









GitHub:https://github.com/LTH14/fractalgen
Abstract
Modularization is a cornerstone of computer science, abstracting complex functions into atomic building blocks. In this paper, we introduce a new level of modularization by abstracting generative models into atomic generative modules. Analogous to fractals in mathematics, our method constructs a new type of generative model by recursively invoking atomic generative modules, resulting in selfsimilar fractal architectures that we call fractal generative models. As a running example, we instantiate our fractal framework using autoregressive models as the atomic generative modules and examine it on the challenging task of pixelby-pixel image generation, demonstrating strong performance in both likelihood estimation and generation quality. We hope this work could open a new paradigm in generative modeling and provide a fertile ground for future research.
Code is available at https://github.com/LTH14/fractalgen.
模块化作为计算机科学的基石理论,通过将复杂系统解耦为原子级功能单元实现抽象封装。本研究提出新型生成模型模块化范式,将生成器抽象为原子生成模块(atomic generative modules)。借鉴分形几何的核心思想,本方法通过递归调用原子生成模块构建新型生成架构,最终形成具有自相似特性的分形架构,我们将其命名为分形生成模型(fractal generative models)。为验证理论有效性,我们选择自回归模型作为原子生成模块实例化分形框架,在逐像素图像生成这一挑战性任务中进行系统性验证。实验结果表明,该模型在似然估计与生成质量两个关键指标上均展现显著优势。本研究有望开启生成模型研究新范式,为后续研究提供富饶的理论土壤。
Introduction
At the core of computer science lies the concept of modularization. For example, deep neural networks are built fromatomic “layers” that serve as modular units (Szegedy et al., 2015). Similarly, modern generative models—such as diffusion models (Song et al., 2020) and autoregressive models (Radford et al., 2018)—are built from atomic “generative steps”, each implemented by a deep neural network. By abstracting complex functions into these atomic building blocks, modularization allows us to create more intricate systems by composing these modules.
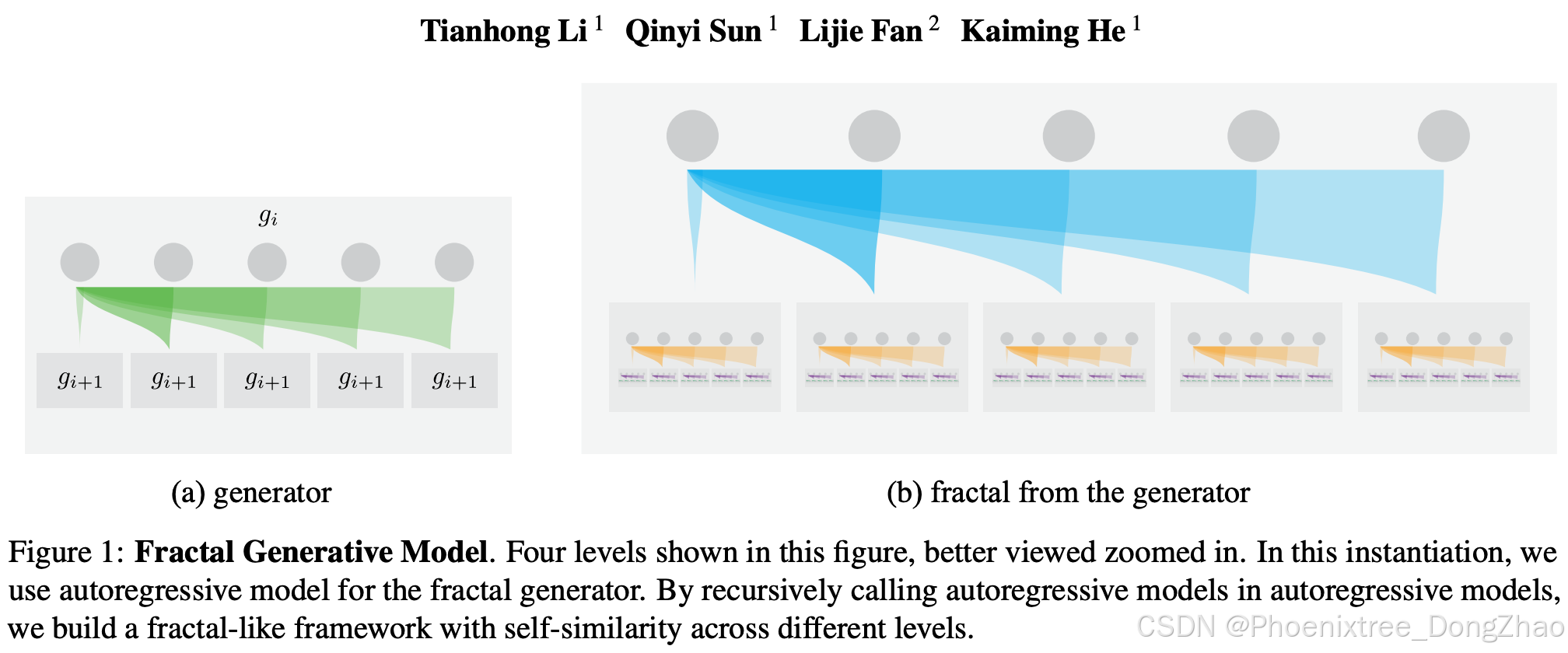
Building on this concept, we propose abstracting a generative model itself as a module to develop more advanced generative models. Specifically, we introduce a generative model constructed by recursively invoking generative models of the same kind within itself. This recursive strategy results in a generative framework that exhibits complex architectures with self-similarity across different levels of modules, as shown in Figure 1.
Our proposal is analogous to the concept of fractals (Mandelbrot, 1983) in mathematics. Fractals are self-similar patterns constructed using a recursive rule called a generator. Similarly, our framework is also built by a recursive process of calling generative models in generative models, exhibiting self-similarity across different levels. Therefore, we name our framework as “fractal generative model”.
