










23年10月来自谷歌、麻省大学和OpenAI的论文“FreshLLMs: Refreshing Large Language Models With Search Engine Augmentation“。
大多数大语言模型(LLMS)只训练一次,从不更新;因此,他们缺乏动态地适应不断变化世界的能力。这项工作在回答测试当前世界知识问题的背景下,对LLM生成文本的真实性进行了详细研究。具体来说,FRESHQA,一种动态QA基准,涵盖了各种各样的问答类型,包括需要快速变化的世界知识问题,以及需要揭穿的虚假前提问题。在一个双模式评估程序下对一系列封闭和开源LLMs进行了基准测试,该程序允许测量正确性和幻觉性。通过5万多人的评估,揭示了这些模型的局限性,并展示了显著的改进空间:例如,所有模型(无论模型大小)都在快速变化的知识和虚假前提的问题上挣扎。
受这些结果的启发,作者提出了FRESHPROMPT,一种简单的少样本提示方法,将搜索引擎检索的相关和最新信息合并到提示中,大大提高了LLM在FRESHQA上的性能。实验表明,FRESHPROMPT优于竞争对手的搜索引擎增强提示方法,如SELF-ASK(Press 2022),以及商业系统,如PERPLEXITY.AI。对FRESHPROMP的进一步分析表明,检索的证据数量及其顺序,在影响LLM生成答案的正确性方面起着关键作用。此外,与鼓励更冗长答案的方法相比,LLM生成简洁直接的答案有助于减少幻觉现象。
先说FRESHQA。
招募NLP研究人员和在线自由职业者撰写不同难度的问题和主题,这些问题的答案可能会随着世界的新发展而改变,从而收集FRESHQA。如图是FRESHQA的例子。根据答案的性质,问题大致分为四大类:答案几乎永远不会改变;答案通常会在几年内发生变化;答案通常在一年或更短的时间内发生变化;前提事实上是不正确的,因此必须予以反驳。

如图可视化了两种评估模式下不同LLM在FRESHQA上的准确性。第一个明显的结论是,所有模型在FRESHQA上都很吃力:在严格模式(STRICT)下,总体准确性在0.8%至32.0%之间,在松弛模式(RELAXED)下,总体准确度在0.8%至46.4%之间。从RELAXED切换到STRICT导致CHATGPT和GPT-4的准确性显著降低。这主要是由于无法获取最新信息,因为它们会产生“过时”的答案(通常以前缀“我的知识截止日期在2021年9月”开头),在许多情况下,还会“拒绝”提供答案(例如,“作为人工智能语言模型,我无法提供实时信息”)。同样,在STRICT下,PaLM(跨模型大小)的准确性显著下降。这种下降很大程度上是由于人为因素造成的,比如带有意外特殊tokens的类似对话响应和幻觉。相比之下,FLAN-PALM和CODEX由于其简洁直接的答案而表现出最小的幻觉。
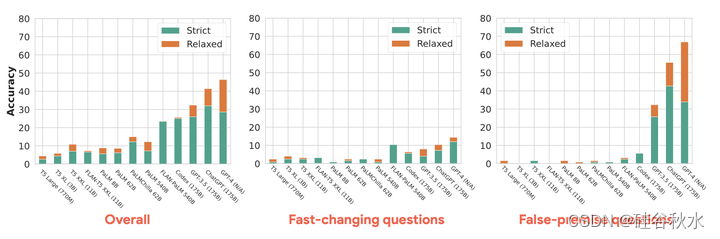
缺乏最新的参数知识导致模型在涉及快速变化或最新知识的问题上准确性显著下降。GPT-4通常在这些问题上获得最高的准确度,但在严格模式(STRICT)下最近知识的问题(即自2022年以来)例外,这时候GPT-4的表现不如FLAN-PALM和CODEX,但在两种评估模式中,GPT-4从未超过15%。评估证实,CHATGPT和GPT-4已接触到超出其知识截止日期的信息数据。此外,与CHATGPT(16%)相比,GPT-4更不愿意回答快速变化的问题(60%的时间拒绝回答)。
所有模型都很难解决有虚假前提问题,更大的模型并不能提高T5和PALM(“平坦缩放”)的精度,性能在0.0%到1.6%之间。GPT-3.5、CHATGPT和GPT-4的精度远高于其他模型,在严格模式(STRICT)下实现了25.8%至42.7%的准确率,在松弛模式(RELAXED)下实现了32.3%至66.9%的准确率。CHATGPT在STRICT下表现最好(42.7%),而GPT-4是RELAXED下最准确的模型(66.9%),在2022年之前的知识问题上其准确率高达83.9%。这些结果表明,OpenAI的模型很可能被训练来应对虚假前提问题。
