










24年3月来自上海AI实验室、商汤科技、香港中文大学和复旦大学的技术报告“InternLM2 Technical Report“。
继续介绍评估的技术。
概述
对语言模型在各个领域和任务上的表现进行全面的评估和分析。评估分为两个主要类别:(a)下游任务和(b)对齐。对于每个类别,进一步将评估细分为特定的子任务,详细了解模型的优势和劣势。最后,讨论语言模型中数据污染的问题及其对模型性能和可靠性的影响。本文所有评估均使用 OpenCompass(https://github.com/open-compass/opencompass)执行。
下游任务的表现
首先是多个 NLP 任务的评估协议和性能指标。绩效评估将通过六个关键维度进行剖析:(1)综合考试,(2)语言和知识,(3)推理和数学,(4)多种编程语言编码,(5)长上下文建模,(6)工具使用。
综合考试
对一系列与考试相关的数据集进行基准测试,其中包括:
MMLU(Hendrycks,2020):包含 57 个子任务的多项选择题数据集,涵盖人文、社会科学、STEM 等主题。给出 5 样本测试结果。
CMMLU(Li,2023a):特定中国的多项选择题数据集,包含 67 个子任务。除了人文、社会科学、STEM 等之外,它还包括许多中国特有的任务。还是 5 样本测试结果。
C-Eval(Huang,2023):包含 52 个子任务和 4 个难度级别的多项选择题数据集,涵盖人文、社会科学、STEM 等主题。给出 5 样本测试结果。
AGIEval(Zhong,2023):以人为中心的基准,包括多项选择题和开放式问题。这些问题来自 20 场官方、公开和高标准的入学和资格考试,旨在面向一般人类考生,并报告 0 样本测试结果。
GAOKAO-Bench(Zhang,2023):包含 2010 年至 2022 年中国高考(高考)的数据集,包括主观和客观问题。只评估客观问题的数据集并报告 0 样本测试结果。
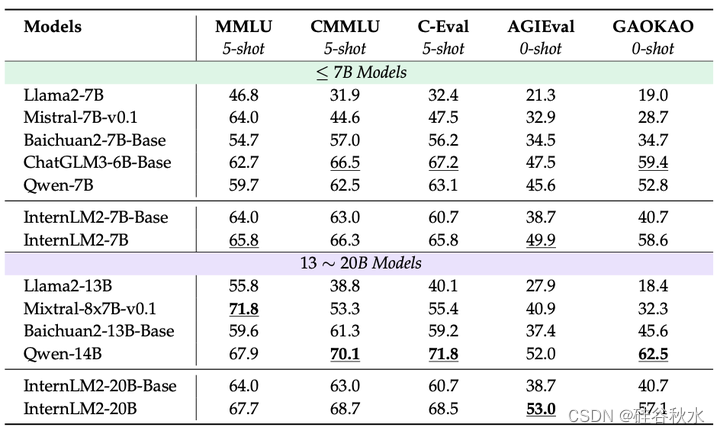
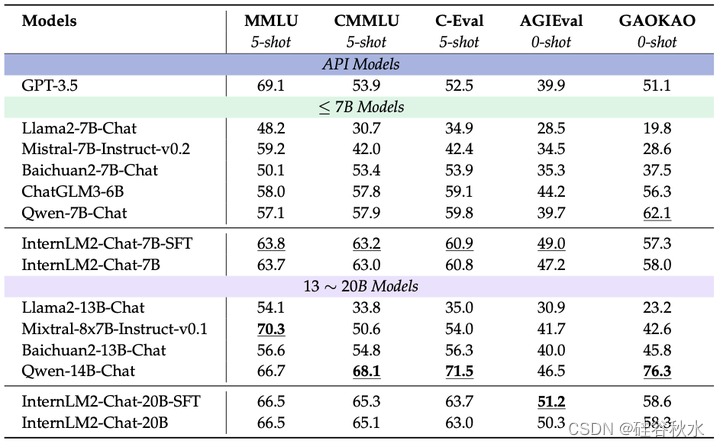
评估结果如下表所示。对于基础模型,在参数数量相近的模型中,InternLM2系列表现优异。在7B和20B上,InternLM2相比InternLM2-Base有明显提升,证明在通用领域数据和领域增强语料上进行预训练对综合考试具有优势。对于AGIEval和GAOKAO任务,这些任务都是专门针对人类设计的考试,相对于其他数据集,InternLM2相比InternLM2-Base有更大的提升。对于聊天模型,在参数数量相近的模型中,InternLM2系列也表现出色。通过比较InternLM2-Chat-7B-SFT和InternLM2-Chat-7B模型可以看出,COOL RLHF对综合考试成绩影响不大。
语言和知识
