










24年10月来自UCSD、CMU和伯克利分校的论文“Lessons from Learning to Spin “Pens””。
用手操作笔状目标是日常生活中的一项重要技能,因为许多工具(例如锤子和螺丝刀)形状相似。然而,由于缺乏高质量的演示以及模拟和现实世界之间存在巨大差距,当前基于学习的方法难以完成这项任务。这项工作通过展示旋转笔状目标的能力,突破了基于学习的手工操作系统界限。首先使用强化学习来训练具有特别信息 oracle 策略,并在模拟中生成高保真轨迹数据集。这有两个目的:1)在模拟中预训练感官运动策略;2)在现实世界中进行开环轨迹重放。然后,我们使用这些现实世界轨迹对感官运动策略进行微调,以使其适应现实世界的动态。通过不到 50 条轨迹,策略学会了旋转多圈十多个具有不同物理特性的笔状目标。
如图所示:连续转动,和多样性的目标例子

灵巧手操作是各种下游操作任务的基础技能。例如,人们经常需要在使用工具之前重新调整手中的方向。尽管该领域已有数十年的活跃研究 [1、2、3、4],但手动操作仍然是一项重大挑战。尤其是操纵笔状目标被认为是最具挑战性和最关键的任务之一 [5、6]。此外,旋转笔状目标需要动态平衡和复杂的手指协调,使其成为推进灵巧操作系统的理想试验台。
笔旋转已从多个角度进行了研究。经典的机器人作品展示了具有开环力控制的旋转木块 [1]。借助高速摄像机和先进的硬件,也可以实现敏捷的笔旋转 [6]。但是,这些方法依赖于准确的目标模型,无法推广到未见过的目标。另一方面,基于学习的方法有望通过大规模数据进行推广。他们确实在模仿学习 [7、8、9] 或模拟到现实 [3、10、11、12] 方面取得了重大进展。然而,他们只展示了对规则球形或长方体形状目标的操纵,没有人能够将这种能力扩展到笔状目标。归因于两个原因:对于遥控操作模仿流水线,当前的遥控系统无法收集复杂而动态的演示;对于模拟-到-现实,弥合动态任务的差距变得相当困难。
经典的手中操作。手中操作已被研究了几十年[2,16]。经典方法依赖于精确的模型,并通过分析规划一系列动作来控制物体。例如,Han & Trinkle [17] 使用滑动、滚动和手指步态动作来操纵物体,而 Bai & Liu [18] 研究手指和手掌的协作。Mordatch [19] 通过轨迹优化演示了模拟中的物体旋转。Li [20] 学习了一种用于抓取和旋转物体的目标级阻抗控制器。开环操作也表现出令人惊讶的鲁棒性和灵巧的行为 [14,15]。Sieler & Brock [21] 使用线性反馈控制用一只软手进行手中操作。此类别中最先进的系统包括使用具有柔顺性的手 [22] 和精确的姿势跟踪器 [23] 进行完整的 SO(3) 重定向。然而,由于笔状目标的复杂性和动态性,大多数方法无法操纵它们。外部灵活性 [24] 也可用于实现动态操纵,但需要精确的模型。
