







欢迎关注『youcans论文精读』系列
本专栏内容和资源同步到 GitHub/youcans
【youcans论文精读】何恺明:分形生成模型 (Fractal Generative Models)
0. 论文简介
0.1 论文背景
2025年,MIT 何恺明 等发表论文 “Fractal Generative Models(分形生成模型)”,首次将分形理论引入生成模型,提出了一种具有自相似性的递归生成框架。
Tianhong Li, Qinyi Sun, Lijie Fan, Kaiming He, “Fractal Generative Models”, doi:10.48550/arXiv.2502.17437
【论文下载】:arxiv
【GitHub地址】:Github-fractalgen
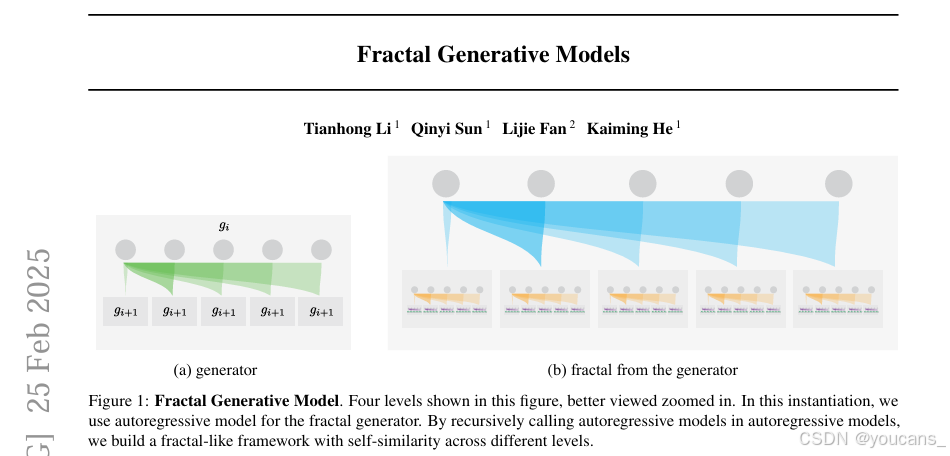
图1:分形生成模型。
在这个图中显示了四个层次,可以更好地放大视图。在这个实例化中,我们对分形生成器使用自回归模型。通过递归地调用自回归模型中的自回归模型,我们建立了一个在不同层次上具有自相似性的类分形框架。
0.2 总结速览
-
提出的方案
- 分形生成模型:
提出了一种新的生成模型框架,通过递归调用相同类型的生成模块来构建分形生成模型。这种模型具有自相似性,能够在不同层次上表现出复杂的结构。 - 自回归模型作为生成器:
以自回归模型为例,展示了如何将分形生成模型应用于像素级图像生成任务。每个自回归模块由多个子自回归模块组成,形成分形结构。
- 分形生成模型:
-
达到的效果
- 高性能生成:
在像素级图像生成任务中,分形生成模型在似然估计和生成质量方面表现出色。 - 复杂结构建模:
能够有效建模具有内在结构的非顺序数据,如图像、分子结构和蛋白质。 - 新研究范式:
为生成模型的设计和应用提供了新的研究方向,有望推动生成模型领域的进一步发展。
- 高性能生成:
0.3 摘要
模块化是计算机科学的基石,它将复杂功能抽象为原子构建块。本文将模块化理念提升至新高度——通过将生成模型抽象为原子生成模块。
类似于数学中的分形结构,我们的方法通过递归调用原子生成模块构建新型生成模型,形成具有自相似特征的分形架构,即分形生成模型。
作为范例研究,我们以自回归模型为原子生成模块实例化该分形框架,并在像素级图像生成这一挑战性任务上验证其性能,实验表明该方法在似然估计和生成质量方面均表现优异。
本研究有望开创生成建模新范式,为未来研究提供新思路。项目代码详见https://github.com/LTH14/fractalgen。
1. 引言
计算机科学的核心在于模块化理念。例如深度神经网络由作为模块化单元的原子"层"构成(Szegedy等人,2015)。类似地,现代生成模型——如扩散模型(Song等人,2020)和自回归模型(Radford等人,2018)——均由原子"生成步骤"构建,每个步骤通过深度神经网络实现。通过将复杂功能抽象为这些原子构建块,模块化使我们能通过组合这些模块创建更复杂的系统。
基于此理念,**我们提出将生成模型本身抽象为模块以开发更先进的生成模型。**具体而言,**我们引入一种通过递归调用同类生成模型构建的生成模型。**如图1所示,这种递归策略产生的生成框架在不同模块层级间展现出具有自相似性的复杂架构。
我们的提案类似于数学中的分形概念(Mandelbrot,1983)。分形是通过称为生成元的递归规则构建的自相似图案。同样,我们的框架也通过"在生成模型中调用生成模型"的递归过程构建,在不同层级间呈现自相似性。因此,我们将该框架命名为"分形生成模型"。
1 Mandelbrot (1983) 使用了 “生成器(generator)” 的概念。本文中 的"生成器(generator)"特指递归形成分形的规则。
分形或近分形是生物神经网络中的常见模式。多项研究证实了大脑及其功能网络中存在分形或尺度不变的小世界网络组织(Bassett等人,2006;Sporns,2006;Bullmore & Sporns,2009)。这些发现表明大脑发育很大程度上采用了模块化理念,通过递归方式从小型神经网络构建更大网络。
除生物神经网络外,自然数据常呈现分形或近分形模式。常见分形涵盖从云朵、树枝、雪花等宏观结构,到晶体(Cannon等人,2000)、染色质(Mirny,2011)和蛋白质(Enright & Leitner,2005)等微观结构。更广义而言,自然图像也可类比为分形——例如图像由本身也是图像(尽管可能遵循不同分布)的子图像构成。相应地,图像生成模型可由本身也是图像生成模型的模块构成。