Fractals or near-fractals are commonly observed patterns in biological neural networks. Multiple studies have provided evidence for fractal or scale-invariant small-world network organizations in the brain and its functional networks (Bassett et al., 2006; Sporns, 2006; Bullmore & Sporns, 2009). These findings suggest that the brain’s development largely adopts the concept of modularization, recursively building larger neural networks from smaller ones.
Beyond biological neural networks, natural data often exhibit fractal or near-fractal patterns. Common fractal patterns range from macroscopic structures such as clouds, tree branches, and snowflakes, to microscopic ones including crystals (Cannon et al., 2000), chromatin (Mirny, 2011), and proteins (Enright & Leitner, 2005). More generally, natural images can also be analogized to fractals. For example, an image is composed of sub-images that are themselves images (although they may follow different distributions). Accordingly, an image generative model can be composed of modules that are themselves image generative models.
The proposed fractal generative model is inspired by the fractal properties observed in both biological neural networks and natural data. Analogous to natural fractal structures, the key component of our design is the generator which defines the recursive generation rule. For example, such a generator can be an autoregressive model, as illustrated in Figure 1. In this instantiation, each autoregressive model is composed of modules that are themselves autoregressive models. Specifically, each parent autoregressive block spawns multiple child autoregressive blocks, and each child block further spawns more autoregressive blocks. The resulting architecture exhibits fractal-like, self-similar patterns across different levels.
We examine this fractal instantiation on a challenging testbed: pixel-by-pixel image generation. Existing methods that directly model the pixel sequence do not achieve satisfactory results in both likelihood estimation and generation quality (Hawthorne et al., 2022; Yu et al., 2023), as images do not embody a clear sequential order. Despite its difficulty, pixel-by-pixel generation represents a broader class of important generative problems: modeling non-sequential data with intrinsic structures, which is particularly important for many data types beyond images, such as molecular structures, proteins, and biological neural networks.
