







23年10月OpenAI公布DALL- E3的技术报告"Improving Image Generation with Better Captions"。
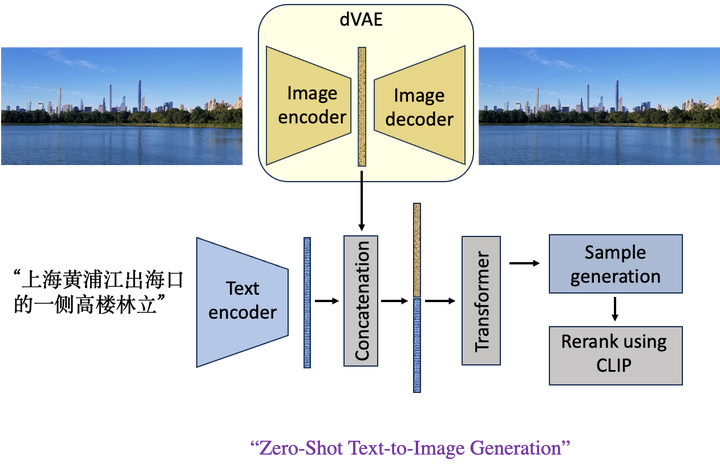
最早的DALL- E v1是这样的:图像和文本的编码器输出合并,利用CLIP得到输出。
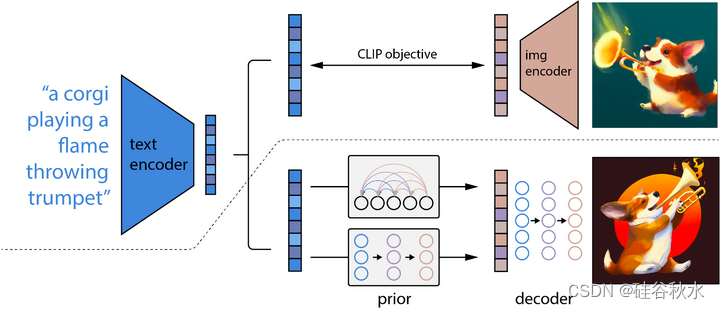
DALL-E v2做了改进,加入扩散模型,结构如下:
DALL-E v3采用了提示调优技术。
对生成的高度描述性图像字幕进行训练,可以显着提高文本-到-图像模型的提示跟从能力。 现有的文本-到-图像模型很难跟从详细的图像描述,并且经常忽略单词或混淆提示的含义。 假设这个问题源于训练数据集中的噪声和不准确的图像字幕。 OpenAI训练定制图像字幕器并用它来重新捕获训练数据集来解决这个问题。 训练了几个文本-到-图像模型,发现这些字幕的训练确实提高了提示跟从能力。 利用这些发现OpenAI构建了 DALL-E 3:一种新的文本-到-图像生成系统,旨在衡量提示的跟从性、连贯性和美观性,各种评估对其性能进行了基准测试,发现与竞争对手相比其具有优势。 OpenAI发布了这些评估的示例和代码,以便未来的研究可以继续优化文本-到-图像系统。
技术细节如下:
文本-到-图像模型是在由大量文本-图像配对 (t, i) 组成的数据集上进行训练的,其中 i 是图像,t 是描述该图像的文本。 在大规模数据集中,t 通常源自人类作者,专注于对图像主题的简单描述,而忽略图像中描绘的背景细节或常识关系。 t 中通常省略的重要细节可能包括:
- 厨房中的水槽或人行道上的停车标志等物体的存在以及对这些物体的描述。
- 场景中目标的位置以及这些目标的数量。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









