










23年11月来自Meta GenAI的论文“Effective Long-Context Scaling of Foundation Models”。
这是一系列长上下文 LLM,支持最多 32,768 个 tokens 的有效上下文窗。该模型系列通过更长的训练序列和长文本上采样的数据集从 LLAMA 2 进行持续预训练而构建。对语言建模、合成上下文探测任务和广泛的研究基准进行广泛的评估。在研究基准上,模型在大多数常规任务上实现持续改进,并在 LLAMA 2 上实现长上下文任务的显着改进。值得注意的是,通过一种不需要人工标注长指令数据的经济高效指令调优程序,其70B 模型已经可以超越 gpt-3.5-turbo-16k 在一系列长上下文任务上的整体性能。除了这些结果之外,对方法的各个组成部分进行了深入分析。研究了 LLAMA 的位置编码,并讨论了其在长依赖关系建模方面的局限性。还研究了预训练过程中各种设计选择的影响,包括数据混合和序列长度的训练课程。
到目前为止,具有强大长上下文能力的 LLM 主要通过专有 LLM API 提供(Anthropic,2023;OpenAI,2023),并且没有开放的方法来构建可以展示与这些专有模型相当下游性能的长上下文模型。此外,现有的开源长上下文模型(Tworkowski,2023b;Chen,2023;Mohtashami & Jaggi,2023;MosaicML,2023b)在评估中往往表现不佳,主要使用语言建模损失和合成任务来衡量长上下文能力,而这些任务并不能全面展示它们在多样化的现实场景中的有效性。此外,这些模型往往忽视在标准短上下文任务上保持强劲性能的必要性,要么绕过评估,要么报告其性能下降(Peng,2023;Chen,2023)。
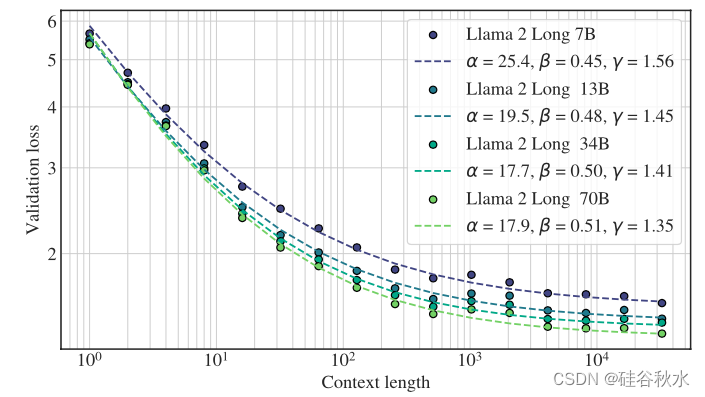
如图所示:模型的验证损失可以拟合为上下文长度的函数:L© = ( α/c )^β + γ,其中每个模型大小都有不同的 α、β、γ 集合。这种幂律关系还表明,上下文长度是扩展 LLM 的另一个重要轴,随着上下文长度增加到 32,768 个tokens,模型可以不断提高其性能。
持续预训练
由于注意的二次计算复杂度,使用较长的序列长度进行训练会带来显著的计算开销。这是采用持续预训练方法的主要动机。通过从短上下文模型持续预训练可以学习到类似的长上下文能力,这一基本假设通过比较不同的训练课程得到验证。几乎保持原始 LLAMA 2 架构不变,进行持续预训练,并且只对位置编码进行必要的修改,这对于模型关注更长时间至关重要。还选择不应用稀疏注意 (Child,2019),因为给定 LLAMA 2-70B的模型维度 (h = 8192),只有当序列长度超过 49,152 (6*h) 个 tokens 时,注意矩阵计算和V聚合的成本才会成为计算瓶颈。
位置编码。通过 7B 规模的早期实验,发现LLAMA 2 位置编码 (PE) 的一个关键限制,其阻止注意模块聚合远距 token 的信息。对 RoPE 位置编码 (Su,2022) 进行最小但必要的修改,用于长上下文建模——即减小旋转角度(由超参“基频 b”控制),从而降低 RoPE 对远距 token 的衰减效应。