TriviaQA(Joshi,2017):包含阅读理解和开放域问答的数据集。平均而言,每个问题有 6 个可能的答案。用了开放域问答数据子集,并报告 0 样本结果。
NaturalQuestions(Kwiatkowski,2019):问答数据集,其中的问题来自用户,答案由专家验证。报告 0 样本结果。
C3(Sun,2020):自由形式的多项选择中文机器阅读理解数据集。报告 0 样本结果。
RACE(Lai,2017):阅读理解数据集,包括针对 12 至 18 岁中国初中和高中学生的英语阅读理解考试问题。用高中生的子集并报告 0 样本结果。
FLORES(Team et al.,2022):从维基百科中提取的翻译数据集,涵盖 101 种语言。评估从英语到其他 100 种语言的翻译结果,反之亦然。对于每对翻译任务,选择 100 个样本并使用 BLEU 进行评估。报告 8 样本结果。
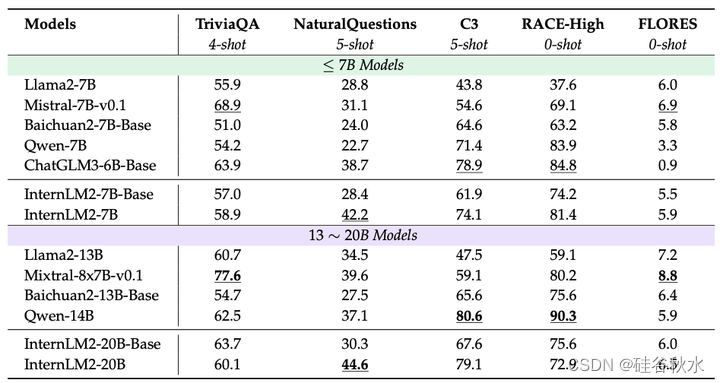
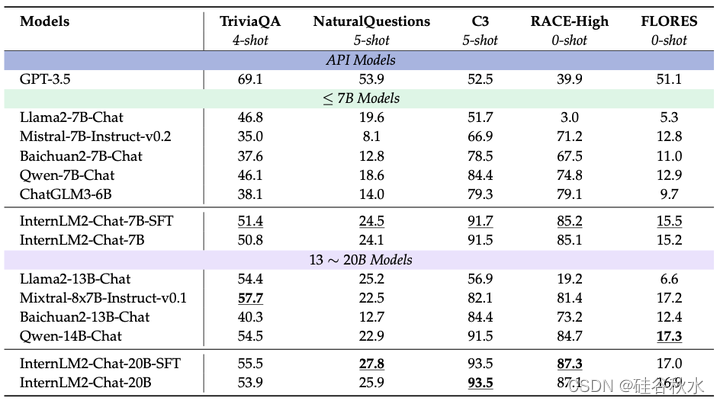
评估结果如下表所示:在第一表中报告了基础模型的结果,在第二表中报告了聊天模型的结果。由于其严格且高质量的训练语料库,InternLM2 在涉及语言理解和知识应用的任务中表现出了显著的竞争优势。因此,它成为众多现实世界应用的绝佳选择,在这些应用中,对强大的语言理解和广泛的知识至关重要。
推理和数学
推理数据集:
• WinoGrande(Sakaguchi,2020):一个常识推理数据集,包含 44,000 个多项选择题,每个问题有两个选项。它要求模型根据场景为描述性文本中的代词选择合适的实体词。
• HellaSwag(Zellers,2019):一个用于评估常识性自然语言推理的具有挑战性的数据集,包含 70,000 个多项选择题。每个问题都呈现一个场景和四种可能的结果,要求选择最合理的结论。
• BigBench Hard (BBH)(Suzgun,2023):一个大语言模型的测试集,BBH 从 BIG-Bench 中提取 23 个具有挑战性的任务,当代语言模型还没有超越人类的表现。
数学数据集:
• GSM8K-Test(Cobbe,2021):包含约 1,300 个小学情景数学问题的数据集。这些问题的解决涉及 2 到 8 个步骤,主要使用基本算术运算(加法、减法、乘法和除法)执行一系列基本计算以得出最终答案。
• MATH(Hendrycks,2021):包含 12,500 个具有挑战性的高中水平竞赛数学问题的数据集,涵盖从代数到微积分的多个领域。每个问题都包含完整的分步解决方案。
• TheoremQA(Chen,2023a):一个由 STEM 定理驱动的问答数据集,包含 800 个 QA 对,涵盖数学、EE&CS、物理和金融领域的 350 多个定理。它测试了大语言模型在应用定理解决具有挑战性大学级问题方面的局限性。