基于学习的灵巧操作。基于学习的方法做出的假设较少,并且随着更多数据的获得,有望变得更具泛化性。最近,该领域取得了重大进展 [3, 4]。进步主要来自两个方面:1)低成本且易于访问的遥操作系统 [7, 8, 25, 26, 27, 28, 29, 30] 与模仿学习 [31, 32] 相结合;2)模拟中的强化学习 [33, 34] 与模拟-到-现实 [10, 11, 12, 34] 相结合。然而,这两种方法都有局限性。由于不可忽略的通信延迟和重定向误差,当前的遥操作无法支持旋转笔等敏捷和动态任务。另一方面,通过在随机环境中训练策略,模拟-到-现实方法表现出很好的泛化能力和鲁棒性。它们在多个领域取得了成功,例如手部操作 [13、35、36、37、38、39、40、41]、抓握 [42、43、44]、长距离任务 [45] 和双手灵巧性 [46、47]。然而,模拟和现实之间的差距相当大,一些结果仅限于模拟 [48、49、50]。
现实世界和模拟数据的结合。Torne [51] 和 Wang [52] 通过创建模拟环境来增强现实世界的人类演示,表明这有助于提高策略稳健性。Jiang [53] 证明,模拟-到-现实策略仅需少量人类演示即可适应现实世界的复杂动态。
转笔操作。由于转笔的挑战性和在现实世界中的实际意义,这一具体问题也得到了广泛的研究。Fearing [1] 展示了一种开环力控制策略,可以实现稳健的手指控制,以操纵长木块。Ishihara [6] 和 Nakatani & Yamakawa [5] 使用高速机械手和摄像头演示了高速转笔。在机器学习社区,Charlesworth & Montana [54] 展示了 RL 和轨迹优化的良好结果。Ma [55] 使用语言模型进行奖励设计。然而,结果仅限于模拟。将模拟结果带到现实世界是一项相当困难的任务。有些研究涉及使用现实世界的强化学习 [56] 或模仿增强 [57] 来学习操纵长物体,但它只能做不到半圈,而且没有手指控制。
如图显示本文方法概述。该方法包括三个步骤。首先,使用特别信息训练一个 oracle 策略,以在模拟中生成真实的轨迹。利用这些轨迹,在模拟中预训练一个感官运动策略。然后,用这些轨迹作为开环控制器在现实世界中生成演示,用于微调感官运动策略以使其适应现实世界的动态。
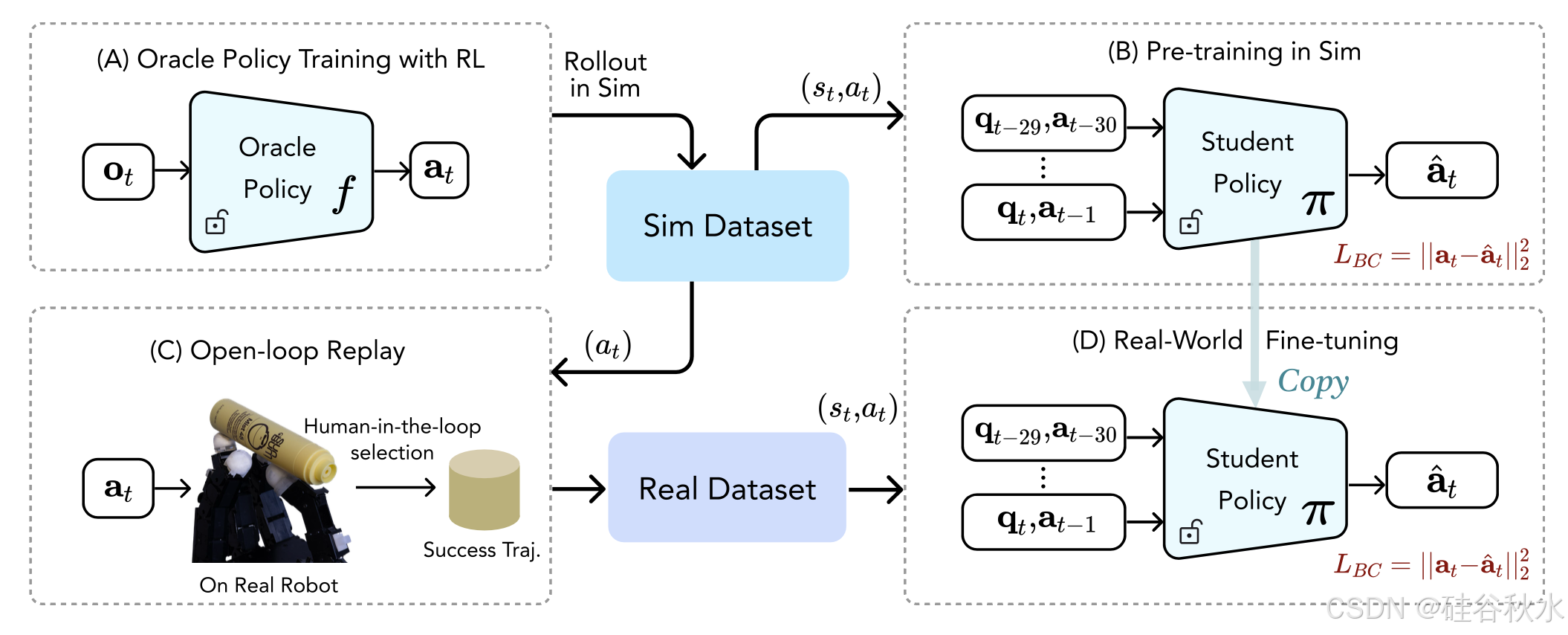
由于涉及动态和复杂的运动,获取用于旋转笔的高质量数据本身就是一项艰巨的任务。由于人手和机器人手之间存在不可忽略的延迟和不完美的重定位误差,当前的遥操作系统并不适用。另一方面,先前的研究表明,强化学习可以在模拟中合成复杂的行为 [54, 55]。这些方法实现了快速和动态的行为,但可能违反现实世界的物理和硬件约束。相反,本文方法生成高质量的轨迹,这些轨迹足够逼真,可用作现实世界中的开环控制器。这是通过适当设计输入空间、奖励函数和初始状态分布来实现的。