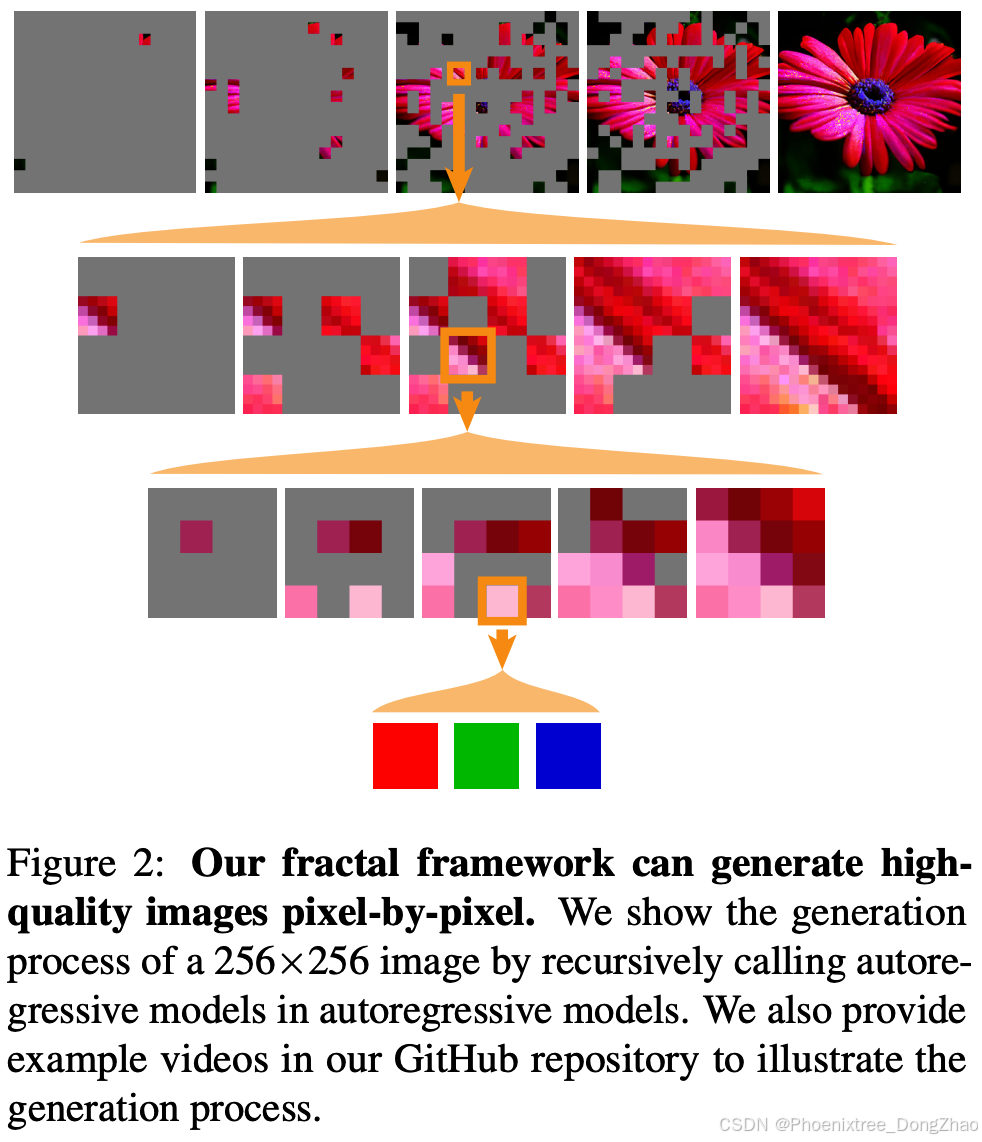
Our proposed fractal framework demonstrates strong performance on this challenging yet important task. It can generate raw images pixel-by-pixel (Figure 2) while achieving accurate likelihood estimation and high generation quality. We hope our promising results will encourage further research on both the design and applications of fractal generative models, ultimately establishing a new paradigm in generative modeling.