• MathBench(Liu,2024b):MathBench 包含 3709 个问题,分为多个阶段,挑战性逐渐增加。每个阶段都包含双语理论和应用导向问题,每个问题都用三级标签精确标记以表明其细粒度的知识点。
在推理和数学问题的评估中,对于多项选择题,主要使用零样本方法。对于开放式问题,例如 GSM8k、MATH 和 MathBench 的开放式部分中的问题,主要采用少样本方法来增强模型遵循指令的能力,从而有助于提取答案。为了确保评估结果的一致性,对于基础模型,用困惑度 (PPL) 评估作为评估多项选择题的主要方法。
推理。推理能力反映了模型理解、处理和操纵抽象概念的能力,这对于涉及复杂问题解决和决策的任务至关重要。分别从Base和Chat两个方面对InternLM2的性能进行了比较和展示,如表所示。
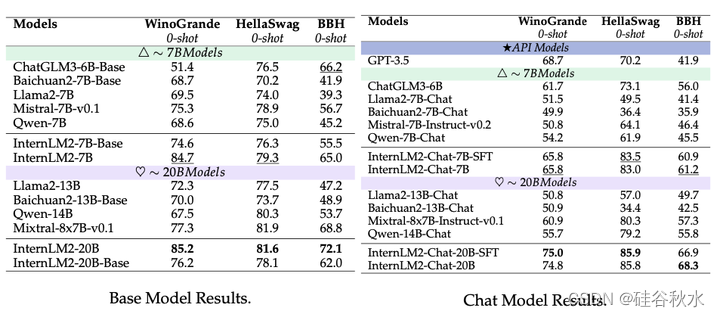
评估结果如下表所示:
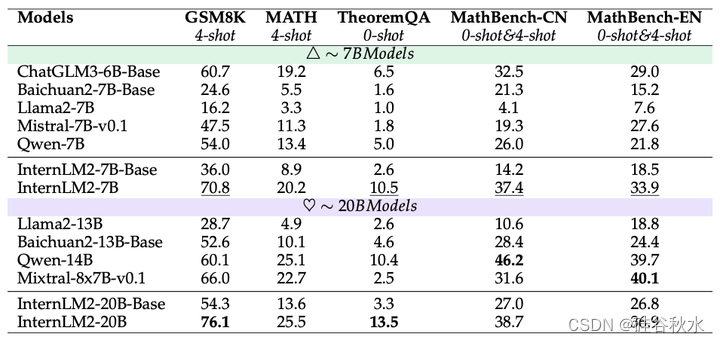
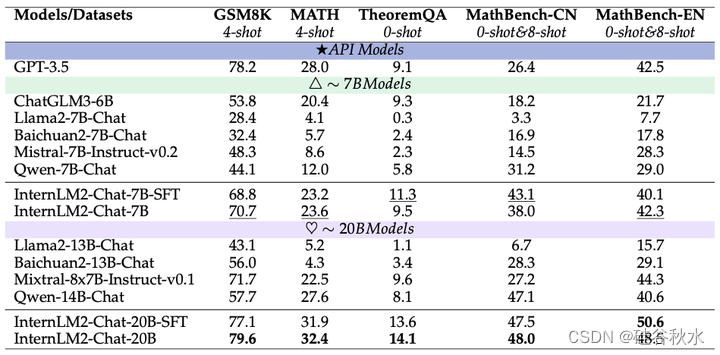
对于 7B 左右的模型,InternLM2-7B 在 BBH 之外的大多数数据集上都表现出色。在所有测试的基础模型中,InternLM2-20B 实现了最佳整体性能。
在聊天模型内的推理方面,InternLM2 继续领先,无论是在 7B 阶段还是 13∼20B 阶段。RL 模型和 SFT 模型在显著高级的推理能力基础上表现出类似的效果。
数学。数学能力是模型认知和计算能力不可或缺的元素。上面第一个表中展示了 Base 模型在多个不同难度的数学测评集上的表现,在 7B 参数规模上,InternLM2-7B 处于领先地位。
聊天。对于上面第二个表中的聊天模型,InternLM2-Chat 在 7B 和 20B 参数规模上,在基本算术 GSM8K、复杂应用数学 MATH 和理论问题 TheoremQA 中均表现出色。
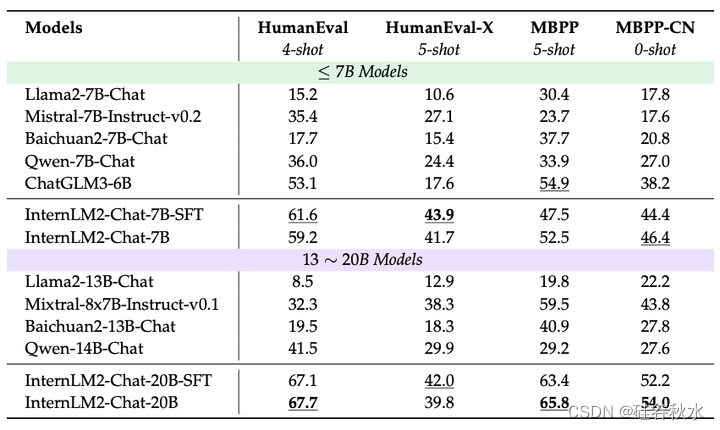
代码
Python 编码任务
• HumanEval。HumanEval (Chen,2021) 是一个广为人知的数据集,可作为评估代码生成模型性能的基准。它由 164 个精心设计的编程任务组成,每个任务都由一个 Python 函数和一个随附的文档字符串组成,以提供上下文和规范。这个数据集以人工编写的代码为特色,在评估大语言模型 (LLM) 在生成或完成程序时的能力方面起着关键作用。
• MBPP。MBPP (Austin,2021) 由 974 个编程任务组成,这些任务可由入门级程序员解决。这些任务范围从简单的数字操作到需要外部知识的更复杂问题,例如定义特定的整数序列。用 MBPP 的净化版本,其中仅包含作者手动验证的数据子集。
多编程语言写代码的任务
