Survey on Multimodal Large Language Models“。
多模态大语言模型(MLLM)最近成为一个新的研究热点,通过强大的大语言模型(LLM)作为大脑来执行多模态任务。MLLM令人惊讶的涌现能力,例如基于图像的编写故事和无OCR的数学推理,在传统方法中很少见,表明这是一条通往人工通用智能(AGI)的潜在途径。本文旨在追踪和总结MLLM的最新进展。首先,提出MLLM的表述并描述其相关概念。然后,讨论关键技术和应用,包括多模态指令调优(M-IT),多模态上下文学习(M-ICL),多模态思维链(M-CoT)和LLM辅助视觉推理(LAVR)。最后,讨论现有的挑战,并指出有前途的研究方向。
从发展通用人工智能(AGI)的角度来看,MLLM可能在LLM向前迈出一步,原因如下:(1)MLLM更符合人类感知世界的方式。人类自然会接受多感官输入,这些输入通常是互补和合作的。因此,多模态信息有望使MLLM更加智能。(2) MLLM 提供更加用户友好的界面。得益于多模态输入的支持,用户可以更灵活地与智能助手进行交互和通信。(3)MLLM是一个更全面的任务解决者。虽然LLM通常可以执行NLP任务,但MLLM通常可以支持更广泛的任务。
多模态指令调优(M-IT)
指令是指任务的描述。指令调优是一种在一组指令格式数据集上微调预训练LLM的技术【16】。以这种方式调优,遵循新指令的LLM 可以泛化到未见过的任务,从而提高零样本性能。这个简单而有效的想法引发NLP领域后续工作的成功,如ChatGPT [1],InstructGPT [17],FLAN [16,18]和OPT-IML [19]。
指令调优与相关典型的学习范式之间比较如图所示:(a)预训练-微调;(b)提示;(c)指令微调。监督微调方法通常需要许多特定任务的数据来训练特定任务的模型。提示方法减少对大规模数据的依赖,并且可以通过提示工程来完成专门的任务。在这种情况下,尽管少样本学习的性能有所改善,但零样本性能仍然相当平均[5]。不同的是,指令调优学习如何泛化到未见的任务,而不是像两个同行那样拟合特定任务。此外,指令调优与多任务提示高度相关[20]。

多模态指令调优 (M-IT)技术 的分类如图所示,其包括数据构建、模态桥接和评估三部分。
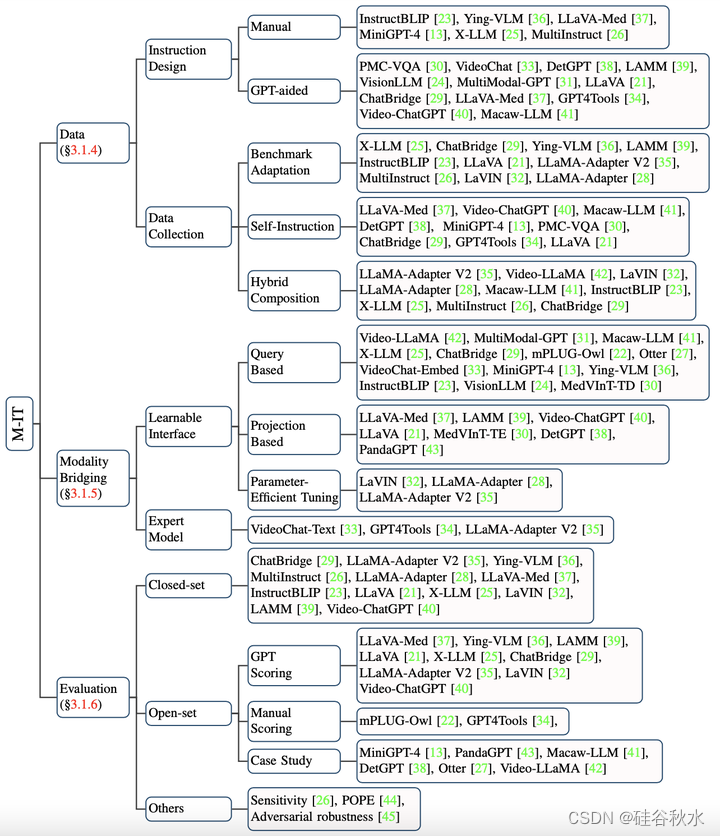
多模态指令听从数据的收集是M-IT的关键。收集方法大致可分为基准的适应、自我-指令[60]和混合组合。
由于LLM只能感知文本,因此弥合自然语言与其他模态之间的差距是必要的。但是,以端到端的方式训练大型多模态模型的成本很高。此外,这样做会带来“灾难性遗忘”的风险[61]。因此,更实用的方法是在预训练的视觉编码器和LLM之间引入一个可学习的接口。另一种方法是在专家模型的帮助下将图像翻译成语言,然后将语言发送给LLM。
评估M-IT后的模型性能,其指标多种多样,根据问题类型大致可分为闭集和开集两种。
多模态上下文学习(M-ICL)