oracle策略训练
观测。Oracle 策略 f 的观测 o/t 是以下量的组合:关节位置 q/t、前一个关节位置目标 a/t-1、二进制触觉信号 c/t、指尖位置 p/t、笔的当前姿势和角速度 w/t,以及当前状态下笔的点云。为了获得细粒度的触觉响应,扩大 [12] 中的传感器排列,在每个指尖上包含五个二进制传感器。点云是通过基于当前真值目标姿势对原始网格上的点进行变换获得的。用 PointNet [58] 对笔目标的点云进行编码,就像 [35, 59, 60] 一样。将关节位置和目标的三个历史状态堆叠为输入。还在输入中包含质量、质心、摩擦系数和目标大小等物理属性 [11]。
动作。在每个步骤中,策略网络 f(o/t) 提供的动作都是相对目标位置。位置命令 a/t = ηf(o/t) + a/t−1(其中 η 是动作尺度)被发送到机器人,并通过低级 PD 控制器将其转换为扭矩。
奖励设计。策略的目标是围绕 z 轴连续旋转笔。奖励定义为旋转奖励和一些能量惩罚项组合。奖励和惩罚项遵循 [11, 12]。然而,稳定的步态并非仅由此产生。受 [54] 的启发,提出另一个奖励 r/z,即关于笔上最高点和最低点之间高度差的惩罚,鼓励机械手在旋转过程中保持笔的水平状态。
初始状态设计。以前的工作是将物体放在手掌 [12, 13]、桌子 [10] 或指尖上 [11],在这些情况下,物体有自然支撑。因此,用随机采样的姿势并不能提供有意义的探索。正确设计初始状态分布对于策略训练至关重要。设计旋转笔的初始状态,并非易事,因为初始抓握应该足够稳定,以便于学习后续的运动步骤。此外,如果在重置时重复使用相同的初始状态,探索可能会很慢。因此,受人类行为的启发,手动设计可能在旋转笔周期中出现的多种抓握模式(如图所示),然后添加噪声以生成和过滤一组稳定的初始状态。

策略优化。用近端策略优化 (PPO) [61] 来训练 oracle 策略。给定状态信息,对策略和价值网络都使用多层感知器 (MLP)。对感知输入、物理参数、目标属性等应用域随机化。当重置条件满足或智体达到最大步数 T 时,episodes终止。当笔低于高度阈值时,会修剪不必要的探索。
感官运动的策略预训练
oracle 策略可以在模拟训练期间学习平滑和动态的行为。但是,它无法部署,因为它需要特别信息作为输入,而这在现实世界中是无法访问的。以前的研究通常使用 DAgger [62] 将 oracle 策略提炼为感官运动策略。但是,这种方法对转笔任务效果不佳。而本体感受 [11] 或添加视觉触觉反馈 [13, 35]。虽然带有视觉触觉反馈的策略可以在模拟中学习合理的行为,但对于这两种模式来说,模拟和现实之间的不匹配太大。另一方面,本体感受反馈是模拟和现实世界之间最相似和最可靠的感知方法,但本体感受策略即使在模拟中也无法收敛,并且总是在前几步中掉落物体。