我们提出的分形生成模型受生物神经网络和自然数据中分形特性的启发。与自然分形结构类似,我们设计的核心是定义递归生成规则的生成元。例如如图1 所示,该生成元可以是自回归模型。在此实例中,每个自回归模型由本身也是自回归模型的模块构成。具体而言,每个父自回归块会衍生多个子自回归块,而每个子块又会进一步衍生更多自回归块,最终形成跨层级呈现类分形自相似模式的架构。
我们在一个极具挑战性的测试平台上验证该分形实例:逐像素图像生成。由于图像不具备明确序列顺序,直接建模像素序列的现有方法在似然估计和生成质量上均未取得理想结果(Hawthorne等人,2022;Yu等人,2023)。尽管难度很高,逐像素生成代表了一类更重要的生成问题:对具有内在结构的非序列数据进行建模,这对分子结构、蛋白质和生物神经网络等许多非图像数据类型尤为重要。
我们提出的分形框架在此重要而艰巨的任务中展现出强大性能。它能逐像素生成原始图像(图2),同时实现精确的似然估计和高质量的生成。希望这些积极成果能促进分形生成模型设计与应用的进一步研究,最终确立生成建模的新范式。

图2:我们的分形框架可以逐像素生成高质量的图像。我们通过递归调用自回归模型中的自回归模型来展示256 × 256图像的生成过程。我们还在我们的GitHub资源库中提供了示例视频来说明生成过程。
2. 相关工作
分形(Fractals)
分形是一种具有跨尺度自相似特征的几何结构,通常通过称为"生成元"的递归生成规则构建(Mandelbrot, 1983)。这类结构在自然界中广泛存在,经典案例既包含云朵、树枝、雪花等宏观形态,也涵盖晶体(Cannon等人,2000)、染色质(Mirny,2011)与蛋白质(Enright & Leitner,2005)等微观构造。
除这些易辨识的分形外,许多自然数据还呈现近分形特征。尽管不具备严格自相似性,它们仍体现类似的多尺度表征或模式,如图像(Freeman等人,1991;Lowe,1999)与生物神经网络(Bassett等人,2006;Sporns,2006;Bullmore & Sporns,2009)。从概念上讲,我们的分形生成模型天然适配所有具有内在结构且展现跨尺度自相似性的非序列数据;本文将通过图像生成实例验证其能力。
由于递归生成规则的特性,分形本质具有层次化结构,这与计算机视觉中的分层设计原则存在概念关联。但现有视觉分层方法既未融入分形构建的核心递归或分治范式,也未在设计中体现自相似性。这种层次结构、自相似性与递归特性的独特组合,正是我们的分形框架区别于下文所述分层方法的本质特征。
层次化表征(Hierarchical Representations)
从视觉数据提取层次化金字塔表征长期是计算机视觉的重要课题。早期手工特征(如Steerable Filters、Laplacian Pyramid和SIFT)利用尺度空间分析构建特征金字塔(Burt & Adelson,1987;Freeman等人,1991;Lowe,1999;2004;Dalal & Triggs,2005)。在神经网络领域,分层设计对捕获多尺度信息仍至关重要——如SPPNet(He等人,2015)和FPN(Lin等人,2017)通过金字塔特征图构建多尺度特征层次。我们的分形框架也与Swin Transformer(Liu等人,2021)相关,后者通过不同尺度的局部窗口注意力构建层次化特征图。这些层次表征在图像分类、目标检测和语义分割等理解任务中已被证实有效。
层次化生成模型(Hierarchical Generative Models)
分层设计在生成建模中同样应用广泛。近期方法多采用两阶段范式:先用预训练分词器将图像映射到紧凑隐空间,再对隐码进行生成建模(van den Oord等人,2017;Razavi等人,2019;Esser等人,2021;Ramesh等人,2021)。MegaByte(Yu等人,2023)则采用包含全局模块与局部模块的双尺度模型,以更高效地对长像素序列进行自回归建模,但其性能仍受限。
另一研究方向聚焦尺度空间图像生成。级联扩散模型(Ramesh等人,2022;Saharia等人,2022;Pernias等人,2023)通过多个扩散模型逐步从低分辨率生成高分辨率图像。最新尺度空间自回归方法(Tian等人,2024;Tang等人,2024;Han等人,2024)使用自回归Transformer逐尺度生成token。但这些方法若不经分词器直接生成图像,会因每尺度大量token/像素导致注意力计算成本呈平方增长而难以实现。