• HumanEval-X。HumanEval-X (Zheng,2023b) 数据集是原始 HumanEval 基准的多语言扩展,旨在评估跨多种编程语言代码生成模型的能力。它由 164 个手工制作的编程问题组成,每个问题都翻译成五种主要语言:C++、Java、JavaScript、Go 和 Python。这总共产生 820 个问题解决方案对,支持代码生成和代码翻译任务。HumanEval-X 允许评估模型生成功能正确的代码和在不同语言之间翻译代码的能力,使用测试用例来验证生成代码的正确性。该基准有助于更全面地了解预训练的多语言代码生成模型及其在现实世界编程任务中的潜在应用。
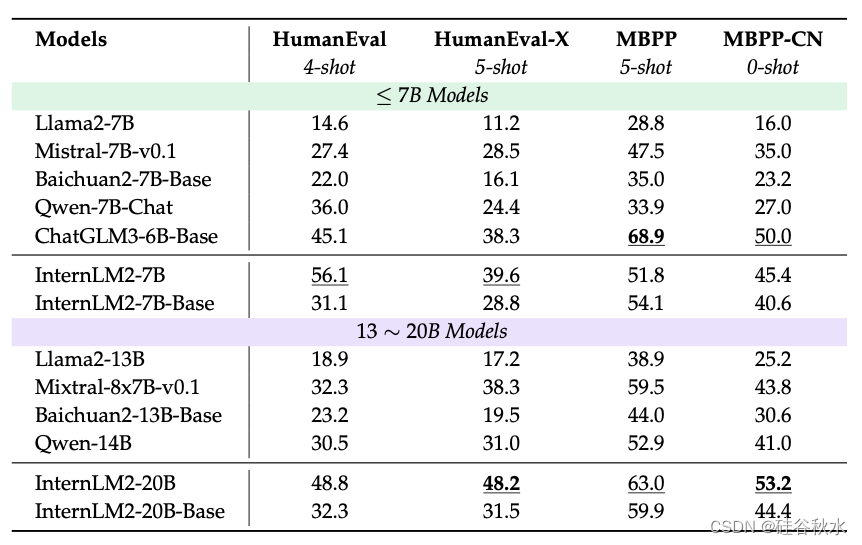
为了评估 InternLM2 的编码能力,利用广受认可的基准 MBPP(Austin,2021)和 HumanEval(Chen,2021)进行了一系列实验。此外,为了衡量多种编程语言代码生成模型的能力,扩展了评估范围,包括 MBPP-CN(MBPP 的中文改编版)和 HumanEval-X(原始 HumanEval 基准的多语言扩展)。
如下表的评估结果所示,InternLM2 模型系列实现了领先的性能,尤其是在 HumanEval、MBPP 和 MBPP-CN 上,其中 InternLM2-Chat-20B 模型比之前的最先进模型高出 10% 以上,凸显了 InternLM2 系列在代码生成任务中的卓越能力。此外,在 MBPP-CN 基准测试中,InternLM2-Chat-20B 模型比 InternLM2-Chat-7B 模型表现出了显著的改进,但在 HumanEval-X 上的表现略有下降。这种现象可能是因为 InternLM2-Chat-20B 模型针对中文进行了微调,而牺牲了对其他语言的有效性。
增强训练前后的表现
从前面部分的结果,看到经过特定能力增强训练的 InternLM2 始终优于其对手。如图显示此阶段前后模型性能的总体比较,其中各种能力分数来自多个评估集的平均值。
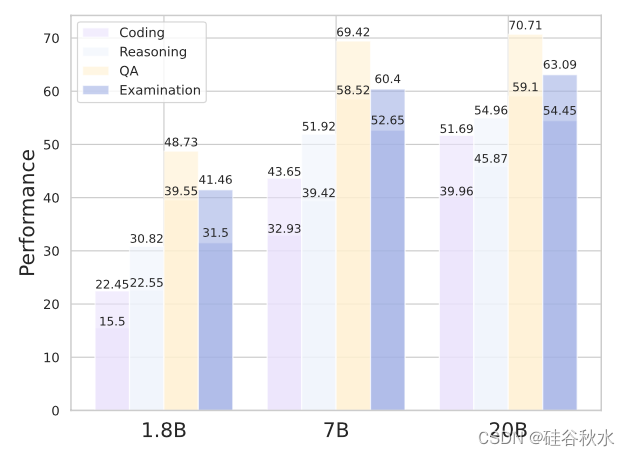
编码:HumanEval 和 MBPP。
推理:MATH、GSM8k、SummEdits(Laban,2023)和 BBH。
问答:HellaSwag、PIQA(Bisk,2020)、WinoGrande、OpenBookQA(Mihaylov,2018)、NaturalQuestions 和 TriviaQA。
考试:MMLU、AGIEval 和 C-Eval。
很明显,这些能力有了显着的提高。此外,在下表中比较基础模型在进行增强训练之前和之后进行监督微调 (SFT) 时的性能。能力维度与 OpenCompass 中采用的分类一致。可以观察到,使用针对特定能力的增强训练的 SFT 模型在各个能力维度上都取得了更好的性能。本报告其他部分的 SFT 性能基于增强训练之前的基础模型。