因此,有一种替代方法:在模拟中推出 oracle 策略 f,这与之前使用 DAgger 并推出感官运动策略 [11, 35] 的工作不同,并收集本体感受和动作 (st, at) 的数据集。该数据集用于在模拟中预训练本体感受策略。此步骤的目标是将感官运动策略暴露给不同的训练数据。虽然使用此类数据进行训练由于动态不准确而无法直接转移到现实世界,但它可以提供运动先验,从而允许使用现实世界的轨迹对策略进行有效微调。
按照 [11],本体感受策略以 30 步关节位置 q/t−29:t 和之前的关节目标位置 a/t−30:t−1 作为输入。用类似于 [35] 中使用的时间transformer来建模顺序特征和用于策略网络的 MLP。这种预训练使本体感受策略能够体验更广泛的情况,从而防止过拟合特定的轨迹。
使用 Oracle 重播放微调感官运动策略
由于任务与现实之间存在很大差距,用真实世界的轨迹来微调预训练的感官运动策略,以适应真实世界的动态。然而,获得真实世界的轨迹具有挑战性。虽然 Oracle 策略不能直接蒸馏并零样本迁移到现实世界,但它确实提供了难以使用远程操作生成的运动序列。受到最近强调开环控制器对于手部操作有效性研究的启发 [14, 15],用 Oracle 策略生成的轨迹作为现实世界中的开环控制器。
具体来说,在训练完 Oracle 策略 f 之后,在具有不同初始姿势的模拟环境中对其进行测试。从不同的初始姿势中选择了 15 条持续时间超过 800 个时间步长的轨迹。记录这些动作,并在具有三个训练目标的真实机器人上重放。对于每次重放,随机选择 15 条轨迹中的一条。如果此开环控制器在本次试验中可以将物体旋转超过 2π,将此轨迹存储在数据集中。重复此过程,直到为每个目标收集了 15 条轨迹(总共 45 条轨迹)。
使用学习的策略来生成此类轨迹有两个好处:首先,它自然提供了由奖励定义驱动的平滑度;其次,与从人类视频中学习等替代方法相比,它提供了带有动作的轨迹数据。用此数据集来微调本体感受策略 π,使其适应现实世界的动态。由于本体感受策略已经在不同的模拟环境中进行了预训练,因此它可以用少于 50 条的轨迹适应现实世界。
用 Allegro Hand 进行硬件实验。Allegro Hand 有四个手指,每个手指有 4 个自由度。神经网络以 20 Hz 输出关节位置目标,并将其发送到以 333 Hz 运行的低级 PD 控制器。
用 Isaac Gym [34] 进行模拟训练。为了获得额外的触觉反馈进行 oracle 策略训练,在指尖周围模拟了 20 个触觉传感器,每个指尖有 5 个。从每个传感器收集接触信号,并根据预定义的阈值对测量结果进行二值化 [12, 13]。在模拟中,控制频率为 20 Hz,模拟频率为 200 Hz。

















 304
304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