模块化神经网络设计(Modularized Neural Architecture Design)
模块化作为计算机科学与深度学习的基础理念,将复杂功能原子化为简单模块单元。早期模块化架构GoogleNet(Szegedy等人,2015)通过"Inception模块"引入新组织层级。后续研究衍生出残差块(He等人,2016)和Transformer块(Vaswani,2017)等广泛使用的单元。近期生成建模领域,MAR(Li等人,2024)将扩散模型模块化为原子单元以建模连续token分布,实现了连续数据的自回归建模。模块化通过提供更高抽象层级,使我们能基于现有方法构建更复杂的神经架构。
分形网络的先驱。FractalNet(Larsson等人,2016)是首个将模块单元递归调用并融合分形概念的神经架构设计,通过简单扩展规则的递归调用构建深度网络。虽然FractalNet与我们"递归调用模块单元形成分形结构"的核心思想一致,但存在两点关键差异:其一,其模块单元是小型卷积层块,而我们采用完整生成模型,体现不同层级的模块化;其二,FractalNet专为分类任务设计,仅输出低维logits,而我们的方法利用分形模式的指数级扩展特性,可生成海量输出(如百万级图像像素),展现了分形设计在分类以外更复杂任务中的潜力。
3. 分形生成模型(Fractal Generative Models)
分形生成模型的核心思想是通过递归调用现有原子生成模块构建更高级的生成模型。本节首先阐述分形生成模型的顶层设计动机与内在机理,随后以自回归模型为示例性原子模块,展示如何实例化分形生成模型并将其用于超高维数据分布建模。
3.1 设计动机与理论基础
分形是由简单递归规则涌现的复杂几何图案(Mandelbrot, 1983)。在分形几何中,这些规则被称为"生成元"。通过不同的生成元,分形方法可构建云朵、山脉、雪花、树枝等自然图案,并能模拟生物神经网络结构(Bassett等, 2006;Sporns, 2006;Bullmore & Sporns, 2009)、非线性动力学系统(Aguirre等, 2009)以及混沌系统(Mandelbrot等, 2004)等更复杂的体系。
形式化定义中,分形生成元 g i g_i gi 规定了如何基于上级生成元的输出 x i x_i xi,生成下一级的新数据集合 { x i + 1 } \{x_{i+1}\} {xi+1},即满足 { x i + 1 } = g i ( x i ) \{x_{i+1}\} = g_i(x_i) {xi+1}=gi(xi) 。如图1所示,通过在每个灰色框内递归调用相似生成元,即可构建完整分形结构。
由于每级生成元能从单一输入产生多个输出,分形框架仅需线性递归层级即可实现生成结果的指数级增长。这一特性使其特别适合用较少生成层级建模高维数据。
具体而言,我们提出将原子生成模块作为参数化分形生成元构建分形生成模型,使神经网络能够直接从数据中"学习"递归规则。通过结合分形输出的指数增长特性与神经生成模块,我们的分形框架实现了高维非序列数据的建模。下文将展示如何以自回归模型作为分形生成元实例化该思想。
3.2 作为分形生成元的自回归模型
本节阐述如何用自回归模型作为分形生成元构建分形生成模型。
我们的目标是建模大量随机变量
x
1
,
⋅
⋅
⋅
,
x
N
x_1, ··· , x_N
x1,⋅⋅⋅,xN 的联合分布,但直接用单一自回归模型进行建模在计算上是不可行的。为此,我们采用分治策略,其核心模块化思想是将自回归模型抽象为建模概率分布
p
(
x
∣
c
)
p(x|c)
p(x∣c) 的模块单元。基于此模块化,我们可通过在多个次级自回归模型之上构建更强大的自回归模型。
假设每个自回归模型的序列长度为可控常数 k k k,总变量数 N = k n N = k^n N=kn,其中 n = l o g k ( N ) n = log_k (N) n=logk(N)表示分形框架的递归层级数。分形框架的第一级自回归模型将联合分布划分为 k k k 个子集,每个包含 k n − 1 k^{n−1} kn−1 个变量。形式化表示为:
p ( x 1 , ⋅ ⋅ ⋅ , x k n ) = ∏ i = 1 k p ( x ( i − 1 ) ⋅ k n − 1 + 1 , ⋅ ⋅ ⋅ , x i ⋅ k n − 1 ∣ x 1 , ⋅ ⋅ ⋅ , x ( i − 1 ) ⋅ k n − 1 ) p(x_1, ··· , x_{k^n} ) = \prod ^k_{i=1} p(x_{(i−1)·k^{n−1}+1}, ··· , x_{i·k^{n−1}} |x_1, ···, x_{(i−1)·k^{n−1}} ) p(x1,⋅⋅⋅,xkn)=∏i=1kp(x(i−1)⋅kn−1+1,⋅⋅⋅,xi⋅kn−1∣x1,⋅⋅⋅,x(i−1)⋅kn−1)
每个包含 k n − 1 k^{n−1} kn−1 个变量的条件分布 p ( ⋅ ⋅ ⋅ ∣ ⋅ ⋅ ⋅ ) p(··· | ··· ) p(⋅⋅⋅∣⋅⋅⋅) 由第二递归层级的自回归模型建模,以此类推。通过递归调用该分治过程,我们的分形框架仅需 n n n 层自回归模型(每层处理可控长度 k k k 的序列)即可高效建模 k n k^n kn 个变量的联合分布。
该递归过程体现了标准分治策略。通过递归分解联合分布,分形自回归架构不仅较单一大型自回归模型显著降低计算成本,同时捕获了数据内在的层次化结构。从概念上讲,只要数据具有可分治组织的结构,就能自然适配我们的分形框架。为具体说明,下一节我们将该方法应用于逐像素图像生成这一挑战性任务。
4. 图像生成实例
本节通过逐像素图像生成这一挑战性任务,具体实现分形生成模型。虽然本文以图像生成为测试平台,但该分治架构同样适用于其他数据领域。我们首先探讨逐像素图像生成的挑战与重要性。
4.1 逐像素图像生成
由于原始图像数据的高维性与复杂性,逐像素生成仍是生成建模领域的重大挑战。该任务要求模型能高效处理海量像素,同时有效学习像素间丰富的结构模式与依赖关系。因此,逐像素生成已成为一个关键基准测试——现有方法大多仍局限于似然估计,无法生成令人满意的图像(Child等人,2019;Hawthorne等人,2022;Yu等人,2023)。
尽管极具挑战性,逐像素生成代表了一类更广泛的高维生成问题。这类问题需要逐元素生成数据,但与长序列建模不同,其数据通常不具备序列结构。例如分子构型、蛋白质和生物神经网络等结构虽无序列特征,却具有高维结构化数据分布。我们选择逐像素图像生成作为分形框架的实例,不仅旨在解决计算机视觉的核心挑战,更为了证明该框架在建模具有内在结构的高维非序列数据方面的潜力。
4.2 架构设计
如图3 所示,每个自回归模型将上级生成元的输出作为输入,并为下级生成元生成多个输出。
模型接收图像(可以是原始图像的局部块),将其分割为小块并嵌入形成Transformer的输入序列。这些图像块同时被送入对应的下级生成元。
Transformer将上级生成元的输出作为独立token置于图像token之前,基于该组合序列为下级生成元生成多个输出。
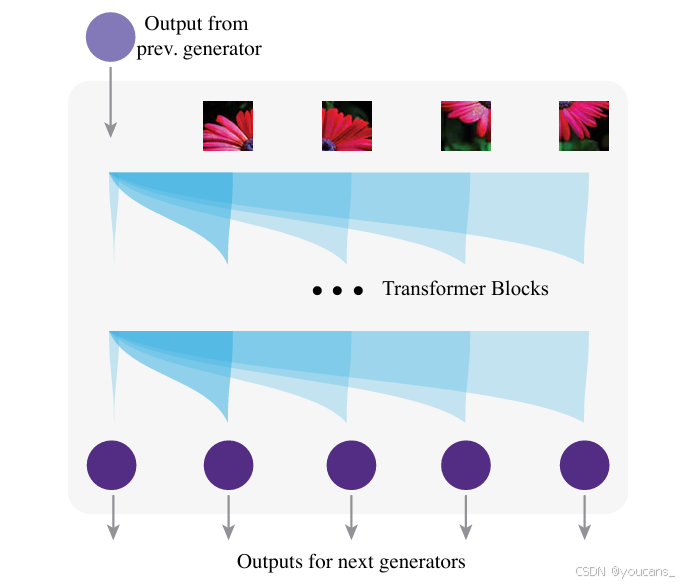
图3:我们的分形方法在逐像素图像生成上的实例化。在每个分形层次中,一个自回归模型接收上一个生成器的输出,并将其与对应的图像块串联,使用多个变压器块为下一个生成器产生一组输出。
遵循视觉Transformer和图像生成模型的通用实践(Dosovitskiy等人,2020;Peebles & Xie,2023),我们将第一级生成元 g 0 g_0 g0 的序列长度设为256,将原始图像划分为16×16的块。第二级生成元对每个块建模后进一步细分,该过程递归进行。为控制计算成本,随着块尺寸减小,我们逐步降低 Transformer 的宽度和层数——因为小块的建模通常比大块更简单。最终级使用轻量级Transformer自回归地建模每个像素的RGB通道,并对预测结果施加256路交叉熵损失。表1 详细列出了不同递归层级和分辨率下各Transformer的具体配置与计算成本。值得注意的是,我们的分形设计使256×256图像建模成本仅为64×64图像的两倍。
参考Li等人(2024)的工作,我们的方法支持不同自回归设计。本文主要考虑两种变体:类似GPT的栅格顺序因果Transformer(AR)和类似BERT的随机顺序双向Transformer(MAR)(图6)。两种设计均遵循"下一token预测"的自回归原则,各有优劣(详见附录B)。我们将使用AR变体的框架称为FractalAR,MAR变体称为FractalMAR。
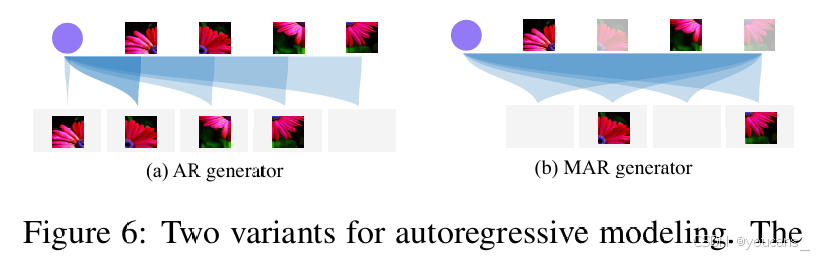
图6:自回归模型的两个变体。AR变体使用因果转换器以光栅扫描顺序对序列进行建模,而MAR变体使用双向转换器以随机顺序对序列进行建模。两者都是构建我们分形框架的有效生成器。