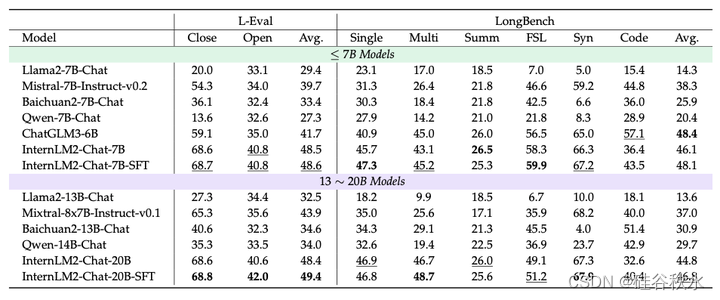
长上下文建模
长上下文理解与推理。主要在以下两个基准上评估 InternLM2 的长上下文建模能力:L-Eval(An,2023)和 LongBench(Bai,2023b)。
L-Eval。L-Eval 是一个长上下文基准,由 18 个子任务组成,包括法律、经济和技术等各个领域的文本。L-Eval 包含 411 篇文档和 2000 多个测试用例,平均文档长度为 7217 个字。此数据集中的子任务可分为两大类:5 个封闭式任务和 13 个开放式类别。封闭式任务使用基于精确匹配的准确度进行评估,而开放式任务采用 Rouge 分数作为指标。
LongBench。LongBench 是一个长上下文基准,由 21 个子任务组成,总共 4750 个测试用例。这是第一个双语长上下文基准测试,平均英文文本长度为 6711 个词,平均中文文本长度为 13386 个字符。21 个子任务分为 6 类,对模型各方面的能力进行了更全面的评估。
评估结果。在下表中报告 InternLM2 在长上下文基准测试中的评估结果。InternLM2 的所有变体都在两个基准测试中展示了强大的长上下文建模性能。InternLM2-Chat-20B-SFT 在 L-Eval 上取得了最佳性能,并且远远领先于其他同类模型。在 LongBench 上,InternLM2-Chat-7B-SFT 在 6 个子任务类别中的 4 个中表现优于其他 ≤ 7B Models 模型。它获得了 48.1 的总分,仅略低于 ChatGLM3-6B 的 48.4 总分。同时,对于 InternLM2,不同的参数大小不会导致长上下文性能的显著差异,这将有待进一步研究。
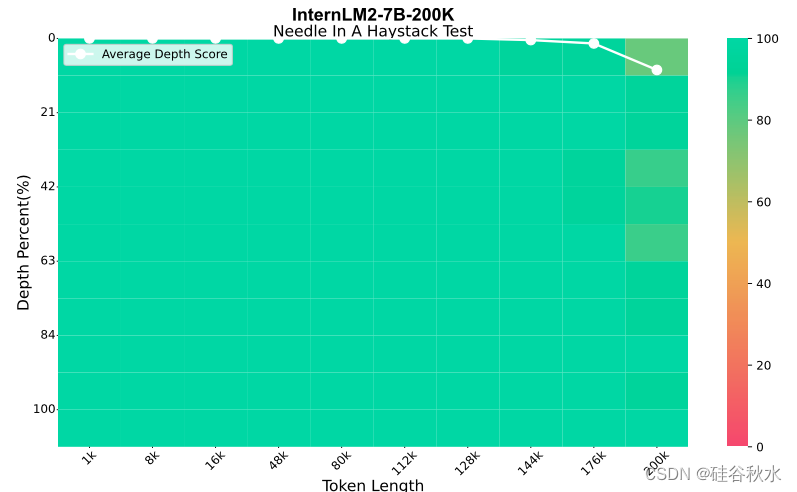
大海捞针。 “大海捞针”是一项单针检索任务,旨在测试大语言模型 (LLM) 回忆单个关键信息的能力。具体方法是将关键信息插入目标长度的 Haystack 文本不同位置,然后在提示的末尾向模型查询该关键信息。此方法可以精确地可视化 LLM 在不同长度的长文本中不同位置的回忆能力。按照最初的想法设计一个中文 Haystack,并利用 (Wei 2023) 发布的 Skywork/Chinese Domain Modeling Eval 数据集,确保中文文本来源的多样性和质量。该数据集涵盖了从金融到技术的广泛领域,提供高质量、最新的中文文章,并为评估不同模型处理特定领域长文本的能力提供了稳定的基准。对于此实验,用 LMDeploy Contributors (2023a) 推理引擎来加速推理过程。如图中呈现的结果有效地证明了 InternLM2 的长上下文建模能力。
工具利用率
