 大语言模型与向量数据库:融合与挑战,
大语言模型与向量数据库:融合与挑战,







24年2月来自CMU、普度大学、密西根大学等的综述论文“When Large Language Models Meet Vector Databases: A Survey”。
本综述探讨大语言模型 (LLM) 和向量数据库 (VecDB) 的协同潜力,这是一个新兴但发展迅速的研究领域。LLM 的激增带来了一系列挑战,包括幻觉、过时的知识、过高的商业应用成本和内存问题。VecDB 成为这些问题的有力解决方案,它提供了一种有效的方法来存储、检索和管理 LLM 操作固有的高维向量表示。本文描述LLM 和 VecDB 的基本原理,并批判性地分析二者的集成对增强 LLM 功能的影响。还有对该领域未来发展的推测讨论。
LLM存在的一些问题包括:
一个LLM的主要缺点是幻觉问题,即 LLM 生成的信息看似合理但事实上不正确或完全无意义 [Huang et al., 2023]。这背后有许多潜在原因。首先,LLM 缺乏领域知识。LLM 主要在公共数据集上进行训练 [Penedo et al., 2023],这一事实不可避免地导致其回答超出其内部知识范围特定域问题的能力有限。此外,实时知识更新对 LLM 来说具有挑战性。即使问题在 LLM 的学习语料库中,它们的答案仍可能表现出局限性,因为当外部世界动态变化时,内部知识可能会过时 [Onoe et al., 2022]。最后,LLM 被发现存在偏见。用于训练 LLM 的数据集很大,这可能会引入系统错误 [Bender et al., 2021]。本质上,每个数据集都可能存在偏见问题,包括模仿性谎言 [Lin et al., 2022]、重复偏见 [Lee et al., 2022] 和社会偏见 [Narayanan Venkit et al., 2023]。
将 LLM 应用于商业的另一个缺点是成本昂贵 [Schwartz et al., 2020]。对于一般的商业实体来说,将 LLM 用于商业用途几乎不可行。非科技公司几乎不可能定制和训练自己的 GPT 模型,因为没有资源和人才来开展如此大的项目 [Musser, 2023],而频繁调用 OpenAI 等第三方 LLM 提供商的 API 成本极高,更不用说某些领域此类提供商的数量非常有限。
LLM 的遗忘问题一直存在争议,因为人们发现 LLM 倾向于忘记以前输入的信息。研究表明,LLM 也表现出灾难性遗忘的行为 [Luo et al., 2023],就像神经网络一样 [Kemker et al., 2017]。
专门为 AI 构建的数据库,支持向量数据存储及其大规模高效检索,也称为 VecDB。通过 VecDB 和 LLM 的有效组合,VecDB 可以作为外部知识库,具有高效的检索功能,为 LLM 提供领域特定知识,也可以作为 LLM 的内存,为每个用户的对话框选项卡保存以前相关的聊天内容,或者作为语义缓存,上述 LLM 的问题可以无缝解决。
LLM面临的挑战可列如下:
模型编辑涉及将更灵活的架构集成到模型中,从而实现有针对性的更新或编辑,而无需完全重新训练。这带来了一个复杂的挑战:模型某一部分的更改可能会意外地影响其他区域。确保这些更新既不会降低性能也不会引入偏见是一项艰巨的任务。模型编辑还包括个性、情感、观点和信仰等元素。虽然这些方面已经引起了一些关注,但它们在很大程度上仍然是未开发的领域 [Yao et al., 2023]。道德问题,包括数据偏见 [Raffel et al., 2020]、隐私问题 [Li et al., 2023a] 和生成内容的潜在滥用 [Ganguli et al., 2022],是模型编辑中的重大挑战。
LLM 中的幻觉 [Ji et al., 2023] 构成了重大挑战,破坏了其输出的可靠性。
训练和运行 LLM 所需的大量计算资源引发了环境和可访问性问题 [Strubell, 2019],与可持续 AI 的原则相矛盾 [Wu & Raghavendra, 2022]。LLM 及其训练数据集的不断扩大显著影响了训练和推理成本。这些技术对环境的影响是巨大的,在模型训练和调整过程中会产生大量的温室气体排放和能源消耗 [Kaack, 2022]。这种情况需要针对AI对环境的影响进行严格评估,鼓励开发更节能的模型并采用绿色计算实践 [Wynsberghe,2021]。