4.3 与尺度空间自回归模型的关系
近期提出的若干模型通过"下一尺度预测"进行自回归图像生成(Tian等人,2024;Tang等人,2024;Han等人,2024)。这些尺度空间自回归模型与我们的方法存在本质区别:它们使用单一自回归模型逐尺度预测 token,而我们的分形框架采用分治策略,通过生成子模块递归建模原始像素。另一关键区别在于计算复杂度——尺度空间模型生成下一尺度token时需对整个token序列进行全局注意力计算,导致计算复杂度显著升高。
例如生成256×256分辨率图像时,尺度空间模型在最细尺度的注意力矩阵大小达 (256×256)²=4,294,967,296。而我们的方法在建模像素间依赖时仅处理极小图像块(4×4),每个块的注意力矩阵仅(4×4)²=256,总计算量为(64×64)×(4×4)²=1,048,576次运算。这使得我们的方法在最细分辨率下计算效率提升4000倍,首次实现了高分辨率图像的逐像素建模。
4.4 与长序列建模的关系
先前工作大多将逐像素生成视为长序列建模问题,并采用语言建模方法解决(Child等人,2019;Roy等人,2021;Ren等人,2021;Hawthorne等人,2022;Yu等人,2023)。然而图像等数据的本质结构远超一维序列范畴。与这些方法不同,我们将此类数据视为由多个元素构成的集合(而非序列),采用分治策略递归建模更小的元素子集。这一设计的动机在于:此类数据往往具有近分形结构——图像由子图像构成,分子由子分子构成,生物神经网络由子网络构成。因此,处理此类数据的生成模型理应由本身也是生成模型的子模块构成。
4.5 实现细节
我们简要说明分形图像生成框架的训练与生成流程,更多超参数细节见附录A。
训练过程:
通过广度优先遍历分形架构,端到端地训练模型处理原始图像像素。
训练时,每个自回归模型接收上级模型的输出,并生成一组输出作为下级模型的输入。该过程持续至最底层,此时图像被表示为像素序列。最终级自回归模型基于每个像素的输出,以自回归方式预测RGB通道。
我们对预测logits计算交叉熵损失(将RGB值视为0-255的离散整数),并将损失反向传播至所有层级的自回归模型,实现端到端训练。
生成过程:
如图2所示,模型以深度优先顺序逐像素生成图像。
此处以MAR(Li等人,2024)的随机顺序生成方案为例:第一级自回归模型建模16×16图像块间的依赖关系,逐步生成下级模型所需的输出;第二级模型基于这些输出建模每个16×16块内4×4块间的依赖;第三级模型同理建模4×4块内像素间的依赖;最终级自回归模型从预测的RGB logits中采样实际RGB值。
5. 实验
我们在ImageNet数据集(Deng等人,2009)上进行了64×64和256×256分辨率的全面实验,评估范围涵盖无条件与类条件图像生成的似然估计、保真度、多样性和生成质量。
我们报告了负对数似然(NLL)、Fréchet Inception距离(FID)(Heusel等人,2017)、Inception分数(IS)(Salimans等人,2016)、精确度和召回率(Dhariwal & Nichol,2021)以及可视化结果,以全面评估我们的分形框架。
5.1 似然估计性能
首先在无条件ImageNet 64×64生成任务上评估模型的似然估计能力。
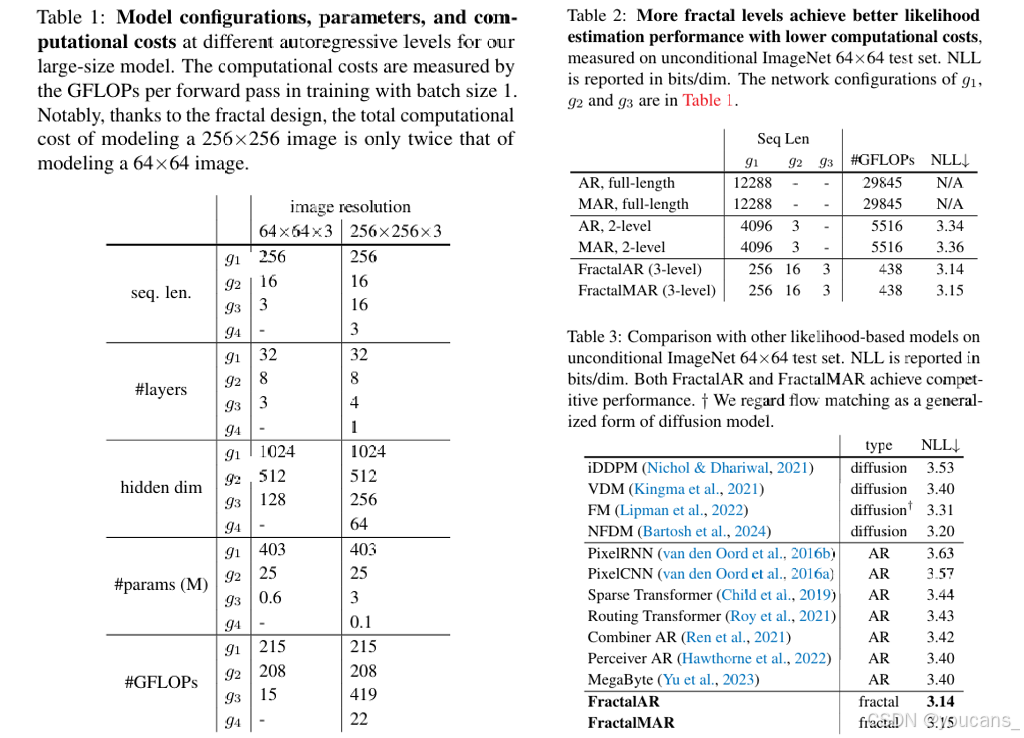
为了检验我们分形框架的有效性,我们比较了具有不同分形层级数的框架的似然估计性能,如表2所示。
- 使用单一自回归模型建模整个12,288像素序列(64×64×3)会导致计算成本过高而无法训练。
- 两级分形框架(首层建模全图像素序列,次层建模RGB通道)的计算量是三级分形模型的10倍以上
- 采用更多分形层级不仅计算效率更高,而且改善了似然估计性能,这可能是因为它更好地捕捉了图像的内在层次结构。
这些结果证明了我们分形框架的效率和有效性。我们在表5中进一步将我们的方法与其他基于似然的模型进行比较。我们的分形生成模型通过因果和掩码自回归分形生成元的实例化,实现了强大的似然性能。特别是,它实现了3.14 bits/dim的负对数似然,显著优于之前最佳的自回归模型(3.40 bits/dim),并与先进的扩散模型性能相当。
这些发现证明了我们分形框架在逐像素图像生成这一挑战性任务上的有效性,突出了其在建模高维非序列数据分布方面的潜在优势。
5.2 生成质量评估
