









24年6月来自浙江大学和阿里的论文“FlowBench: Revisiting and Benchmarking Workflow-Guided Planning for LLM-based Agents”。
基于 LLM 智体已成为一种有前途的工具,它们被设计成通过迭代规划和行动来完成复杂任务。然而,当缺乏专业知识密集型任务的具体知识时,这些智体容易受到不良规划幻觉的影响。为了解决这个问题,初步尝试通过整合外部工作流相关知识来提高规划可靠性。尽管前景光明,但这些注入的知识大多杂乱无章、格式各异,缺乏严格的形式化和全面的比较。
受此启发,将不同格式的工作流知识形式化,建立第一个工作流引导的规划基准 FlowBench。FlowBench 涵盖了 6 个领域的 51 种不同场景,知识以多种格式呈现。为了在 FlowBench 上评估不同的 LLM,设计一个多层次的评估框架。
如图是工作流引导智体规划的流程。向智体提供各种格式的工作流知识,并提示其规划下一步行动。
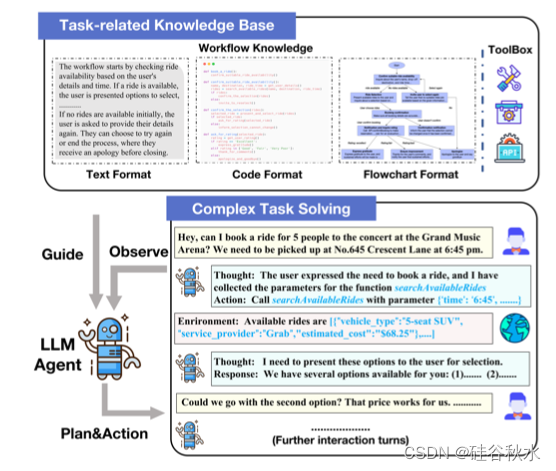
工作流相关知识是一组与流水线相关的事实表示,指对流程或任务在特定上下文(如业务或项目环境)中如何构建和执行的理解。不同工作流知识的内容主要分为以下几类:(i)操作流程相关,描述完成任务所需的步骤及其顺序。(ii)条件/规则相关,描述在满足某些条件或参数时应采取的行动。(iii)工具/数据相关,包含不同工具的使用技术和数据处理机制。
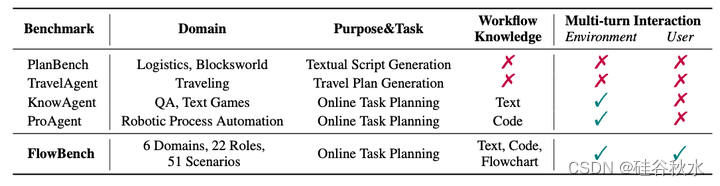
下表是FlowBench 与一些相关研究和基准的比较,包括 ProAgent(Ye et al.,2023)、PlanBench(Valmeekam et al.,2023)、TravelAgent(Xie et al.,2024)和 KnowAgent(Zhu et al.,2024)。
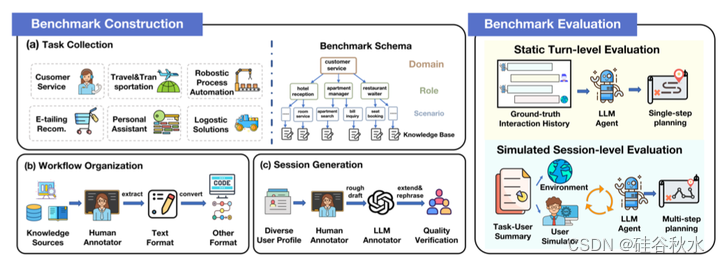
如图是FlowBench概览。基准架构采用自上而下的多层结构(域 - 角色 - 场景 - 知识)。左侧的基准构建过程包含三个阶段(a、b、c)。右侧的评估框架封装静态回合级和模拟会话级的评估。
FlowBench 由一系列下游域组成。每个域都包含一系列智体角色。这些角色中的每一个都由一组特定场景(即基本任务)进一步描述。每个场景都与相应的任务相关知识库相关,其中包括任务背景、工作流相关知识和要使用的工具集合。