人们普遍认为,外部工具和 API 可以显著增强 LLM 解决复杂现实问题的能力 (Qin,2023a;b;Schick,2023)。为了分析 InternLM2 在工具利用方面的熟练程度,在几个基准数据集上进行了实验:GSM8K (Cobbe,2021)、Math (Hendrycks,2021)、最近推出的 MathBench (Liu,2024b)、T-Eval (Chen,2023b) 和 CIBench 的模板子集,均采用 ReAct 协议 (Yao,2023),其中 LLM 在生成思维过程和执行操作之间交替进行。值得注意的是,MathBench 包含 3709 个问题,涵盖了从小学到高中水平的数学概念。该数据集可以全面评估LLM解决数学问题的能力。T-Eval(Chen,2023b)具有经过人工验证的高质量问题说明和相应的分步解决方案。它从六个不同的维度衡量LLM使用日常工具(例如 Google 搜索和高德地图)的熟练程度。团队开发的 CIBench 使用交互式 Jupyter 笔记本模拟真实的数据分析场景。它包含多个连续的任务,涵盖了数据分析中最常用的 Python 模块,包括 Pandas、Numpy 和 Pytorch。这个定制的基准可以全面评估LLM在数据分析方面的综合能力。
GSM8K、MATH 和 MathBench 用外部代码解释器并遵循 ReAct 协议来评估LLM解决编码和数学问题的能力。如图所示,即使在使用代码解释器时,结果也显示出显着的改进,特别是在 MATH 数据集上,增强效果非常显着。

如下图所示,对于最近引入的 MathBench 数据集,使用代码解释器在大多数情况下可以提高 InternLM2 的性能,而轻微的下降可能归因于对此类解释器的错误使用。此外,在 InternLM2-20B-Chat 的知识领域和 InternLM2-7B-Chat 的应用部分中也观察到了显着的改进。这些差异可能源于多种因素,包括各自训练数据集的构成差异。
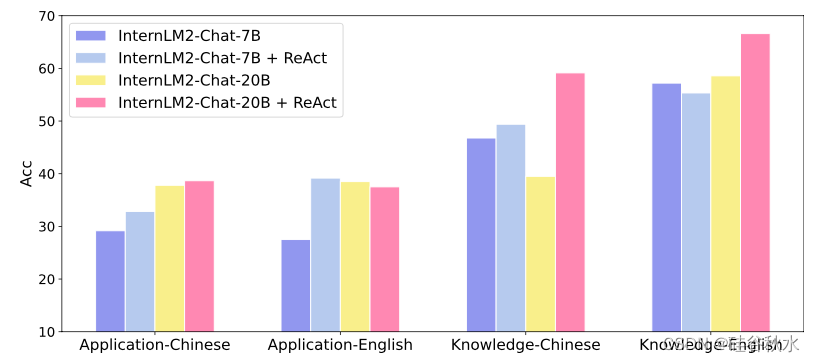
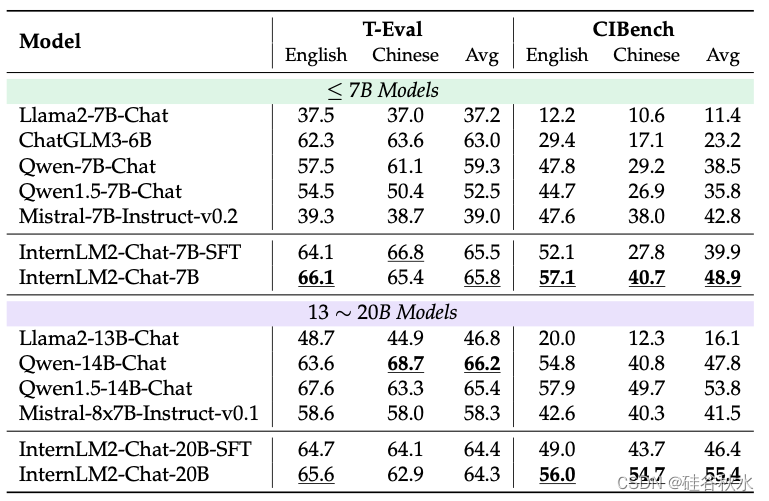
T-Eval 和 CIBench 如下表所示,与现有模型相比,InternLM2 模型在各种基准测试中始终表现出优异或可比的性能。具体而言,在比较相同规模的模型时,InternLM2-Chat-7B 在 T-Eval 和 CIBench 上表现最佳。同时,InternLM2-Chat-20B 在 T-Eval 上取得了有竞争力的结果,并在 CIBench 上获得了最高分。此外,InternLM2系列模型在中文方面取得了令人印象深刻的成绩,展示了它们在多种语言方面的熟练程度。
对齐性能
虽然LLM的客观能力通过预训练和SFT得到了提高,但它们的回答风格可能与人类的偏好不一致,需要通过RLHF进一步增强以提高对齐能力。因此,评估对齐能力对于确定LLM是否真正满足人类需求至关重要。