我们在256×256分辨率的类条件图像生成这一挑战性任务上评估了FractalMAR模型,采用四级分形结构。
如表4所示,我们按照标准实践报告了FID(Frechet Inception Distance)、Inception Score、Precision和Recall等标准指标来评估其生成质量。具体而言,FractalMAR-H模型取得了FID 6.15和Inception Score 348.9的成绩,在单个Nvidia H100 PCIe GPU上以1024的批量大小评估时,平均每张图像生成耗时1.29秒。值得注意的是,我们的方法在Inception Score和Precision指标上表现优异,表明其能够生成具有高保真度和精细细节的图像(如图4所示)。然而,其FID和Recall指标相对较弱,说明生成的样本多样性较其他方法有所不足。我们推测这是由于逐像素建模近20万个像素的巨大挑战所致。尽管如此,这些结果凸显了我们的方法不仅在准确似然估计方面,而且在高质量图像生成方面的有效性。
我们进一步观察到一个积极的扩展趋势:将模型参数量从1.86亿增加到8.48亿,FID从11.80显著提升至6.15,Recall 从0.29提升至0.46。我们预期进一步扩大模型规模可以继续缩小FID和Recall的差距。与依赖分词器的模型不同,我们的方法避免了分词过程带来的重建误差,这表明随着模型容量的增加,性能提升具有无限潜力。
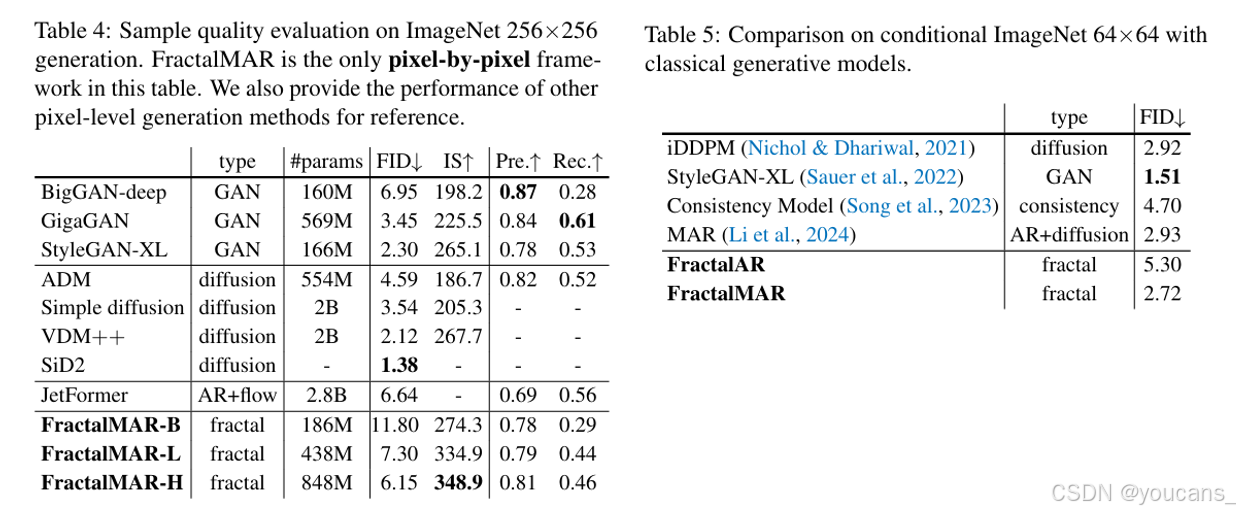

图4:FractalMAR - H在ImageNet 256 × 256上逐像素生成的结果。我们的分形方法能够以逐像素的方式生成高质量的高分辨率图像,平均每幅图像的吞吐量为1.29秒。更多的定性结果见图7。
5.3 条件式逐像素预测
我们通过常规图像编辑任务进一步检验了方法的条件式逐像素预测性能。
图5展示了多个示例,包括图像修复、外绘、去裁剪和类条件编辑。如图所示,我们的方法能够基于未掩码区域准确预测被掩码的像素。此外,它还能有效捕捉类别标签的高级语义特征,并将其反映在预测像素中。这一点在类条件编辑示例中得到了体现:模型通过输入狗的类别标签条件,成功将猫的脸部替换为狗的脸部。这些结果证明了我们的方法在已知条件下预测未知数据的有效性。
更广泛地说,通过逐元素生成数据,我们的方法提供了相比扩散模型或在潜空间操作的生成模型更具可解释性的生成过程。这种可解释的生成过程不仅让我们更好地理解数据生成机制,还提供了控制和干预生成过程的手段。这种能力在视觉内容创作、建筑设计和药物发现等应用中尤为重要。我们取得的积极成果凸显了该方法在可控和交互式生成方面的潜力,为这一方向的未来探索铺平了道路。

图5:条件逐像素预测结果,包括图像修复(第一行)、外画(第二行)、未裁剪(在大面具上画外画,第三行)和类条件编辑(用另一个类标号,第四行进行修复)。
6. 讨论与结论
本研究通过极具挑战性的逐像素生成任务,验证了所提分形生成模型的有效性,为生成模型设计开辟了新路径。该方法的核心优势在于:将复杂数据分布分解为可管理的子问题,并通过将现有生成模型抽象为模块化单元予以解决。我们认为,分形生成模型尤其适用于建模具有超越一维序列的内在结构特征的数据。该方法的简洁性与有效性有望启发学界进一步探索分形生成模型的新型架构设计与应用场景。
更广泛的影响。本研究的核心目标是推动生成模型的基础研究进展。与所有生成模型类似,若将本方法滥用于制造虚假信息或加剧数据偏见,可能导致负面的社会影响。然而,这些考量已超出本文研究范围,故不做详细探讨。
7. 附录
7.A 实现细节
本节将详细介绍分形生成模型的训练与生成过程的具体实现。
训练过程:
在采用多级自回归模型建模高分辨率图像时,我们发现于自回归序列中加入"引导像素"略有助益。具体而言,模型首先利用上级生成器的输出预测当前输入图像的平均像素值,该平均值随后作为Transformer的附加条件。通过这种方式,每个生成器在预测细节前都能获得全局上下文信息。该"引导像素"技术仅应用于ImageNet 256×256的实验。
由于自回归模型将图像分割为区块,可能导致生成时区块边界不一致。为解决此问题,我们不仅为下级生成器提供当前区块的输出,还包含周边四个区块的输出。虽然这些额外输入会略微增加序列长度,但能显著减少区块边界伪影。
默认训练配置:
优化器:AdamW(Loshchilov & Hutter,2019)
训练周期:800轮(FractalMAR-H模型为600轮)
权重衰减:0.05
动量参数:(0.9, 0.95)
