









22年7月来自伯克利分校、华沙大学和谷歌的论文 “LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action“。
机器人导航的目标条件策略可以在大型、未标记的数据集上进行训练,为真实世界的设置提供良好的泛化能力。然而,特别是在基于视觉的设置中,指定目标需要图像,这会导致界面不自然。语言为与机器人的通信提供了一种更方便的方式,但现代方法通常需要昂贵的用语言描述的标注轨迹作为监督信号。本文提出一种用于机器人导航的系统LM-Nav,在未标记的大型轨迹数据集上进行训练,同时仍为用户提供高级界面。不是利用一个标记的指令跟从数据集,这样的系统可以完全由预训练的导航模型(ViNG)、图像-语言关联模型(CLIP)和语言建模模型(GPT-3)构建,不需要任何微调或语言标注的机器人数据。
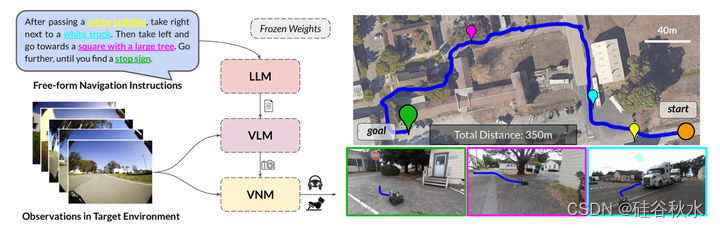
如图是LM-Nav的具身指令跟从例子:系统将目标环境中的一组原始观测值和自由形式的文本指令(左)作为输入,使用三个预训练的模型推导出可操作的规划:用于提取地标的大语言模型(LLM)、用于落地的视觉和语言模型(VLM)以及用于执行的视觉导航模型(VNM);这使LM-Nav能够在复杂环境中完全根据视觉观察(右)遵循文本指令,而无需任何微调。
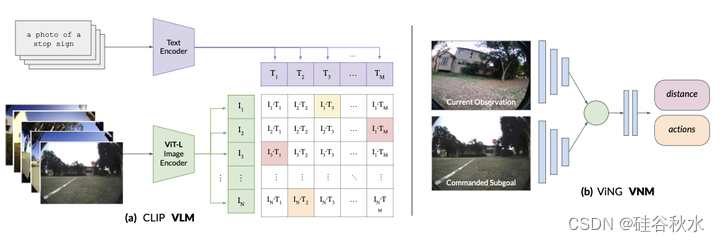
如图所示:LM-Nav使用VLM来推断文本地标和图像观测的联合概率分布。VNM构成了一个图像条件距离函数和可以控制机器人的策略。
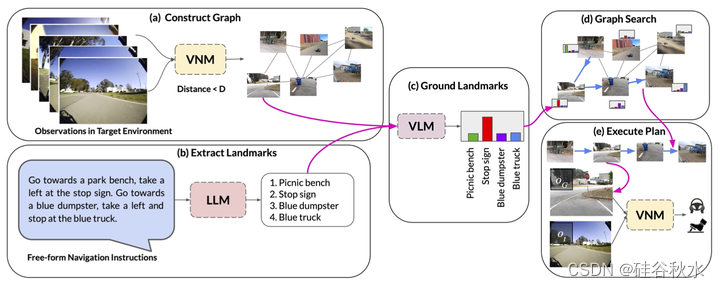
如图是系统概述:(a)VNM用目标条件距离函数来推断原始观测集之间的连通性,并构建拓扑图。(b) LLM将自然语言指令翻译成一系列文本地标。(c) VLM在图中的地标描述和节点上推断联合概率分布,(d)图搜索算法使用该联合概率分布来导出图中的最优遍历。(e) 机器人使用VNM策略在现实世界中跟随行走行驶。
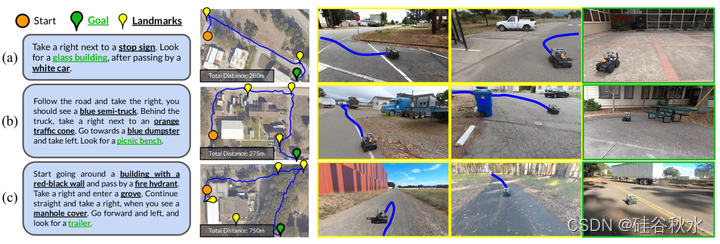
在各种户外环境中部署LM Nav的实验,用小型地面机器人遵循高级自然语言指令。对于所有实验,LLM、VLM和VNM的权重都是冻结的——在目标环境中没有微调或注释。评估整个系统以及LM Nav的各个组件,可以了解其优势和局限性。实验证明了LM-Nav遵循高级指令、消除路径歧义和达到800米外目标的能力。
在每个评估环境中,首先手工驱动机器人并收集图像和GPS观测值来构建图。该图是使用该数据的VNM自动构建的,原则上,这些数据也可以从过去的遍历中获得,甚至可以使用自主勘探方法[45]。一旦构建了一个图,机器人就可以在这种环境中执行指令。在不同难度的环境中对系统进行了20次查询测试,总长度超过6公里。指令包括环境中的一组突出地标,这些地标可以通过机器人的观察来识别,例如交通锥、建筑物、停车标志等。
如图显示了机器人所走路径的定性例子。请注意,头顶图像和地标的空间定位对机器人来说是不可用的,并且仅显示用于可视化。在图(a)中,LM-Nav能够成功地从其先前的遍历中定位简单的地标,并找到到达目标的短路径。虽然环境中有多个停止标志,但机器人在上下文中选择正确的停车标志,从而最大限度地缩短整体行驶距离。图(b)突出了LM-Nav解析具有多个指定路线地标的复杂指令能力——尽管有可能直接到达最终地标的较短路线会忽略指令,但机器人会找到一条以正确顺序访问所有地标的路径。















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