模块化是计算机科学体系架构的核心范式。以深度神经网络为例,其本质是由原子化的"层级"模块构建而成(Szegedy等人,2015年)。现代生成模型如扩散模型(Song等人,2020年)与自回归模型(Radford等人,2018年),同样基于原子化的"生成步骤"单元构建,每个步骤均由深度神经网络实现。通过将复杂功能解耦为这些原子级构件,模块化技术赋予我们通过组合模块构建复杂系统的能力。
在此基础上,我们提出将生成模型本身抽象为模块单元,用于构建更先进的生成系统。具体而言,我们构建的新型生成模型通过递归调用同类生成模块实现。这种递归策略形成的生成框架展现出跨模块层级的自相似复杂架构,其拓扑结构如图1所示。
该理论体系与数学中的分形概念(Mandelbrot,1983年)形成深刻共鸣。分形是通过称为生成元的递归规则构建的自相似模式。类似地,我们的框架通过"模型中调用模型"的递归过程实现,在不同层级展现出自相似特性。因此,我们将该框架命名为"分形生成模型"。[本文中的“生成器”特指递归生成分形的规则。]
在生物神经网络中,分形或近分形结构是普遍存在的组织模式。多项研究证实大脑及其功能网络具有分形特征或尺度不变的小世界网络结构(Bassett等人,2006年;Sporns,2006年;Bullmore与Sporns,2009年)。这些发现表明,神经系统的发育过程本质上遵循模块化原理,通过递归组合小型神经网络构建大型网络体系。
除了生物神经网络,自然数据通常包含分形或接近分形的模式。常见的分形pat燕鸥的范围从宏观结构,如云,树枝和雪花,到微观结构,包括晶体(Cannon等人,2000),染色质(Mirny, 2011)和蛋白质(Enright & Leitner, 2005)。更一般地说,自然图像也可以类比为分形。例如,图像由子图像组成,这些子图像本身也是图像(尽管它们可能遵循不同的分布)。因此,图像生成模型可以由本身就是图像生成模型的模块组成。
所提出的分形生成模型的灵感来自于在生物神经网络和自然数据中观察到的裂缝特性。类似于自然的分形结构,我们设计的关键部分是定义递归生成规则的生成器。例如,这样的生成器可以是一个自回归模型,如图1所示。在这个实例化中,每个自回归模型都由自身为自回归模型的模块组成。具体来说,每个父自回归块会衍生多个子自回归块,每个子块会进一步衍生更多的自回归块。结果ing架构在不同的层次上表现出分形的、自相似的模式。
在一个具有挑战性的测试平台上研究了这种分形实例化:逐像素图像生成。直接对像素序列进行建模的现有方法没有达到令人满意的效果factory在似然估计和生成质量方面都取得了效果(Hawthorne等人,2022;Yu et al., 2023),因为图像不体现明确的顺序。尽管困难重重,逐像素生成代表了更广泛的一类重要的生成问题:用内在结构对非顺序数据进行建模,这对于图像以外的许多数据类型特别重要,如分子结构、蛋白质和生物神经网络。
所提出的分形框架在这一具有挑战性但重要的任务上表现出强大的性能。它可以逐像素生成原始图像(图2),同时实现精确率似然估计和高生成质量。我们希望我们有希望的结果将鼓励对分形生成模型的设计和应用的进一步研究,最终在通用建模中建立一种新的范式。
Fractal Generative Models
The key idea behind fractal generative models is to recursively construct more advanced generative models from existing atomic generative modules. In this section, we first present the high-level motivation and intuition behind fractal generative models. We then use the autoregressive model as an illustrative atomic module to demonstrate how fractal generative models can be instantiated and used to model very high-dimensional data distributions.
1. Motivation and Intuition
Fractals are complex patterns that emerge from simple, recursive rules. In fractal geometry, these rules are often called “generators” (Mandelbrot, 1983). With different generators, fractal methods can construct many natural patterns, such as clouds, mountains, snowflakes, and tree branches, and have been linked to even more intricate systems, such as the structure of biological neural networks (Bassett et al., 2006; Sporns, 2006; Bullmore & Sporns, 2009), nonlinear dynamics (Aguirre et al., 2009), and chaotic systems (Mandelbrot et al., 2004).
Formally, a fractal generator gi specifies how to produce a set of new data {x_i+1} for the next-level generator based on one output x_i from the previous-level generator: {x_i+1} = g_i(x_i). For example, as shown in Figure 1, a generator can construct a fractal by recursively calling similar generators within each grey box.
Because each generator level can produce multiple outputs from a single input, a fractal framework can achieve an exponential increase in generated outputs while only requiring a linear number of recursive levels. This property makes it particularly suitable for modeling high-dimensional data with relatively few generator levels.
Specifically, we introduce a fractal generative model that uses atomic generative modules as parametric fractal generators. In this way, a neural network “learns” the recursive rule directly from data. By combining the exponential growth of fractal outputs with neural generative modules, our fractal framework enables the modeling of high-dimensional non-sequential data. Next, we demonstrate how we instantiate this idea with an autoregressive model as the fractal generator.