批量大小:ImageNet 64×64为2048,ImageNet 256×256为1024
基础学习率:5e-5(按批量大小/256的比例缩放)
学习率调度:40轮线性预热(Goyal等人,2017)后接余弦衰减
生成过程:
遵循文献惯例(Chang等人,2022,2023;Li等人,2023),我们采用分类器无关引导(CFG)和温度缩放技术实现类条件生成。为实施CFG(Ho & Salimans,2022),训练时10%样本的类别条件被替换为虚拟类别标记。推理时模型同时运行给定类别标记和虚拟标记,得到两组像素通道 logits(
l
c
l_c
lc 和
l
u
l_u
lu),并按公式
l
=
l
u
+
ω
⋅
(
l
c
−
l
u
)
l = l_u + ω·(l_c - l_u)
l=lu+ω⋅(lc−lu) 调整预测 logits,其中 ω 为引导尺度。如Chang等人(2023)所述,我们对第一级自回归模型采用线性CFG调度,并通过参数扫描确定最优的引导尺度和温度组合。
针对CFG在像素值预测概率极小时可能出现的数值不稳定问题,我们在应用CFG前对条件logits执行阈值为 0.0001 的 top-p 采样。
7.B 补充结果
类条件ImageNet 64×64生成:
评估显示类条件对NLL影响可忽略(与PixelCNN结论一致),但显著提升视觉质量和FID。结果表明我们的分形生成模型能达到与传统生成模型相当的竞争力。
AR与MAR变体对比:
如图6 所示,AR变体利用键值缓存加速生成,而MAR变体采用双向注意力机制,更契合图像建模特性并能并行预测多个区块。如表所示,两种变体均表现良好,其中FractalMAR整体优于FractalAR(与Li等人2024年结论一致),故选择MAR变体进行256×256分辨率图像合成。
像素建模顺序研究:
实验比较了RGB/GRB/BGR三种通道顺序及YCbCr色彩空间转换(表6)。
结果显示:
-所有顺序的NLL相近(注:YCbCr与RGB空间的NLL不可直接比较)
-FID在自回归顺序间存在微小差异(可能源于Inception模型对红绿通道更敏感)
-顺序选择不会导致显著性能差异,证明方法具有鲁棒性
附加定性结果:
图7展示ImageNet 256×256的补充条件生成结果,图8提供补充的逐像素条件预测示例。

图7:FractalMAR - H在ImageNet 256 × 256上逐像素生成的附加结果。

图8:额外的有条件的逐像素预测结果,包括图像修复,外画和未裁剪。
6. Github 实现
【GitHub地址】:Github-fractalgen
FractalGen 首次实现了逐像素的高分辨率图像生成。本代码库包含:
- 🪐 简洁的 PyTorch 版分形生成模型实现
- ⚡️ 基于 ImageNet 64x64 和 256x256 训练的预训练逐像素生成模型
- 💥 可独立运行的 Colab 笔记本(用于执行预训练模型任务)
- 🛸 基于 PyTorch DDP 的训练与评估脚本
6.1 准备工作
数据集
下载 ImageNet 数据集并保存于您的 IMAGENET_PATH 路径下。
安装步骤
- 获取代码:
git clone https://github.com/LTH14/fractalgen.git
cd fractalgen
- 创建并激活名为 fractalgen 的 conda 环境:
conda env create -f environment.yaml
conda activate fractalgen
- 下载预训练模型:
python util/download.py
为方便起见,我们的预训练模型也可直接在此下载:
| Model | FID-50K | Inception Score | #params |
|---|---|---|---|
| FractalAR (IN64) | 5.30 | 56.8 | 432M |
| FractalMAR (IN64) | 2.72 | 87.9 | 432M |
| FractalMAR-Base (IN256) | 11.80 | 274.3 | 186M |
| FractalMAR-Large (IN256) | 7.30 | 334.9 | 438M |
| FractalMAR-Huge (IN256) | 6.15 | 348.9 | 848M |
6.2 使用说明
演示
通过 Colab 笔记本运行我们的交互式可视化演示!
