






GAN是让机器自动生成
PG
去接近
Pdata
。算法的关键是衡量分布
PG,Pdata
的差异,不同的衡量办法得到的
V(G,D)
不同,但是所有的衡量方法都可以归纳到一个统一的框架中:利用f-divergence衡量两个分布差异,利用Fenchel Conjugate将两个分布差异的问题转化到GAN的大框架中。
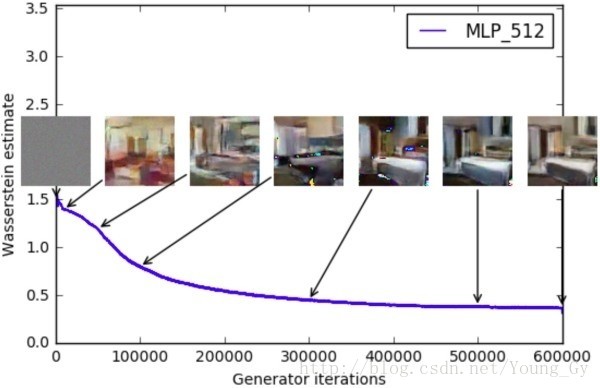
而近段异常流行的WGAN,便是将两个分布的差异用Earch Mover Distance衡量,然后用weight clipping或gradient penalty优化梯度计算,取得了非常好的效果。
原始GAN
原始GAN的演算法如下,通过discriminator的loss与js divergence相关联。

统一架构
f divergence
衡量两个分布的差距有多种方法,这些方法基本上都属于同一个架构f divergence。如下, Df(P||Q) 通过包含 f 函数的积分评估了两个分布的差异:
f
函数满足的条件如下(满足这样的条件,
- f 是凸hanshu
f(1)=0
不同的f函数会得到不同的divergence,但是都属于f divergence这个大框架中,区别只是f函数的不同。

fenchel conjugate
每一个凸函数
f
,都有与其conjugate的函数
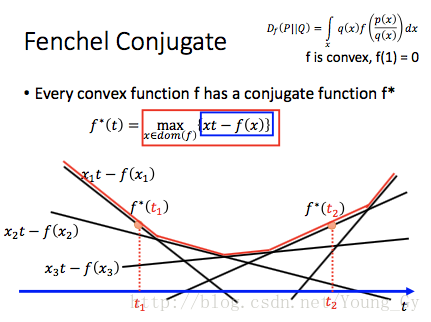
举例如下:

connect with gan
那么一个问题随之而来:f divergence以及fenchel conjugate与GAN到底有什么联系呢?
首先,f divergence提供了一种度量两个分布差异的方式;然而,f divergence需要知道pdf,生成分布的pdf不容易得到;这时候通过f的fenchel conjugate对原来的差异公式进行变换,引入额外的变量D(也就是discriminator),转化成找到令值最大的D的问题,最终化成GAN类似的形式。具体化简过程如下:


总的来说,f divergence以及fenchel conjugate的价值在于:构建了两个分布的f divergence,通过fenchel conjugate将divergence转化为 maxDV(G,D) 的问题,自然而然地与GAN关联了起来。
其他
GAN的训练在原始paper中是两次循环,f-divergence的paper中是一次循环。

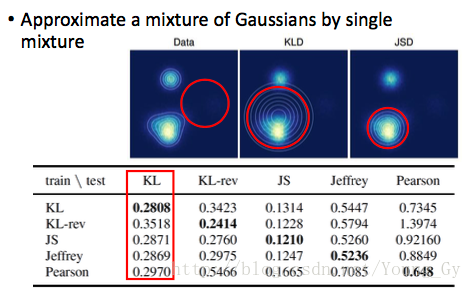
不同的f函数得到的分布差异也不一样,如下:

KLD与JSD相比,对多分布的拟合效果较好:
WGAN
介绍
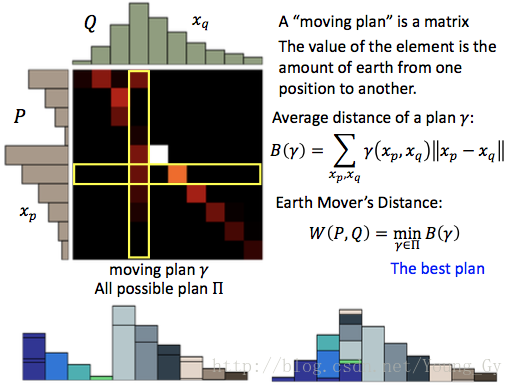
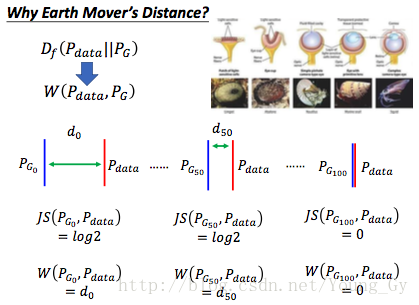
前面介绍了用f-divergence去度量两个分布的差异,WGAN与传统GAN的区别就是度量分布差异的方式不同。WGAN使用了earth mover's distance,顾名思义,就是把一个分布变成另外一个分布需要花的力气。earth mover's distance的定义如下:
优势
WGAN的优势,主要在于earth mover's distance。earth mover's distance相比js divergence的优点是:当两个分布没有接触的时候,不管距离远近,js divergence的度量都是相同的,而earth mover's distance会考虑到两个分布的距离到底有多远,这样在训练的时候便更容易训练。
如果不使用WGAN,通常的做法是给分布加噪声,让分布有重叠,这样才更容易去训练。
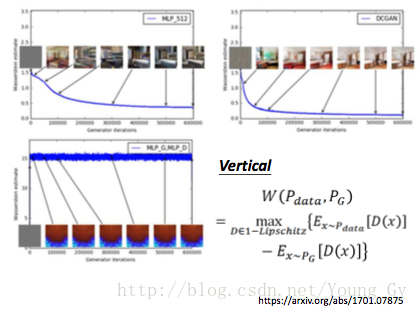
因此,WGAN可以部分解决生成模型的评价问题,可以利用earth mover's distance来监控模型的好坏(更多处于实际操作方面而非理论loss)。
weight clipping
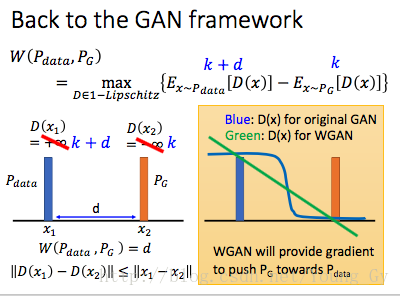
使用earth mover's distance后,WGAN度量分布差异的公式如下:

Lipschitz Function限制条件的作用是:一方面给D(x)加一些控制,不让它任意变大变小,否则都变成无穷值就没有意义了;另一方面限制D(x)的增长速度,提供足够的梯度保证,如下图:
那么问题来了,如何保证D(x)满足Lipschitz Function限制条件呢?
原始的WGAN采用了weight clipping方法,其思路是限制参数的梯度值在一定范围内,这样便通过倒数限制了D(x)的增长速度。这种方法的缺点是c值不好确定。

完整的算法如下:

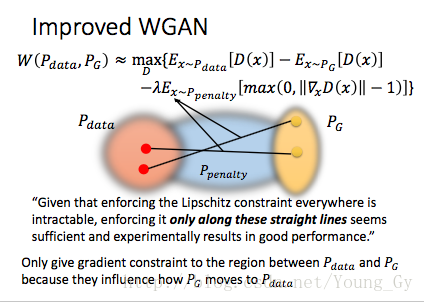
gradient penalty
之前Lipschitz Function限制条件通过weight clipping解决,这里借助Lipschitz Function的梯度小于等于1的条件,增加过大梯度的惩罚项,具体如下:
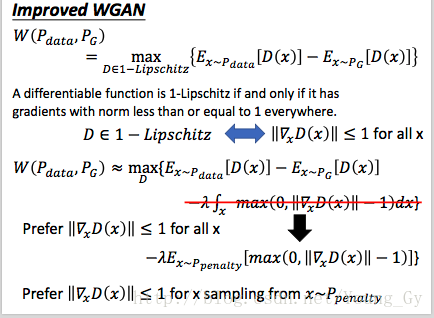
















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