评估InternLM2在几个流行的主观对齐数据集上的表现,比较了SFT和RLHF模型的性能。如表所示,InternLM2在对齐任务中的整体表现在多个基准上取得了SOTA或接近SOTA的结果,表明InternLM2系列模型的主观输出与人类偏好之间存在高度一致性。
英文主观评价
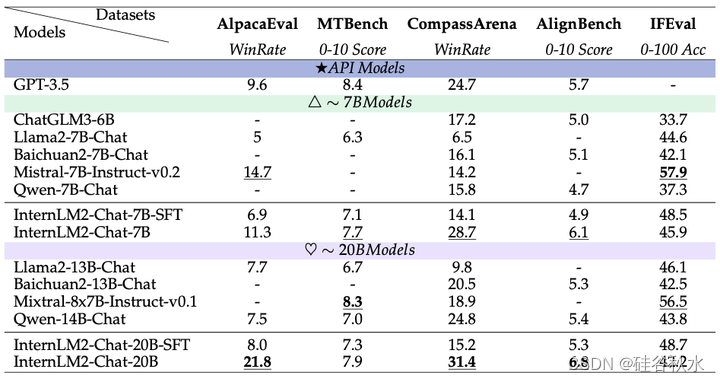
AlpacaEval。AlpacaEval(Li et al., 2023b)是一个单轮问答数据集,包含805个问题。其主要目的是评估模型响应对人类的帮助程度,通过对抗性评估反映与人类意图的一致性。AlpacaEval(v2)建立了一个基线模型,并使用GPT4-Turbo作为评判模型,将基线的答案与被评估模型的答案进行比较。它选择更符合人类偏好的模型并计算胜率。AlpacaEval(v2)不是直接收集评判模型的回答,而是使用logit概率对评判模型的偏好进行统计分析。然后将这些偏好用作计算加权胜率的权重因子。如上表所示,InternLM2-20B的胜率为21.8,是比较模型中SOTA结果最高的,并展示了其优越的对齐性能。此外,该表显示,RLHF 模型在胜率方面优于 SFT 模型,这凸显了对齐策略的有效性。
MTBench。MTBench(Zheng,2023a)是一个两轮对话数据集,包含 80 个问题,涵盖八个维度:推理、角色扮演、数学、编码、写作、人文、STEM 和信息提取。每个维度包含 10 个问题,经过两轮提问。首先,测试模型回答基本问题的能力;随后,它必须遵循额外的具体指示来改进其先前的响应。评分由评判模型按 1-10 的等级分配。如表所示,InternLM2 在 7B 和 20B 版本中均取得了领先的分数,分别为 7.7 和 7.9,证明了其可靠的多轮对话能力。
中文主观评价
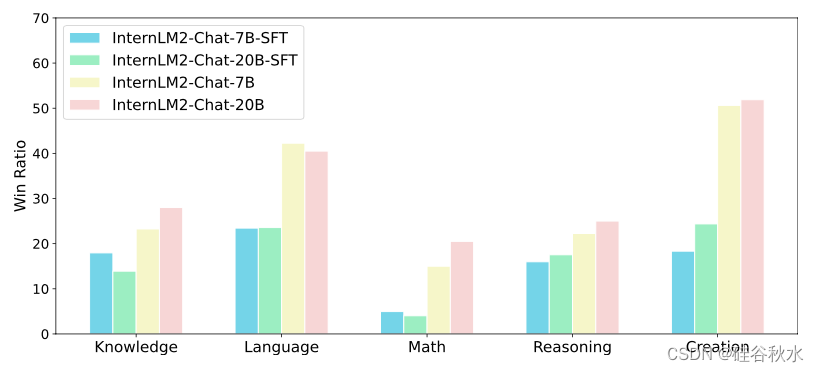
CompassArena。CompassArena 包含 520 个中文问题,涵盖知识、语言、数学、推理和创造力。与 AlpacaEval 一样,它计算由 GPT4-Turbo 评判的两个模型胜率,并通过交换模型顺序进行双盲测试以减轻位置偏差。如上表所示,InternLM2 在 7B 版本(28.7)和 20B 版本(31.4)中获得了最高的胜率。请注意,InternLM2 的 7B 和 20B 版本之间的性能差距相对较小。然而,与 SFT 模型相比,InternLM2 的 RLHF 模型显示出显着的性能提升。这表明 RLHF 策略大大增强了 InternLM2 与人类偏好的一致性,而不仅仅是增加了模型规模。此外,如图按类别细分的结果显示,InternLM2 系列拥有极强的中文创造力和语言能力,胜率可与 GPT4-Turbo 相媲美。