总体而言,少样本和COT提示对大模型有利,有时对中等规模的模型在具备有效前提的问题上也有利,尤其是在永不改变或旧知识的问题上。在STRICT下,少样本和COT在2022年之前的知识问题上分别比PALM-540B的零样本提示方法准确度提高了+36.1%和+26.9%(在RELAXED下分别提高了+21.9%和+29.7%)。与RELAXED下的少样本相比,COT在很大程度上表现出了优越的性能,而少样本在STRICT下获得了更好的结果,因为COT为幻觉引入了更多的空间。
T5 LARGE/XL无法处理多跳问题,而FLAN-PALM 540B、CODEX和GPT-3.5在从一跳切换到多跳问题时受到的影响最大。GPT-4在这两种类型的问题中保持稳定(不同设置的准确率差异小于2%)。
再说FRESHPROMPT。
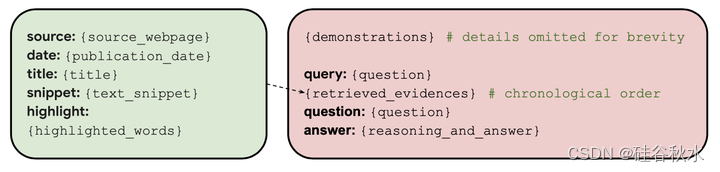
FRESHPROMPT方法利用文本提示(1)将搜索引擎中与上下文相关的最新信息(包括相关问题的答案)引入预训练的LLM,以及(2)教模型对检索的证据进行推理。更具体地说,给定一个问题q,首先逐字逐句地用q来查询搜索引擎,如GOOGLE search。检索所有的搜索结果,包括答案框、绿色结果和其他有用信息,如知识图、来自众包QA平台的问题和答案,以及搜索用户也会问的相关问题。对于这些结果中的每一个,提取相关联的文本片段x以及其他信息,例如源s(假如是WIKIPEDIA)、日期d、标题t、突出显示的单词h,然后创建k个检索的证据e={(s,d,t,x,h)}列表。
如图是FRESHPROMPT的格式。所有检索的证据转换为一个统一的格式(如图左边),并用于通过上下文学习来调节模型。为了鼓励模型在最近的发现之后关注更新的证据(Liu 2023a),在提示中从最久到最新的时间对证据E进行排序。为了帮助模型“理解”任务和期望的输出,在输入提示的开头提供了输入输出示例的少样本演示。每个演示都向模型展示了一个示例问题和检索的问题证据列表,然后是对证据的思维链推理,找出最相关和最新的答案(如图右边)。尽管演示中包括了一些带有虚假前提的问题示例,但也在提示中尝试了一个明确的虚假前提检查:“请在回答之前检查问题是否包含有效前提”。
FRESHPROMPT全面改进了GPT-3.5和GPT-4。在STRICT和RELAXED下,GPT-4+FRESHPROMPT的绝对精度分别比GPT-4提高了47%和31.4%。STRICT和RELAXED之间的绝对准确度差距缩小(从17.8%降至2.2%)也表明FRESHPROMPT显著减少了过时和幻觉答案的存在。不出所料,GPT-3.5和GPT-4最显著的改进是在快速变化和缓慢变化的问题类别上,这两个问题都涉及最近的知识。也就是说,关于旧知识的问题也受益于FRESHPROMPT。例如,在2022年之前涉及知识的有效前提问题上,GPT-4+FRESHPROMPT的准确率在STRICT下比GPT-4高出+30.5%(在RELAXED下为+9.9%)。此外,FRESHPROMPT在虚假前提问题上取得了显著的进步(GPT-4在STRICT和RELAXED下,准确率分别提高了37.1%和8.1%)。
GPT-4+FRESHPROMP在各种问题类型中表现出卓越的准确性,大大超过了所有其他方法。其最佳变型(每个问题有15个检索的证据)在STRICT和RELAXED下分别获得了77.6%和79.0%的总体准确率。GPT-3.5+FRESHPROMPT在STRICT下的总体准确率超过PPLX.AI和SELF-ASK(均在GPT-3.5之上执行),分别为+3.8%和+14.4%。然而,在RELAXED下,PPLX.AI的总体准确率比GPT-3.5+FRESHPROMPT高出+4.2%,这在很大程度上是由于其在虚假前提问题上的卓越准确率(58.1%对41.1%)。PPLX.AI准确率在STRICT和RELAXED之间14.0%差距表明该方法包含大量幻觉。总体而言,所有搜索引擎增强方法(SELF-ASK、PPLX.AI和FRESHPROMPT)在各种问题类型上都比普通的GPT-3.5和GPT-4有显著的优势。GOOGLE SEARCH通常比GPT-3.5和GPT-4都能提供更好的结果,除非是有虚假前提的问题,但在所有类型方面都远远落后于PPLX.AI和GPT-3.5/GPT-4+FRESHPROMPT。
