










24年1月来自新加坡技术设计大学的论文“TinyLlama: An Open-Source Small Language Model”。

TinyLlama,是一个紧凑的 1.1B 语言模型,在约 1 万亿个tokens上进行了约 3 个epochs的预训练。TinyLlama 以 Llama 2(Touvron,2023b)的架构和token化器为基础,利用开源社区贡献的各种技术(例如 FlashAttention(Dao,2023)),实现了更好的计算效率。模型检查点和代码在 GitHub 上公开提供,网址为 https://github.com/jzhang38/TinyLlama。
预训练 TinyLlama
预训练数据
主要目标是使预训练过程有效且可重复。采用自然语言数据和代码数据混合来预训练 TinyLlama,从 SlimPajama (Soboleva,2023) 获取自然语言数据,从 Starcoderdata (Li,2023) 获取代码数据。采用 Llama 的token化器 (Touvron,2023a) 来处理数据。
SlimPajama 是一个基于 RedPajama (Together Computer,2023) 为训练语言模型而创建的大型开源语料库。原始 RedPajama 语料库是一项开源研究工作,旨在重现包含超过 1.2 万亿个tokens的 Llama 预训练数据(Touvron,2023a)。SlimPajama 清理和去重原始 RedPajama 而得出。
Starcoderdata 收集此数据集是为了训练 StarCoder(Li,2023),一个强大的开源大型代码语言模型。它包含 86 种编程语言中的约 2500 亿个tokens。除了代码之外,它还包括 GitHub 问题和涉及自然语言的文本-代码对。为了避免数据重复,删除了 SlimPajama 的 GitHub 子集,只从 Starcoderdata 中抽样代码数据。
将这两个语料库合并后,总共有大约 9500 亿个tokens用于预训练。正如 (Muennighoff 2023)所观察的,TinyLlama 在这些tokens上进行了大约三个epochs的训练。 与用唯一数据相比,对重复最多四个epochs的数据进行训练可最大程度地降低性能下降。在训练期间,对自然语言数据进行采样,使自然语言数据和代码数据之间的比例达到约 7:3。
架构
采用与 Llama 2 (Touvron,2023b) 类似的模型架构。用基于 (Vaswani 2017) 的 Transformer 架构,其细节如下:

位置嵌入。用 RoPE (Su,2021) 将位置信息注入模型。RoPE 是一种广泛采用的方法,最近被许多主流大语言模型使用,例如 PaLM (Anil,2023)、Llama (Touvron,2023a) 和 Qwen (Bai,2023)。
RMSNorm。在预规范化中,为了获得更稳定的训练,在每个 Transformer 子层之前对输入进行规范化。此外,应用 RMSNorm (Zhang & Sennrich,2019) 作为规范化技术,这可以提高训练效率。
SwiGLU。 不用传统的 ReLU 非线性,而是遵循 Llama 2,将 Swish 和GLU结合在一起,称为 SwiGLU (Shazeer, 2020),作为 TinyLlama 中的激活函数。
分组查询注意。为了减少内存带宽开销并加快推理速度,在模型中使用GQA(Ainslie et al., 2023)。有 32 个用于查询注意的头,并使用 4 组K-V头。使用这种技术,模型可以在多个头之间共享K和V表示,而不会牺牲太多性能。
速度优化
完全分片数据并行 (FSDP) 。在训练期间,代码库集成了 FSDP,有效利用多 GPU 和多节点设置。这种集成对于跨多个计算节点扩展训练过程至关重要,从而显著提高训练速度和效率。
Flash Attention。另一项关键改进是集成了 Flash Attention 2 (Dao, 2023),这是一种优化的注意机制。该存储库还提供融合层范式、融合交叉熵损失和融合旋转位置嵌入,共同在提高计算吞吐量方面发挥着关键作用。
xFormers。将 xFormers (Lefaudeux et al., 2022) 存储库中的融合 SwiGLU 模块替换为原始 SwiGLU 模块,进一步提高代码库的效率。借助这些功能,可以减少内存占用,使 1.1B 模型能够适应 40GB 的 GPU RAM。
性能分析和与其他模型的比较。这些元素的结合将训练吞吐量提升至每 A100-40G GPU 每秒 24,000 个tokens。与 Pythia-1.0B(Biderman,2023)和 MPT-1.3B 2 等其他模型相比,代码库表现出卓越的训练速度。例如,TinyLlama-1.1B 模型仅需要 3,456 个 A100 GPU 小时即可处理 300B 个tokens,而 Pythia 需要 4,830 小时,MPT 需要 7,920 小时。这显示了优化的有效性以及在大模型训练中节省大量时间和资源的潜力。
训练
基于 litgpt 构建框架。遵循 Llama 2,在预训练阶段采用自回归语言建模目标。与 Llama 2 的设置一致,用 AdamW 优化器 (Loshchilov & Hutter, 2019),将 β1 设置为 0.9,将 β2 设置为 0.95。此外,用余弦学习率程序,最大学习率为 4.0 x 10^-4,最小学习率为 4.0 x 10^-5。用 2,000 个预热步来促进优化学习。将批处理大小设置为 2M个 token。将权重衰减指定为 0.1,并用梯度裁剪阈值 1.0 来调节梯度值。文中用 16 个 A 100-40G GPUs 对 TinyLlama 进行预训练。
评估
如表是常识方面的性能:

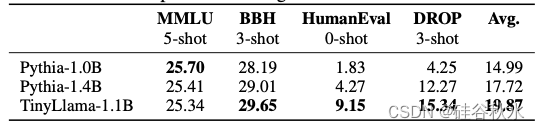
求解方面的InstructEval基准性能:















 1402
1402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









