







Flappy Bird
在浏览机器学习相关内容的时候,看到有人通过机器学习玩转一个曾经很火的手机游戏Flappy bird。 其使用的算法是Q_learning。
算法如下:
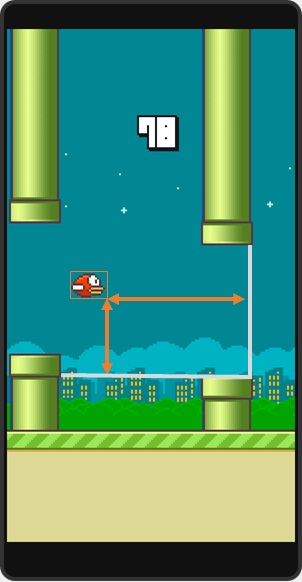
状态矢量空间
在这里一共设计了3个参数:1,小鸟与低管道的垂直距离;2,小鸟与下一个管道出口的水平距离;3,小鸟是否死亡。
行为
对每个状态,我设计了两个可能存在的行为:点击或者是什么都不做。
奖励
奖励完全依赖于“Life”参数,仍然存活则+1,失败则-1000。
学习循环
数组Q初始化为0,同时也总采取最佳操作,这些操作将最大化我的预期奖励。
第一步,观察Flappy Bird所处的状态,并执行可以最大化预期奖励的操作。让游戏引擎执行“tick”操作,随之Flappy Bird进入下一个状态s’。
第二步,观察s’及状态下的奖励,+1则表示小鸟还活着。
第三步,通过Q Learning规则来修改Q数组。Alpha的值被设置成0.7,因为我们需要一个确定的状态,也让学习的可能最大化;同时,Y和lambda都被设置成了1。
第四步,将当前状态设置为s’并重新开始。
原文链接:Flappy Bird hack using Reinforcement Learning
译文链接:亚特兰大极客使用机器学习玩转Flappy Bird
对其所利用的Q_learning进行资料搜索,找到一个简明的教程对Q_Learning进行了介绍。
一个简明教程
具体的教程见链接A Painless Q-learning Tutorial
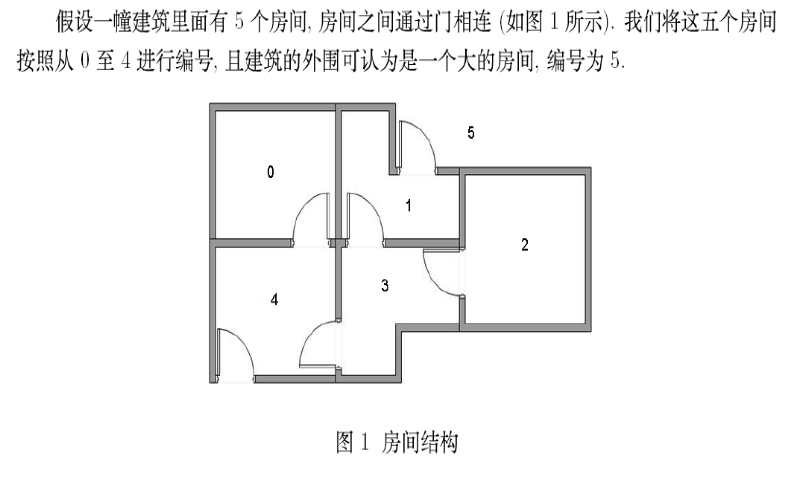
其解决的问题:利用无监督训练让代理找到走出房间的路线。
C++代码
#include <iostream>
#include<cstring>
#include<cmath>
#include <cstdlib>
using namespace std;
#define ROW 6
#define COLUMN 6
#define STATE_NUM 6
#define ACTION_NUM 6
#define alph 0.8
float a[100][100];
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 409
409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