训练
以下训练脚本已在 4x8 H100 GPU 集群测试通过。
- 在 ImageNet 64x64 上训练 FractalAR 800个迭代周期的示例脚本:
torchrun --nproc_per_node=8 --nnodes=4 --node_rank=${NODE_RANK} --master_addr=${MASTER_ADDR} --master_port=${MASTER_PORT} \
main_fractalgen.py \
--model fractalar_in64 --img_size 64 --num_conds 1 \
--batch_size 64 --eval_freq 40 --save_last_freq 10 \
--epochs 800 --warmup_epochs 40 \
--blr 5.0e-5 --weight_decay 0.05 --attn_dropout 0.1 --proj_dropout 0.1 --lr_schedule cosine \
--gen_bsz 256 --num_images 8000 --num_iter_list 64,16 --cfg 11.0 --cfg_schedule linear --temperature 1.03 \
--output_dir ${OUTPUT_DIR} --resume ${OUTPUT_DIR} \
--data_path ${IMAGENET_PATH} --grad_checkpointing --online_eval
- 在ImageNet 64x64上训练 FractalMAR 800 个迭代周期的示例脚本:
torchrun --nproc_per_node=8 --nnodes=4 --node_rank=${NODE_RANK} --master_addr=${MASTER_ADDR} --master_port=${MASTER_PORT} \
main_fractalgen.py \
--model fractalmar_in64 --img_size 64 --num_conds 5 \
--batch_size 64 --eval_freq 40 --save_last_freq 10 \
--epochs 800 --warmup_epochs 40 \
--blr 5.0e-5 --weight_decay 0.05 --attn_dropout 0.1 --proj_dropout 0.1 --lr_schedule cosine \
--gen_bsz 256 --num_images 8000 --num_iter_list 64,16 --cfg 6.5 --cfg_schedule linear --temperature 1.02 \
--output_dir ${OUTPUT_DIR} --resume ${OUTPUT_DIR} \
--data_path ${IMAGENET_PATH} --grad_checkpointing --online_eval
- 在 ImageNet 256x256上训练FractalMAR-L 800个迭代周期的示例脚本:
torchrun --nproc_per_node=8 --nnodes=4 --node_rank=${NODE_RANK} --master_addr=${MASTER_ADDR} --master_port=${MASTER_PORT} \
main_fractalgen.py \
--model fractalmar_large_in256 --img_size 256 --num_conds 5 --guiding_pixel \
--batch_size 32 --eval_freq 40 --save_last_freq 10 \
--epochs 800 --warmup_epochs 40 \
--blr 5.0e-5 --weight_decay 0.05 --attn_dropout 0.1 --proj_dropout 0.1 --lr_schedule cosine \
--gen_bsz 256 --num_images 8000 --num_iter_list 64,16,16 --cfg 21.0 --cfg_schedule linear --temperature 1.1 \
--output_dir ${OUTPUT_DIR} --resume ${OUTPUT_DIR} \
--data_path ${IMAGENET_PATH} --grad_checkpointing --online_eval
评估
- 在ImageNet 64x64无条件似然估计上评估预训练的FractalAR(单GPU):
torchrun --nproc_per_node=1 --nnodes=1 --node_rank=0 \
main_fractalgen.py \
--model fractalar_in64 --img_size 64 --num_conds 1 \
--nll_bsz 128 --nll_forward_number 1 \
--output_dir pretrained_models/fractalar_in64 \
--resume pretrained_models/fractalar_in64 \
--data_path ${IMAGENET_PATH} --seed 0 --evaluate_nll
- 在ImageNet 64x64无条件似然估计(单GPU)上评估预训练的FractalMAR:
torchrun --nproc_per_node=1 --nnodes=1 --node_rank=0 \
main_fractalgen.py \
--model fractalmar_in64 --img_size 64 --num_conds 5 \
--nll_bsz 128 --nll_forward_number 10 \
--output_dir pretrained_models/fractalmar_in64 \
--resume pretrained_models/fractalmar_in64 \
--data_path ${IMAGENET_PATH} --seed 0 --evaluate_nll
- 在ImageNet 64x64类条件生成上评估预训练的FractalAR:
torchrun --nproc_per_node=8 --nnodes=1 --node_rank=0 \
main_fractalgen.py \
--model fractalar_in64 --img_size 64 --num_conds 1 \
--gen_bsz 512 --num_images 50000 \
--num_iter_list 64,16 --cfg 11.0 --cfg_schedule linear --temperature 1.03 \
--output_dir pretrained_models/fractalar_in64 \
--resume pretrained_models/fractalar_in64 \
--data_path ${IMAGENET_PATH} --seed 0 --evaluate_gen
- 在ImageNet 64x64类条件生成上评估预训练的FractalMAR:
torchrun --nproc_per_node=8 --nnodes=1 --node_rank=0 \
main_fractalgen.py \
--model fractalmar_in64 --img_size 64 --num_conds 5 \
--gen_bsz 1024 --num_images 50000 \
--num_iter_list 64,16 --cfg 6.5 --cfg_schedule linear --temperature 1.02 \
--output_dir pretrained_models/fractalmar_in64 \
--resume pretrained_models/fractalmar_in64 \
--data_path ${IMAGENET_PATH} --seed 0 --evaluate_gen
- 在ImageNet 256x256类条件生成上评估预训练的FractalMAR Huge:
torchrun --nproc_per_node=8 --nnodes=1 --node_rank=0 \
main_fractalgen.py \
--model fractalmar_huge_in256 --img_size 256 --num_conds 5 --guiding_pixel \
--gen_bsz 1024 --num_images 50000 \
--num_iter_list 64,16,16 --cfg 19.0 --cfg_schedule linear --temperature 1.1 \
--output_dir pretrained_models/fractalmar_huge_in256 \
--resume pretrained_models/fractalmar_huge_in256 \
--data_path ${IMAGENET_PATH} --seed 0 --evaluate_gen
注意:对于ImageNet 256x256,实现最佳FID的最佳无分类器引导值cfg对于FractalMAR Base为29.0,对于FractalMAR Large为21.0。
【本节完】
版权声明:
欢迎关注『youcans论文精读』系列
转发请注明原文链接:
【youcans论文精读】何恺明:分形生成模型(Fractal Generative Models)
Copyright 2025 youcans, XIDIAN
Crated:2025-04


















 723
723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