分形是通过简单递归规则涌现的复杂形态模式。在分形几何学中,这种递归规则被定义为"生成元"(曼德博,1983年)。采用不同生成元,分形方法可构造云层、山脉、雪花、枝桠等自然形态,更可模拟生物神经网络拓扑(Bassett等,2006年;Sporns,2006年;Bullmore与Sporns,2009年)、非线性动力学系统(Aguirre等,2009年)及混沌系统(曼德博等,2004年)等复杂结构。
在形式化定义层面,分形生成元gi根据上级生成元的输出xi产生下一层数据集合{x_i+1}:{x_i+1} = g_i(x_i)。如图1所示,生成元通过在每个灰色模块内递归调用同类生成元构建分形结构。
由于单次递归调用可实现输入到多输出的映射,分形框架仅需线性递归深度即可实现生成结果的指数级增长。这种特性使其特别适用于高维数据建模,在保持较低计算复杂度的前提下实现维度扩展。
具体而言,我们构建的分形生成模型将原子生成模块作为参数化生成元。通过这种设计,神经网络直接从数据中"习得"递归规则。结合分形结构的指数增长特性与神经生成模块的建模能力,该框架可有效表征高维非序列数据。下文将以自回归模型为生成元实例,详细阐述该理论的具体实现。
2. Autoregressive Model as Fractal Generator
In this section, we illustrate how to use autoregressive models as the fractal generator to build a fractal generative model. Our goal is to model the joint distribution of a large set of random variables x_1, · · · , x_N , but directly modeling it with a single autoregressive model is computationally prohibitive. To address this, we adopt a divide-and-conquer strategy. The key modularization is to abstract an autoregressive model as a modular unit that models a probability distribution p(x|c). With this modularization, we can construct a more powerful autoregressive model by building it on top of multiple next-level autoregressive models.
Assume that the sequence length in each autoregressive model is a manageable constant k, and let the total number of random variables N = k n, where n = logk (N) represents the number of recursive levels in our fractal framework. The first autoregressive level of the fractal framework then partitions the joint distribution into k subsets, each containing k^{n−1} variables. Formally, we decompose:
.
Each conditional distribution p(· · · | · · ·) with
variables is then modeled by the autoregressive model at the second recursive level, so on and so forth. By recursively calling such a divide-and-conquer process, our fractal framework can efficiently handle the joint distribution of
variables using n levels of autoregressive models, each operating on a manageable sequence length k.
This recursive process represents a standard divide-andconquer strategy. By recursively decomposing the joint distribution, our fractal autoregressive architecture not only significantly reduces computational costs compared to a single large autoregressive model but also captures the intrinsic hierarchical structure within the data.
Conceptually, as long as the data exhibits a structure that can be organized in a divide-and-conquer manner, it can be naturally modeled within our fractal framework. To provide a more concrete example, in the next section, we implement this approach to tackle the challenging task of pixel-by-pixel image generation.
本节阐述如何以自回归模型为生成元构建分形生成模型。研究目标为建模大规模随机变量集x₁,…,x_N的联合概率分布,但直接采用单一自回归模型进行全维度建模存在计算不可行性。为此,我们采用分治策略实现模块化建模:将自回归模型抽象为条件概率分布p(x|c)的模块单元。通过该模块化设计,可在多级自回归模型堆叠基础上构建更强大的概率建模框架。
设定单层自回归模型的序列长度为可控常数k,总变量数满足N=kⁿ,其中n=log_k(N)表征分形框架的递归深度。分形框架的首层自回归模型将联合分布分解为k个子集,每个子集包含kⁿ⁻¹个变量。形式化分解如下:
p(x₁,…,x_N) = ∏_{i=1}^k p(x_{(i-1)*kⁿ⁻¹+1},…,x_{i*kⁿ⁻¹}|x₁,…,x_{(i-1)kⁿ⁻¹})
每个条件概率分布p(·|·)由第二递归层的自回归模型建模,以此类推。通过递归调用该分治过程,分形框架仅需n层自回归模型即可高效建模N维联合分布,各层仅需处理k维可控序列。
该递归过程本质上是标准分治策略的数学实现。通过递归分解联合分布,分形自回归架构相较单一大型模型不仅显著降低计算复杂度,更能捕捉数据内在的层级结构特征。
从理论层面而言,只要数据具备可分治组织的结构特征,即可天然适配本框架建模。为提供具体实证,下节我们将通过逐像素图像生成这一挑战性任务进行方法验证。
An Image Generation Instantiation
We now present one concrete implementation of fractal generative models with an instantiation on the challenging task of pixel-by-pixel image generation. Although we use image generation as a testbed in this paper, the same divideand-conquer architecture could be potentially adapted to other data domains. Next, we first discuss the challenges and importance of pixel-by-pixel image generation.