ICL是LLM的重要新能力之一。ICL有两个优点:(1)不同于从大量数据中学习隐性模式的传统监督学习范式,ICL的关键是从类比中学习[74]。具体来说,在ICL环境中,LLM用可选的指令从几个例子中学习,推断出新问题,从而以少样本的方式解决复杂和未见的任务[14,75,76]。(2)ICL通常以无训练的方式实现[74],因此可以在推理阶段灵活地集成到不同的框架中。与ICL密切相关的技术是指令调整,经验证明这可以增强ICL能力[16]。
在MLLM的背景下,ICL已扩展到更多模态,即多模态ICL(M-ICL)。在推理时,M-ICL可以向原始样本添加一个演示集(即一组上下文样本)。
在多模态应用方面,M-ICL主要用于两种场景:(1)解决各种视觉推理任务[14,27,63,78,79];(2)教LLM使用外部工具[75,76,80]。前者通常涉及从一些特定任务的例子中学习,并泛化到一个新但类似的问题。从指令和演示中提供的信息中,LLM可以了解任务正在做什么以及输出模板是什么,并最终生成预期的答案。相比之下,工具使用示例通常是纯文本的,并且提供更细粒度的说明。这通常由一系列步骤组成,可以按顺序执行完成任务。因此,第二种情况与CoT密切相关。
多模态思维链(M-CoT)
正如工作[7]所指出的那样,CoT是“一系列中间推理步骤”,证明在复杂推理任务中是有效的[7,87,88]。CoT的主要思想是提示LLM不仅输出最终答案,而且是答案的推理过程,类似于人类的认知过程。
受到NLP成功的启发,已经提出多项工作[81,82,85,86]将单模态CoT扩展到多模态CoT(M-CoT)。总结这些工作如图所示。
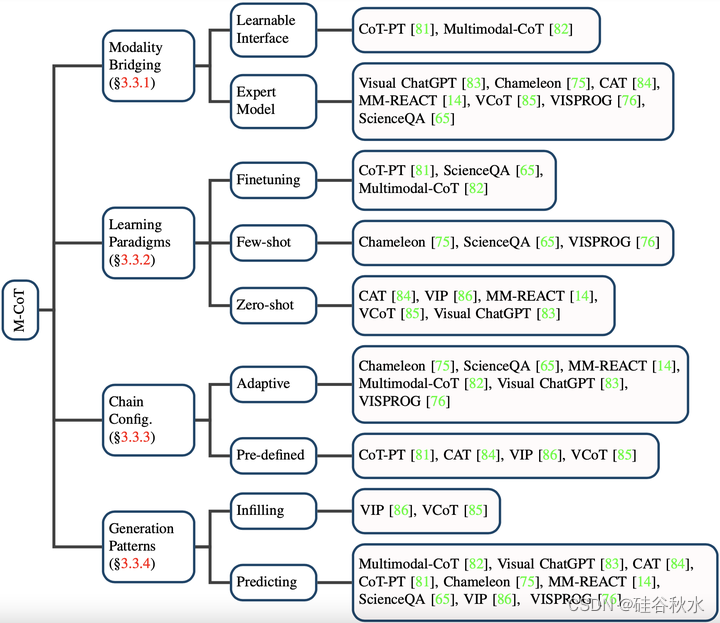
1)M-IT情况类似的模态差距。2)获取M-CoT能力的不同范式。3)M-CoT的更多具体方面,包括配置和链的形成。
LLM辅助视觉推理(LAVR)
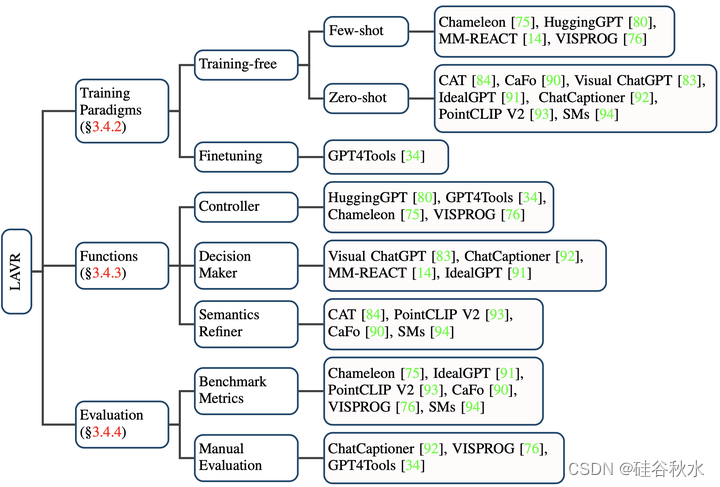
受到工具-增强LLM的成功[95-98]启发,一些研究探索了调用外部工具[14,34,75,76]或视觉基础模型[14,83,84,91,92,99]进行视觉推理任务的可能性。这些工作以LLM作为具有不同角色的助手,构建特定任务的[84,90,93]或通用[14,75,76,80,83]视觉推理系统。
与传统的视觉推理模式[100-102]相比,这些工作表现出几个优点:(1)较强的泛化能力。这些系统配备从大规模预训练中学到的丰富开放世界知识,可以轻松地推广到未见的目标或概念,具有零/少样本性能[75,76,90,91,93,94]。(2)涌现能力。借助强大的推理能力和丰富的LLM知识,这些系统能够执行复杂的任务。(3)更好的交互性和控制性。传统模型通常允许一组有限的控制机制,并且通常需要昂贵的筛选数据集[103,104]。相比之下,基于LLM的系统能够在用户友好的界面(例如点击和自然语言查询)中进行精细控制[84]。
如图所示:1)LLM辅助视觉推理系统构建中使用的不同训练范式;2)LLM在这些系统中发挥的主要作用;3)各种类型的性能评估方法。















 1576
1576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