AlignBench。AlignBench(Liu et al., 2023a) 是一个中文主观数据集,包含 683 个问答对,分为八个领域,包括基础语言能力、高级中文理解、任务导向角色扮演等,涵盖物理、历史、音乐和法律等各种场景。该数据集使用名为 CritiqueLLM(Ke et al., 2023) 的内部判断模型进行评估。CritiqueLLM 为每个问题在各个维度上提供从 1 到 10 的分数,并发布最终分数。在表中列出了 CritiqueLLM 提供的最终分数,并在下表中列出了不同类别的详细分数。如上表所示,InternLM2 在 7B 和 20B 版本中均获得了 SOTA 分数,分别为 6.1 和 6.8,优于 GPT-3.5 的 5.7 分。此外,与 SFT 模型相比,7B 和 20B 版本的 InternLM2 在 RLHF 后都表现出显着的性能提升,突显了RLHF 策略在提高模型与人类偏好的一致性方面的有效性。对详细分数的分析揭示了数学和推理能力有待改进的地方;然而,InternLM2 在问答和角色扮演任务中表现出色,提供了强大的主观表现。

指令遵循评估
IFEval。IFEval(Zhou et al.,2023)旨在测试模型的指令遵循能力,要求响应遵守特定模式,例如字母大小写限制和关键字限制。IFEval 包含 25 种不同类型的指令,构建了 541 个遵循指令的问题,并采用基于规则的评估来评估模型对每个问题的回答的正确性。利用各种统计方法,IFEval 提供四种类型的准确度分数:提示级严格、提示级宽松、实例级严格和实例级宽松。在上上表中展示了这四个分数的平均结果。虽然像 Llama2 和 Mistral 这样的基于英语的模型在 IFEval 上的表现通常优于基于中文的模型,但 InternLM2 在 7B 阶段(48.5)和 13-20B 阶段(48.7)分别排名第二和第三。这表明,尽管指令遵循任务面临挑战,但 InternLM2 在类似规模的模型中保持领先地位。
数据污染的讨论
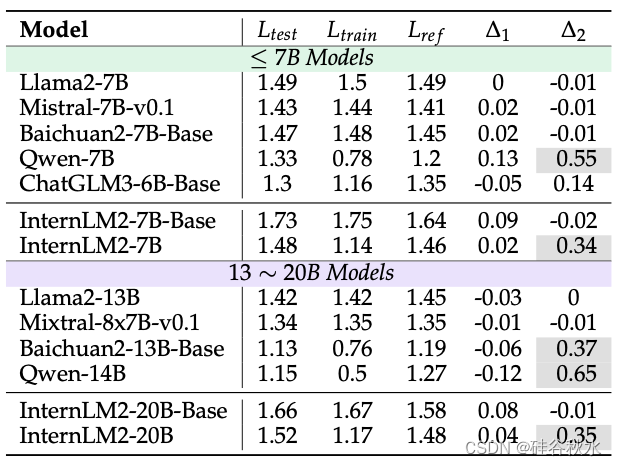
针对几个基础模型评估了 GSM8K 数据集中样本(样本是问题和答案的拼接)的语言建模 (LM) 损失,结果如表所示。对于每个 LLM,比较训练分割(Ltrain)、测试分割(Ltest)和专门策划的参考集(Lref)上的 LM 损失,后者由 GPT-4 生成,旨在模拟 GSM8K 数据集。还报告了两个关键指标:∆1 = Ltest − Lref,作为 LLM 训练期间潜在测试数据泄漏的指标,即较低的值表示可能存在泄漏;∆2 = Ltest − Ltrain,用于测量数据集训练分割的过拟合程度。∆2 值较高意味着过度拟合。∆1 和 ∆2 的异常值都以灰色突出显示。

















 679
679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