本文提出分形生成模型在逐像素图像生成这一挑战性任务中的具体实现方案。尽管以图像生成为验证载体,该分治架构可拓展至其他数据领域。本节首先剖析逐像素图像生成的技术挑战与研究价值。
1. Pixel-by-pixel Image Generation
Pixel-by-pixel image generation remains a significant challenge in generative modeling because of the high dimensionality and complexity of raw image data. This task requires models that can efficiently handle a large number of pixels while effectively learning the rich structural patterns and interdependency between them. As a result, pixel-by-pixel image generation has become a challenging benchmark where most existing methods are still limited to likelihood estimation and fail to generate satisfactory images (Child et al., 2019; Hawthorne et al., 2022; Yu et al., 2023).
Though challenging, pixel-by-pixel generation represents a broader class of important high-dimensional generative problems. These problems aim to generate data element-byelement but differ from long-sequence modeling in that they typically involve non-sequential data. For example, many structures—such as molecular configurations, proteins, and biological neural networks—do not exhibit a sequential architecture yet embody very high-dimensional and structural data distributions. By selecting pixel-by-pixel image generation as an instantiation for our fractal framework, we aim not only to tackle a pivotal challenge in computer vision but also to demonstrate the potential of our fractal approach in addressing the broader problem of modeling high-dimensional non-sequential data with intrinsic structures.
由于原始图像数据的高维度与复杂性,逐像素生成始终是生成建模领域的重大挑战。该任务要求模型在高效处理海量像素的同时,精准捕捉像素间的结构关联与依赖关系。现有方法多局限于似然估计,难以生成高质量图像(Child等,2019年;Hawthorne等,2022年;Yu等,2023年),使其成为验证生成模型能力的试金石。
尽管极具挑战性,逐像素生成代表着一类重要的高维生成问题范式。这类问题要求逐元素生成数据,但与长序列建模不同,其目标通常是非序列数据结构。例如分子构型、蛋白质结构、生物神经网络等虽无显式序列特征,却蕴含高维结构化数据分布。通过将逐像素生成作为分形框架的验证实例,我们不仅旨在攻克计算机视觉核心难题,更力图证明该框架在具有内在结构的高维非序列数据建模中的普适价值。
2. Architecture
As shown in Figure 3, each autoregressive model takes the output from the previous-level generator as its input and produces multiple outputs for the next-level generator. It also takes an image (which can be a patch of the original image), splits it into patches, and embeds them to form the input sequence for a transformer model. These patches are also fed to the corresponding next-level generators. The transformer then takes the output of the previous generator as a separate token, placed before the image tokens. Based on this combined sequence, the transformer produces multiple outputs for the next-level generator.