图左描绘了一个全面的自上而下示例。在客户服务领域,配置了几个智体角色,包括餐厅服务员、酒店接待员和公寓经理。公寓经理的角色负责两个场景:公寓搜索和账单查询。然后,每个场景都与其任务相关的知识库相关。
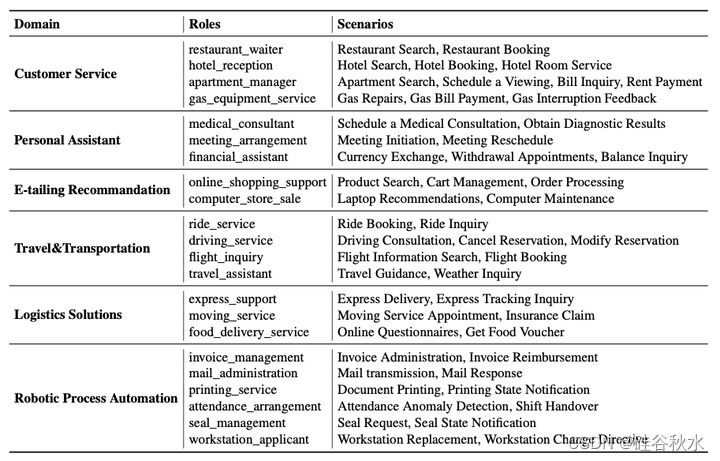
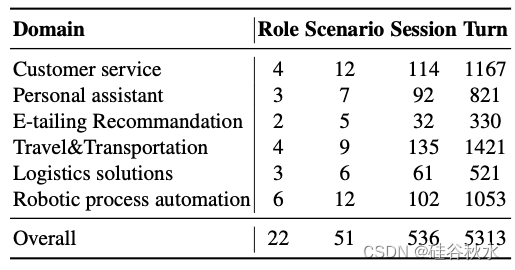
下表是FlowBench不同域和角色的详细场景介绍:
FlowBench 的构建流程分为三个阶段:场景收集、工作流组织和会话生成。
任务收集,对于有效评估工作流引导规划能力的基准来说,其多样性和广泛覆盖至关重要。为此,最初从现有工作(Mosig et al., 2020)中收集的任务中汲取灵感,并进一步进行广泛的扩展。任务收集面向个人客户和商业企业。
收集任务场景后,接下来描述每个场景工作流相关知识的提取和结构化。查阅一些现有的参考资料,例如专业知识语料库,例如WiKiHow(Koupaee and Wang,2018);工作流知识网站,例如Zapier(Zapier);和搜索引擎结果。
整合来自这些来源的信息,将与工作流相关的专业知识逐点总结成自然语言文档。然后需要不同的人工标注者独立验证这些知识文档的正确性、完整性和非冗余性。随后,用 GPT-4(Openai,2023b)将这些文本格式的知识按照指定的标准转换为代码和流程图格式,并结合人工验证以确保知识的一致性。
在构建工作流知识之后,继续组织工作流中涉及的工具调用信息。遵循 GPT-4 函数调用格式,概述每个工具调用的描述、输入/输出的参数以及每个参数的对应信息。
有了有组织的工作流相关知识后,接下来就是为每种场景合成真实的用户-智体交互会话。这些生成的会话将作为评估框架的先决条件。原则是增强生成会话的多样性和真实性。为了实现这一点,提示 GPT-4 在每种情况下生成不同的用户配置文件以增强多样性,其中包括用户背景、用户目标、响应语气(即响应风格)。为了确保数据真实性,进一步有意地将一些超出场景的项目(例如随意的闲聊和不相关的范围外意图)合并到用户配置文件中,以模拟现实世界的场景。
给定生成的用户配置文件,采用协作标注策略,为用户和智体端分配一对人工标注者和 LLM 标注者(GPT-4)。具体而言,对于每个交互回合,在用户端,人工标注者根据任务上下文和交互历史制作后续的用户意图和对话草稿,然后由 LLM 标注者验证和重新表述以匹配所需的响应语气。至于智体端,人工标注者利用工作流知识制定下一步行动规划并制作初始响应草稿,随后由 LLM 标注者审查和润色。这种协作生成过程不断迭代,直到整个会话被完全标注。
