









10月3号来自印度IIIT、加拿大UBC、爱萨尼亚的U Tartu、美国TensorTour公司和MIT的论文“Talk2BEV: Language-enhanced Bird’s-eye View Maps for Autonomous Driving“。
本文介绍Talk2BEV,一种用于自动驾驶环境中BEV的大型视觉语言模型(LVLM)接口。虽然现有的自动驾驶场景感知系统主要集中在一组预定义(封闭)的目标类别和驾驶场景上,但Talk2BEV将通用语言和视觉模型的最新进展与BEV结构化地图表示相结合,消除了对特定任务模型的需求。这使得单个系统能够满足各种自动驾驶任务,包括视觉和空间推理、预测交通参与者的意图以及基于视觉线索的决策。在大量场景理解任务中对Talk2BEV进行了广泛的评估,这些任务既依赖于理解自由式自然语言查询的能力,也依赖于将这些查询与嵌入的语言增强BEV图中的视觉上下文相结合的能力。为了能够对自动驾驶场景的LVLM进行进一步研究,作者开发并发布了Talk2BEV Bench,这是一个包含1000个人工标注BEV场景的基准,其中包含来自NuScenes数据集的20000多个问题和真值答案。
如图所示:Talk2BEV用(a)由车辆传感器(多视图图像、激光雷达)构建的BEV表示,以及(b)每个目标的对齐视觉-语言特征构建语言增强BEV图,这些特征可以直接用作大型视觉语言模型(LVLM)中的上下文,以查询场景中的目标并与之交谈。这些地图嵌入了关于目标语义、材料特性、可见性和空间概念的知识,可以查询视觉推理、空间理解和对潜在未来场景的决策。
如图是总体的Talk2BEV流水线:首先根据图像和激光雷达数据生成BEV图。然后用大型视觉语言模型(LVLMs)对每个目标对齐其图像语言特征来增强生成的BEV,由此构建语言增强地图。这些特征可以直接用作LVLM的上下文,用于回答目标级和场景级查询。对于BEV中的每个目标,将其投影到图像中(使用激光雷达-相机外参),提取边框,并用现成的LVLM为裁剪的边框加上字幕。语言增强地图中的每个目标现在都对几何线索(位置、面积、质心)和语义线索(目标和图像描述)进行编码。