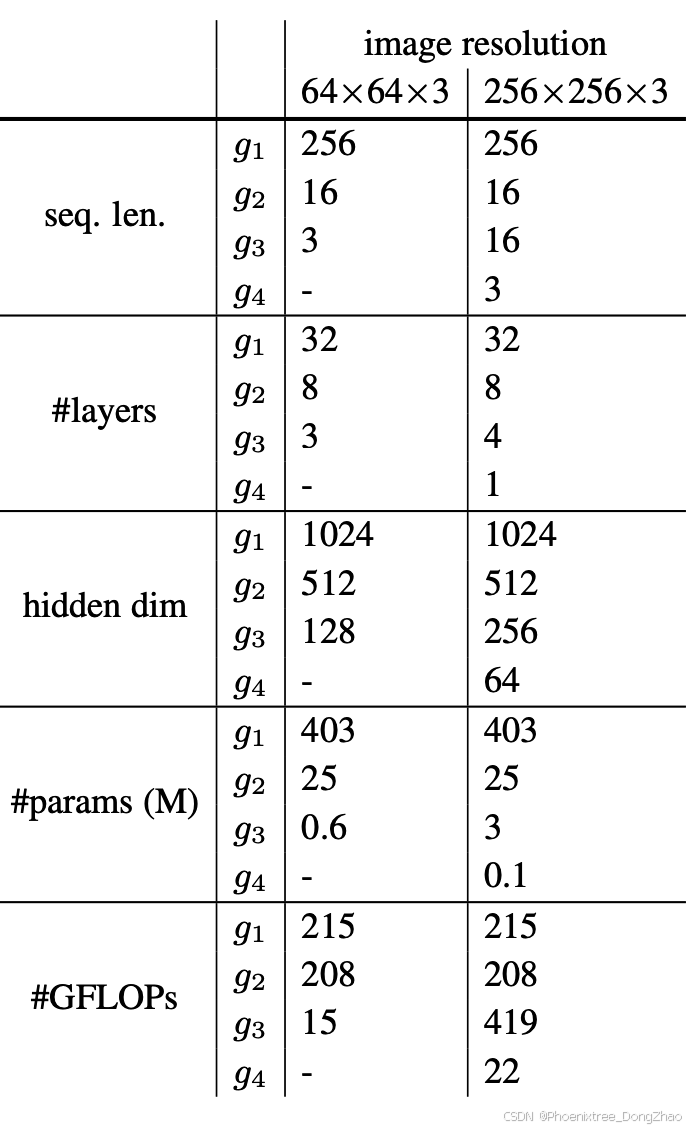
Following common practices from vision transformers and image generative models (Dosovitskiy et al., 2020; Peebles & Xie, 2023), we set the sequence length of the first generator g0 to 256, dividing the original images into 16 × 16 patches. The second-level generator then models each patch and further subdivides them into smaller patches, continuing this process recursively. To manage computational costs, we progressively reduce the width and the number of transformer blocks for smaller patches, as modeling smaller patches is generally easier than larger ones. At the final level, we use a very lightweight transformer to model the RGB channels of each pixel autoregressively, and apply a 256-way cross-entropy loss on the prediction. The exact configurations and computational costs for each transformer across different recursive levels and resolutions are detailed in Table 1. Notably, with our fractal design, the computational cost of modeling a 256×256 image is only twice that of modeling a 64×64 image.