为了确保数据质量,在基准构建的每个阶段都加入人工验证。三名人工标注者参与质量验证过程。标注者的每个提交都将接受其余两名标注者的交叉验证。
下表是FlowBench的统计:
在构建基准之后,提出一个全面、多方面的评估框架。根据任务-觉察对评估场景进行分类,并提出静态和模拟评估两个不同的方面。
根据指定的任务场景是否先验已知,将评估场景分为单场景和跨场景评估。 (i) 单一场景评估,假设一个预先确定的任务场景。智体角色具备该场景的工作流知识,需要在这个单一任务场景中导航、计划和执行操作。 (ii) 跨场景评估,假设具体场景未知。智体角色配备了一套多功能的工作流知识,涵盖角色范围内的所有场景。智体需要灵活地规划和在不同场景之间切换。
关于评估框架,静态回合级评估基于生成的真值会话进行。具体来说,给定一个采样的真值会话 d,对于 d 中的每个回合 i,智体将获得来自 d 的前 (i − 1) 个回合的真值交互历史,然后提示其规划当前回合动作。接下来,预测动作 ai ̃ 和响应 ri ̃ 与真知 ai, ri 进行比较,进行评估。
现实场景按顺序规划和执行动作,为了更全面地评估其中的规划能力,提出一个模拟会话级评估框架。
具体来说,基于 GPT-4 构建一个用户模拟器。为了确保这个模拟用户的行为与人类一致,还依赖于生成的真实会话。通过 GPT-4 从每个会话中提取出一个任务用户摘要,其中包含任务背景、用户目标、工具调用信息。值得注意的是,这个任务用户摘要与生成的用户配置文件不同。用户目标总结了用户的所有目标,而工具调用信息概述了工具使用的预期参数和值。基于这个任务用户摘要,与模拟用户和待评估智体生成一个预测会话,以方便计算指标。
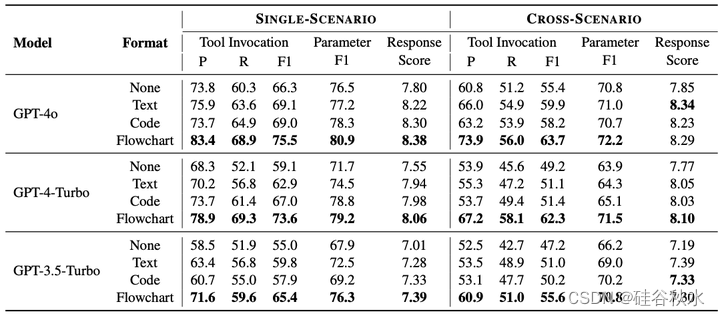
如表是在静态回合级评估下,配备不同格式工作流知识的不同 LLM 性能比较。其中粗体条目表示结果更优。
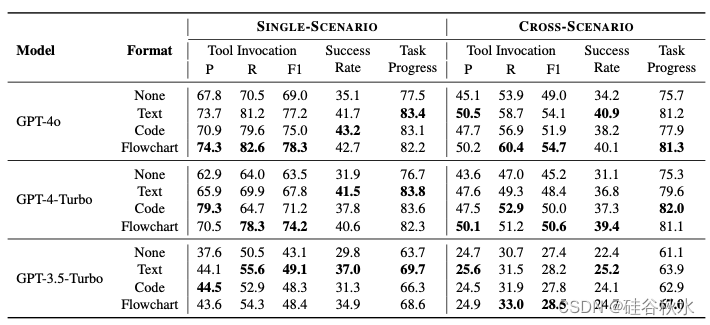
如表是在模拟会话级评估下,配备不同格式工作流知识的不同 LLM 的性能比较。其中粗体条目表示结果更优。















 387
387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