OpenAI的LLM,如GPT-3.5和GPT-4,可能会被调整为处理虚假前提问题,PPLX.AI也是如此。此外,根据经验发现,如果明确询问,一些LLM能揭穿虚假前提问题,例如,“请在回答之前检查问题是否包含有效前提”。将此前提检查添加到GPT-3.5和GPT-4中,在STRICT下,虚假前提问题的准确率分别提高了+23.4%和+6.4%(在RELAXED下分别提高了22.6%和+111.3%)。然而,就其他问题类型而言,这对GPT-3.5是有害的,在STRICT和RELAXED下,总体准确率分别降低了20.8%和21%;这对GPT-4来说不是问题,在STRICT下略有下降0.6%,在RELAXED下略有上升1.2%。
还分析了提示中证据的顺序如何影响GPT-4的准确性。结果表明,与使用随机顺序(RANDOMORDER)相比,使用GOOGLE SEARCH返回的顺序(SEARCH order,在输入上下文末尾的顶部搜索结果)或根据相关日期信息对证据进行排序(TIME order,在末尾的最新结果)总是会产生略好的准确性,STRICT和RELAXED的总体准确性高出+2.2%。在GPT-4+FRESHPROMPT中,仅使用每个证据的文本片段而不使用额外信息(如来源、日期等)会略微降低准确性,在两种模式中都低于1%。
结合绿色搜索结果之外其他检索的证据,例如搜索用户也会问的答案框或相关问题,是有帮助的。删除答案框会使GPT-4+FRESHPROMPT在STRICT下的总体准确率降低1.4%(在RELAXED下则为1.6%)。删除答案框和其他相关信息(包括相关问题)会使GPT-4+FRESHPROMPT的总体准确率降低3.2%(在RELAXED下则为3.0%)。
在GPT-4的实验中改变检索证据的数量,探索每个问题的检索证明数量以及演示数量的影响。请注意,对GPT-4+FRESHPROMPT的默认设置是,为每个问题用10个检索证据和5个演示。结果表明,每个问题的检索证据数量是实现最高准确性的最重要因素。在STRICT下,这个数字从1增加到5、10和15,相应的总准确率分别提高了+9.2%、+14.2%和+16.2%。这表明GPT-4能够有效地处理越来越多的检索证据(包括相互矛盾的答案),并将其响应建立在最真实和最新的信息中。另一方面,将演示次数从5次增加到15次,会略微损害两种评估模式的准确性(STRICT下的总体准确性降低1%)。
为了评估每个演示中答案(包括推理)写作风格的影响,手动将这些答案重写为更详细的版本(长演示答案)。手动检查显示,在处理复杂问题时,用更详细的演示答案可能有帮助,但可能更有害,因为它为幻觉提供了空间(在STRICT下,总体准确率下降了2.6%)。
最后说一下局限性和未来方向。
FRESHQA的一个明显挑战是需要维护人员定期更新答案;在两次更新之间的过渡期内,一些问题的答案可能会变得过时。这可以通过开源社区的支持来解决(例如,通过GITHUB请求进行更新)。此外,STRICT模式下人为评估目前成本高昂,因为它需要验证每个生成回复的所有声明;这可以通过实现基于LLM的自动评估器来解决。在方法方面,FRESHPROMPT与GOOGLE SEARCH接口,目前尚不清楚它与其他搜索引擎的性能,因为某些类型的上下文(例如,答案框)不可用。此外,每个问题只执行一个搜索查询,因此该方法可以通过问题分解和多个搜索查询得到进一步改进(Khattab2022)。由于FRESHQA由相对简单的英语问题组成,因此还不清楚FRESHPROMPT在多语言/跨语言QA和长格式QA中的表现(Fan 2019)。最后,FRESHPROMPT依赖于上下文学习,因此可能不如那些根据新知识来微调基本LLM的方法。















 7476
7476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