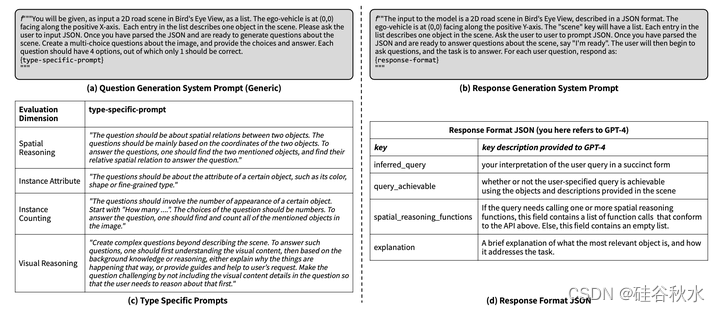
系统采用点-可查询的分割模型,如带有点提示(图像裁剪的中心)的FastSAM[42]来生成实例分割掩码。k个反向投影点用作点提示的正标签。对于每个分割掩码,裁剪一个紧密配合的边框,并将其传递给LVLM,生成裁剪的描述。在这个阶段,只将裁剪的边框通过视觉编码器获得图像语言特征,这些特征稍后可能作为上下文token传递到语言解码器中。每个目标的描述包含目标级别和场景级别的详细信息。然后,这些生成的元数据以文本条目的形式添加到BEV图中。如图是LLM系统提示例子:(a)LLM[9]的通用问题生成提示;(b) 生成响应的系统提示;(c) 详细说明为生成每个评估维度的问题而添加的特定类型命令;(d) 显示响应的格式JSON(JavaScript Object Notation),其给LLM提供简要解释,即如何填充JSON(key-value)对。
Talk2BEV系统可以处理多种类型的用户查询。这项工作将它们分类为自由形式的文本查询、有一个正确答案的多选题(MCQ)和空间推理查询(通过文本指定)。自由形式和空间推理查询模拟了Talk2BEV的自然终端用户界面,而MCQ允许按照SEEDBeach[18]中概述的协议进行客观评估。
与直接生成自由形式的文本输出相反,Talk2BEV中提示LLM生成要具有四个字段的JSON格式输出:(i)inferred-query,它首先重新表述用户查询,从而提供对该查询的内部解释;(ii)query achievable,指示该查询是否可实现。(iii)spatial reasoning functions,表示是否需要空间推理功能;以及(iv)explanation,包含LLM如何处理所提供任务的简要说明。上图的系统提示格式提供了双重优势:首先,它确保LLM传递组织成(key-value)对的信息。其次,它勾勒导致最终反应的中间步骤,最后实现思维链推理[45]。
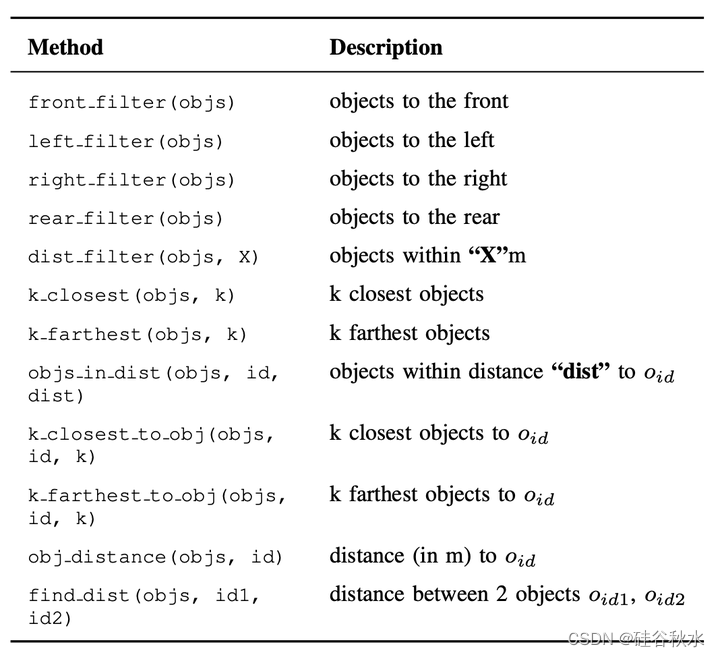
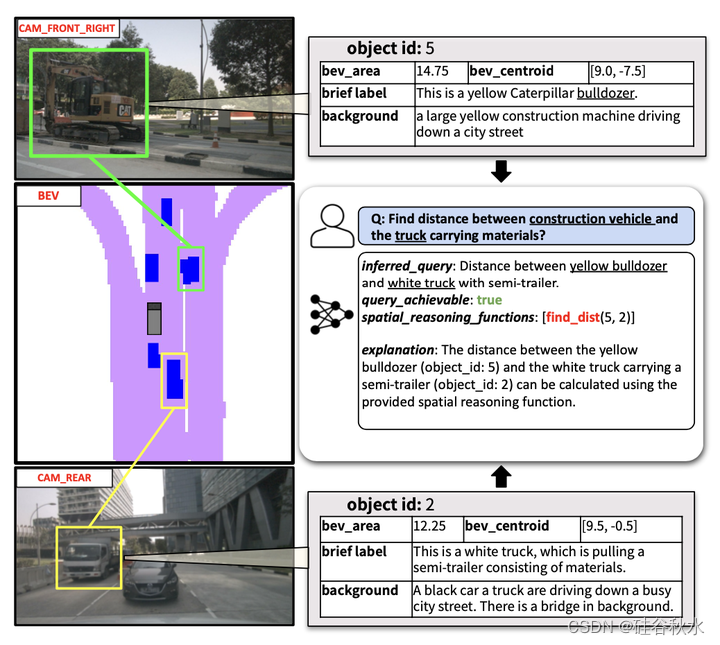
为了使LLM能够准确地执行空间推理,文中提供了对原空间运算符API的访问,如[46]。每当用户查询涉及空间推理(位置、距离、方向)时,都会指示模型生成直接调用这些空间运算符之一的API调用,而不是直接尝试生成输出。如表提供了这些空间运算符的完整列表。如图举例说明了空间运算符的用法。图中能够捕捉施工车辆和运输材料的卡车之间的距离。重要的是,这些车辆永远不会在同一个摄像头中共同可见,并且需要一张BEV地图来共同推理。
为了评估语言增强地图的质量,并评估该框架的空间理解和视觉推理能力,作者提出了Talk2BEV Bench,这是评估自动驾驶应用LVLM的第一个基准。从NuScenes数据集[35]中生成了1000个场景的真值语言增强地图,并以SEEDBBench[18]格式生成了20000多个经过人工验证的问答对。这些问题评估了对目标属性、实例计数、视觉推理、决策和空间推理的理解。
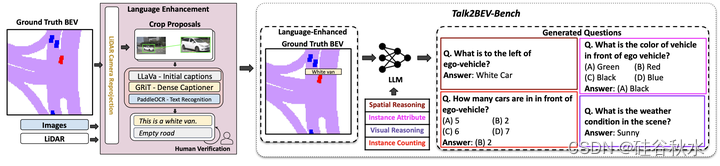
为了生成问题和答案,首先从NuScenes数据集中提取真值BEV地图,并获得地图中每个目标的字幕。字幕由人工标注员进行细化,之后用GPT-4为每个问题生成问题和初始回答。这些问题和回答再次由人工标注员进行验证,产生基准测试中MCQ的最终集。这种问答管理方法如图所示:为了开发这个基准,我用NuScenes Ground Truth BEV标注,并用密集字幕器(GRiT[43])和文本识别模型(PaddleOCR[44])生成目标和场景级别的描述。然后,真值BEV被传递给类似GPT4的LLM,生成各种问题,包括但不限于空间推理、实例属性、视觉推理和实例计数。
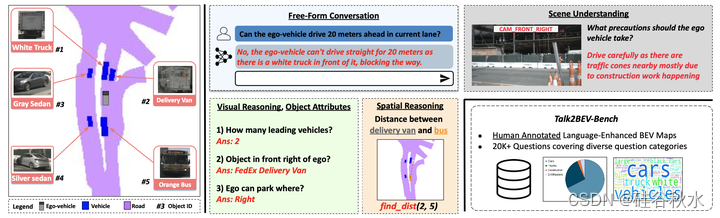
如图是Talk2BEV与用户进行自由形式对话的例子:自车前面有一辆车(红色突出显示),正在倒车停车;Talk2BEV识别出停车灯亮着,根据这些视觉信息和前车的空间位置,Talk2BEV认为继续前进是不安全的。
















 2435
2435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