过渡到 VecDB 可能会全面应对这些挑战。VecDB 具有高效的数据结构和检索功能,为增强模型编辑灵活性、通过改善特定域的反应来减少幻觉以及优化计算资源利用率,提供了一种有希望的解决方案,从而更紧密地符合可持续AI的原则。
VecDB 是唯一天然支持多种非结构化数据并能高效存储、索引和检索的数据库。由于云端各种应用的蓬勃发展,各种数据源以多种格式存在于不同位置。与需要结构化或半结构化数据(必须传达一些限制和格式)的传统数据库不同,VecDB 专门存储实际应用中各种非结构化数据的深度学习嵌入。另一方面,与在数据库中搜索精确值的传统 DBMS 不同,VecDB 中的向量语义特征需要对向量进行近似搜索,即在高维基向量数据空间中搜索近似的 top-k 个最近邻,而这些邻居不一定需要精确匹配,表示 top-k 个语义上接近的数据。
由于非结构化基础数据嵌入到高维向量中,计算给定查询向量数据的 k 个最近邻可能非常昂贵,因为它需要计算与数据集中每个点的距离并维护前 k 个结果。这样的操作将导致时间复杂度为 O(dN + N log k),其中 d 是维数,N 是向量数量,使用成对距离计算和堆来保存前 k 个结果以穷举搜索前 k 个结果。
向量索引可以在满足精度情况下,提高搜索和存储的效率。针对 VDBMS 中的 ANN 搜索优化包括几种:基于树的 [Muja & Lowe, 2009; Tao et al., 2009]、基于哈希的 [Andoni & Indyk, 2008]、积量化 (PQ) [Je ́gou et al., 2011] 和基于图的方法 [Malkov and Yashunin, 2018]。
由于 LLM 使用嵌入将文本表示为向量,开发人员是否可以结合 VecDB 和 LLM 来克服 LLM 应用程序中继承的上述挑战?答案是肯定的。
随着LLM和VecDB这两个领域近年来的快速发展,利用两者结合的应用也在迅速增长,其中最富有成果的是检索增强生成 (RAG),其中 VecDB 在实现经济高效的数据存储和高效检索方面发挥着至关重要的作用。
RAG 的概念被设计为一种范例,如图说明了 RAG 的常见工作流程。系统的完整运行基本上有三个主要部分:数据存储、检索和生成。RAG解决了 LLM 在集成和处理外部数据库中的大量动态数据时面临的挑战,其中 VecDB 充当 LLM 的外部存储器。它们允许将私有数据转换为向量并有效存储这些向量以进行快速检索,从而实现私有数据的分割。与 VecDB 集成,使 LLM 能够访问和合成大量数据,而无需不断重新训练,从而克服了其固有的局限性。
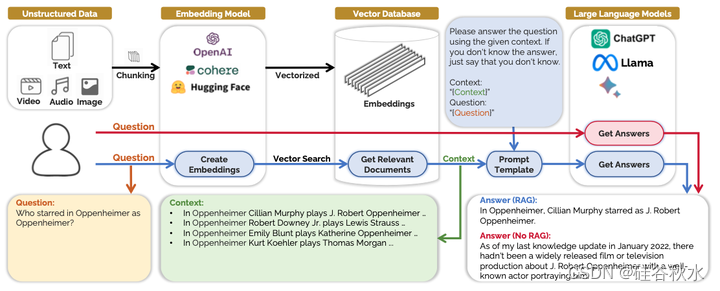
VecDB作为外部存储器,从数据预处理开始,在此过程中收集、清理、集成、转换、规范化和标准化原始数据。由于 LLM 的上下文限制,处理后的数据被分块成更小的段。然后,这些数据段由嵌入模型转换为向量,即数据的语义表示,存储在 VecDB 中,并将在后续步骤中用于向量搜索。
一个完善的 VecDB 将正确地索引数据并优化检索过程。检索部分从用户以提示的形式向相同的嵌入模型提出问题开始,该模型生成了存储数据的向量表示并获得问题的向量嵌入。该过程的下一步是在 VecDB 内部进行向量搜索和评分,这主要涉及计算向量之间的相似度得分,然后数据库识别并检索与查询向量相比相似度得分最高的数据段(在大多数 RAG 系统中为前 K 个)。然后将这些检索到的段从其向量格式转换回其原始形式,通常是文档的文本。
在生成部分,LLM 参与生成最终答案。检索到的文档连同用户的问题一起被合并到专门选择和设计的提示模板中。此模板选择基于任务类型,旨在有效地将上下文与问题合并以形成连贯的提示。选定的 LLM 将提供提示并生成最终答案。
VecDBs 和 LLM 的结合不仅促进 LLM 与 RAG 的深度应用,还为成本效益的端到端 LLM 应用提供了新的前沿。
