










23年10月来自MIT和斯坦福的论文“Eliciting Human Preferences With Language Models “。
语言模型(LM)可以通过使用标记示例或自然语言提示来执行目标任务。但是,选择示例或编写提示可能很有挑战性,尤其是在一些任务中,例如涉及异常边缘情况、需要精确表达模糊偏好或需要LM行为的准确心理模型。
本文建议使用LM本身来引导任务规范过程。作者介绍生成式主动任务激发(GATE):一种学习框架,在该框架中,模型通过与用户以一种自由形式、基于语言的交互来激发和推断预期行为。在三个领域研究GATE:电子邮件验证、内容推荐和道德推理。在预先注册的实验中,被提示执行GATE的LMs(例如,通过生成开放问题或合成信息丰富的边缘案例),激发的反应通常比用户书面提示或标记更具信息性。
如图所示:生成式主动任务激发(GATE),通过交互式、自由形式的问题来激发用户偏好,然后可以用于下游决策。与完全依赖人类来阐明偏好的非互动启发方法(如提示)不同,生成式启发能够更好地探究人类偏好的细微差别。与主动学习方法不同,生成式启发可以提出更通用、更自由的问题。

上面图中包括三个部分:(A)模糊用户偏好:用户希望将他们对如何执行任务的模糊偏好转化为机器学习模型的规范。这是具有挑战性的,因为用户缺乏完美的内省,偏好可能很难用语言指定,规范需要预测棘手的现实世界边缘情况,并且模型可能会根据提供的示例或说明进行误泛化。(B) 任务激发:考虑从用户那里获得这些模糊偏好的各种方式,包括非交互式提示、主动学习和生成式启发(GATE)。(C) 评估:在一个固定的测试集上评估方法,对语言模型预测用户真实决策能力进行评分。
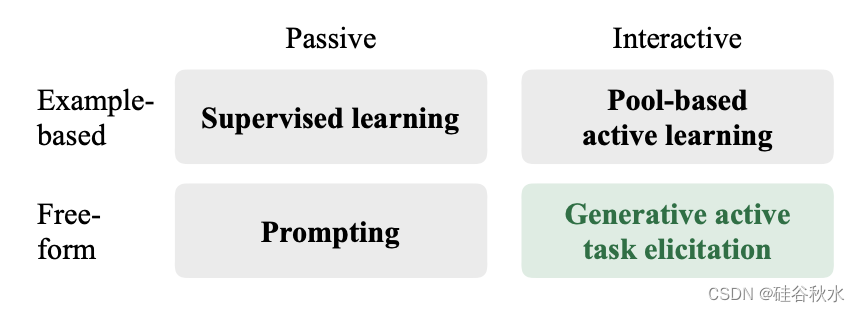
如图所示:现有学习和确认框架被理解为任务激发过程,沿着两个关键轴发生变化,即交互性水平和灵活性水平。在交互式激发方法中,查询可能会根据用户的反应而变化(例如,根据迄今为止已知的信息查询最有用的信息),而被动的激发方法则希望用户在一次任务中提供规范。基于示例的规范方法要求用户标记一组示例,而自由形式的方法限制较少,允许用户提供更广泛的输入,包括自然语言指令和解释。
作者用GPT-4模型(GPT-4-0613 snapshot)(OpenAI,2023)激发用户偏好(即激发策略),然后基于激发的偏好进行预测(即预测器)。为了激发用户偏好,用域描述和当前交互历史去提示GPT-4,并要求它生成一个信息丰富但易于回答的边缘案例(用于生成式主动学习)或问题(用于生成式是-或-否问题和生成式开放问题)。为了进行预测,用任务规范和测试样本提示GPT-4,并要求它为测试样本生成预测。















 1035
1035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