数据混合。在具有修改PE 的工作模型之上,进一步探索了不同的预训练数据混合,以提高长上下文能力,可以通过调整 LLAMA 2 预训练数据的比例或添加新的长文本数据。对于长上下文持续预训练,数据质量通常比文本长度起着更为关键的作用。
优化细节。不断预训练 LLAMA 2 检查点,增加序列长度,同时保持每批次tokens数与 LLAMA 2 相同。对所有模型进行总共 400B 个tokens的训练,超过 100,000 步。使用 Flash Attention (Dao et al., 2022),当增加序列长度时,GPU 内存开销可以忽略不计,并且对于 70B 模型,当序列长度从 4,096 增加到 16,384 时,速度损失约为 17%。对于 7B/13B 模型,用学习率 2e-5 和余弦学习率进度,并进行 2000 次预热步骤。对于较大的 34B/70B 模型,设置较小的学习率 (1e-5) 很重要,这样才能获得单调递减的验证损失。
指令调优
收集人类演示和偏好标签以进行 LLM 对齐是一个繁琐且昂贵的过程(Ouyang,2022;Touvron,2023)。在长上下文场景下,挑战和成本更加明显,这通常涉及复杂的信息流和专业知识,例如处理密集的法律/科学文档,这使得注释任务即使对于熟练的标注者来说也不是一件容易的事。事实上,大多数现有的开源指令数据集(Conover,2023;Köpf,2023)主要由短样本组成。
一种简单而廉价的方法,利用预构建的大型和多样化短提示数据集,在长上下文基准测试中效果特别好。具体来说,采用 LLAMA 2 CHAT 中使用的 RLHF 数据集,并用 LLAMA 2 CHAT 本身生成的合成自-指导(Wang,2022)长数据对其进行扩充,希望模型能够通过大量 RLHF 数据学习多种技能,并通过自-指导数据将这些知识转移到长上下文场景中。数据生成过程侧重于 QA 格式的任务:从预训练语料库中的长文档开始,选择一个随机块(chunk)并提示 LLAMA 2 CHAT 根据文本块(chunk)中的信息编写QA对。用不同的提示收集长格式和短格式的答案。之后,还采取一个自我批评步骤,提示 LLAMA 2 CHAT 验证模型生成的答案。给定生成的 QA 对,用原始长文档(截断以适应模型的最大上下文长度)作为上下文来构建训练实例。
对于短指令数据,将它们连接为 16,384 个 tokens 序列。对于长指令数据,在右侧添加填充 token,以便模型可以单独处理每个长实例而不会截断。虽然标准指令调整仅计算输出 token 的损失,但计算长输入提示上的语言建模损失特别有益,这可以持续改进下游任务。
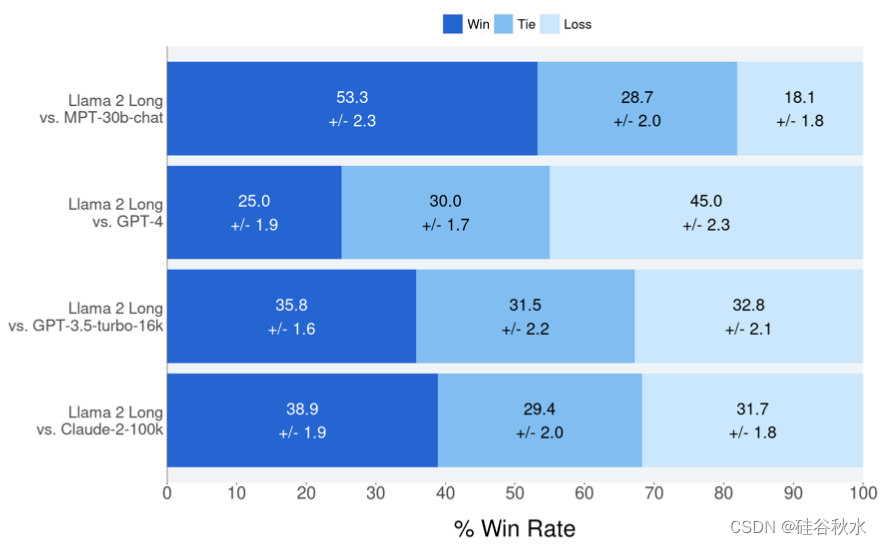
如图所示:人类对多轮对话和多文档搜索查询回答数据的模型响应偏好。















 7498
7498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