高昂的 API 成本。基于 LLM 的聊天机器人和智体系统严重依赖 API 供应商的 LLM 输出;重复的或类似的查询可能会导致高昂的 API 成本。
API 带宽限制。此类聊天机器人和智体系统还可能遇到突发查询工作负载,几秒钟内爆发性的 API 调用可能会淹没系统带宽,导致系统中断和重新配置。
将 VecDB 与 LLM 集成的主要好处之一是显著降低数据运营成本 [Sanca & Ailamaki,2023]。例如,GPT-Cache [Bang,2023] 是一个用作语义缓存的 VecDB。如图所示:它存储对先前查询的响应,并在调用 LLM API 之前用作缓存。这种缓存机制意味着系统不需要每次都进行 API 调用来等待从头开始生成的响应,从而减少了对 LLM 的昂贵 API 调用次数。此外,这种方法还可以加快响应时间,增强用户体验。
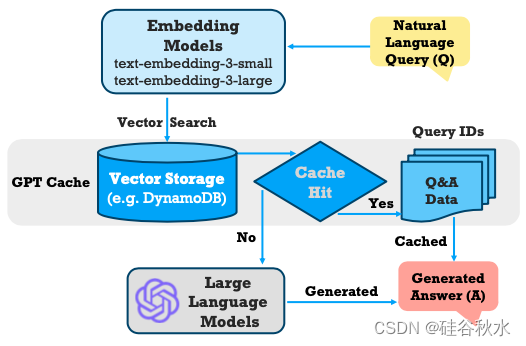
VecDB 通过索引大量以前的问答数据并将其映射到向量空间,增强了 LLM 检索和利用相关信息的能力。与计算机系统中需要精确哈希匹配的缓存不同,这允许将查询与现有知识进行更精确的语义匹配,并且不仅基于 LLM 的训练数据生成响应,而且还由 VecDB 中可用的最相关和最新信息来告知。
在使用 Chat-GPT 等 LLM 问答应用程序时,LLM 很可能会完全忘记之前对话的内容和信息,即使在同一个聊天选项卡中也是如此。
VecDB 充当强大的记忆层 [Zhang et al., 2023b],解决了 LLM 的固有局限性之一:知识的静态性。虽然 LLM 擅长根据训练期间学习到的模式生成类似人类的文本,但它们无法固有地动态更新其知识库,因此可能缺乏少样本学习能力。VecDB 通过提供可以不断更新新信息的存储解决方案来弥补这一差距,确保 LLM 的响应基于最新和最相关的可用数据。
VecDB 和 LLM 的组合带来了协同作用,其中 LLM 为用户查询提供上下文和理解,而 VecDB 提供了一种精确的机制来存储和检索相关向量。这种协作方法可以更准确、更相关、更有效地响应复杂查询,这对于任何一个系统来说都很难独立解决。
与 LLM 集成的 VecDB 有助于实时学习和适应。随着新数据被输入 VecDB,LLM 可以立即利用这个更新的存储库来优化其响应。此功能对于需要最新准确性的应用程序(例如财务分析、新闻传播和个性化推荐)至关重要。
RAG 现已发展到能够通过借助多模态模型处理各种数据类型。LLM 的令人瞩目的成就激发了视觉-语言研究的重大进步。OpenAI 的 DALL-E 引入了一种基于 Transformer 将文本转换为图像的方法,将图像视为离散tokens序列。随后,通过模型规模化、预训练和增强的图像量化模型等方法,文本-到-图像领域的改进 [Zhang et al., 2023a] 得以实现。
为了更好地利用来自各种类型数据的知识,kNN-LM [Khandelwal et al., 2020] 探索了如何将NN搜索纳入语言模型,通过有效利用记忆示例来增强其泛化能力。一项结合知识图谱和 LLM 的工作是 RET-LLM [Modarressi et al., 2023],旨在为 LLM 配备通用的读写存储单元。这些研究主要关注检索粒度和数据结构化级别,粗粒度提供的信息较多,但准确性较低。相反,结构化文本检索以牺牲效率为代价提供详细信息。
为了利用内部知识和外部资源,SKR [Yu et al., 2023] 使 LLM 能够评估他们所知道的内容并确定何时寻求外部信息,可以更有效地回答问题来提高其能力。FLARE [Jiang et al., 2023] 用即将出现句子的预测来估计未来内容并检索相关文档以重新生成句子,尤其是当它们包含低置信度tokens时。
未来挑战和工作方向:
向量搜索方法。
多模态数据库管理系统。
数据预处理:文本嵌入和降维。
具有多租户的 LLM 数据管理系统。
经济高效且可扩展的数据存储和检索。
知识冲突。

















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