Following (Li et al., 2024), our method supports different autoregressive designs. In this work, we mainly consider two variants: a raster-order, GPT-like causal transformer (AR) and a random-order, BERT-like bidirectional transformer (MAR) (Figure 6). Both designs follow the autoregressive principle of next-token prediction, each with its own advantages and disadvantages, which we discuss in detail in Appendix B. We name the fractal framework using the AR variant as FractalAR and the MAR variant as FractalMAR.
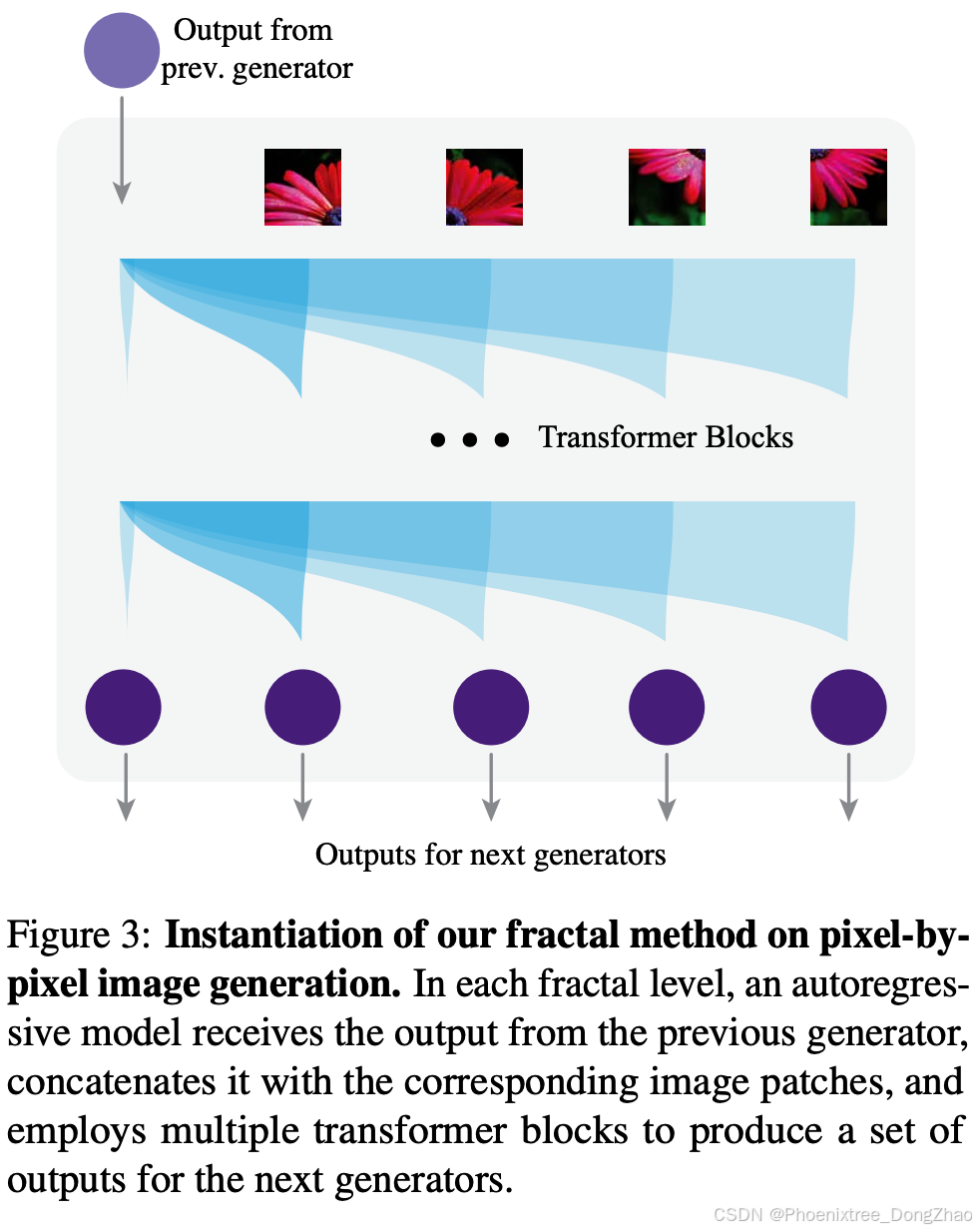

如图3所示,每级自回归模型将上级生成元输出作为输入,并为下级生成元产生多组输出。该模型接收完整图像(或原始图像块)作为输入,将其分割为若干子块并进行嵌入编码,形成Transformer模型的输入序列。这些图像块同时被馈送至对应的下级生成元。Transformer将上级生成元输出作为独立标记(token)置于图像标记序列前端,基于该组合序列生成下级生成元所需的多元输出。
参照视觉Transformer的通用设计范式(Dosovitskiy等人,2020年)与图像生成模型实践(Peebles与Xie,2023年),我们设定首层生成元g₀的序列长度为256,将原始图像分割为16×16图像块。第二级生成元对每个图像块建模后继续细分,该过程递归执行。为优化计算成本,随着图像块尺寸递减,我们逐步缩减Transformer模块的宽度与深度——较小图像块的建模复杂度通常低于大尺寸图像块。最终层级采用轻量化Transformer对像素RGB通道进行自回归建模,并在预测端施加256维交叉熵损失。各递归层级及分辨率对应的Transformer配置细节与计算成本详见表1。值得注意的是,基于本分形架构设计,256×256图像建模的计算成本仅为64×64图像的两倍。
延续(Li等人,2024年)的研究范式,本方法支持差异化自回归架构设计。本文重点研究两种变体:类GPT的栅格顺序因果Transformer(AR)与类BERT的随机顺序双向Transformer(MAR)(见图6)。二者均遵循"下一标记预测"的自回归原则,但各具优劣特性,具体分析详见附录B。我们将采用AR架构的分形框架命名为FractalAR,MAR架构命名为FractalMAR。

















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









