









文章目录
GraphRAG 踩坑记录
- GraphRAG 0.1.1
- neo4j-community-3.5.22
- JDK-8
一些参考资源
GraphRAG论文:[2404.16130] From Local to Global: A Graph RAG Approach to Query-Focused Summarization
graphrag中文网:GraphRAG:中文文档教程,助力大模型LLM应用开发从入门到精通
大佬的Github:tomasonjo/blogs: Jupyter notebooks that support my graph data science
大佬的博客:https://bratanic-tomaz.medium.com
一个优化GraphRAG处理中文内容的项目:graphrag-practice-chinese
一个结合GraphRAG和Dify的项目:brightwang/graphrag-dify
1. GraphRAG 构建
一定要安装0.1.1版本,网上的资源包括文档都是这个版本的,我一开始安装的0.5.0版本,和早期版本相比有很大的区别
conda create -n "graphrag" python=3.12
conda activate graphrag
pip install graphrag==0.1.1
然后新建一个graphrag-demo的文件夹作为根目录,在根目录下新建一个叫novel的文件夹作为我们的demo项目目录。在novel路径下再新建一个input目录,存放我们的文档。在这个demo项目中,我们取小说《斗破苍穹》的前20个章节作为知识库中的文档,命名为novel.txt(后缀必须是txt)。此时项目目录结构如下:
graphrag (root)
|____novel
|____input
|____novel.txt
执行以下命令对novel项目初始化:
python -m graphrag.index --init --root ./novel
此时novel路径下多出了.env和settings.yaml两个文件。在.env中把GRAPHRAG_API_KEY修改为自己的OPENAI_API_KEY(不加双引号),在settings.yaml修改模型为“gpt-4o"(gpt-4太贵,而gpt-3.5效果又太差)。然后执行以下命令建立索引:
python -m graphrag.index --root ./novel
取《斗破苍穹》前20章节,这一步花费了数分钟,约$1.3
等待索引建立完成后,可以用以下命令测试一下:
python -m graphrag.query --root ./novel --method global "这个故事的主题是什么?"
2. GraphRAG中文优化
参考graphrag-practice-chinese,所需代码文件均可从该仓库下载
1. 修改settings.yaml中的相关配置信息,换用中文大模型,以更好地支持中文(节约费用)
# `settings.yaml` 包含了 GraphRAG pipeline 的设置。我们需要在其中对两个模型的设置进行更改,这里更改了的 LLM 和 Embedding 部分,使用的是:
# 智谱 AI 的 `glm-4-flash` 和 `embedding-3`。
# - 大语言模型:`glm-4-flash`
# - 嵌入模型:`embedding-3`
...
encoding_model: cl100k_base
skip_workflows: []
llm:
api_key: ********************** # your API key
type: openai_chat # or azure_openai_chat
model: glm-4-flash
model_supports_json: false # recommended if this is available for your model.
max_tokens: 4000
request_timeout: 180.0
api_base: https://open.bigmodel.cn/api/paas/v4
...
embeddings:
## parallelization: override the global parallelization settings for embeddings
async_mode: threaded # or asyncio
# target: required # or all
llm:
api_key: ********************** # your API key
type: openai_embedding # or azure_openai_embedding
model: embedding-3
api_base: https://open.bigmodel.cn/api/paas/v4
2. 替换文档拆分策略
官方分块把文档按照 token 数进行切分,对于中文来说容易在 chunk 之间出现乱码,这里参考 Langchain-ChatChat 开源项目,用中文字符数对文本进行切分。
首先安装requirements.txt当中的依赖:
conda activate GraphRAG-pip
pip install -r requirements.txt
然后复制文件 splitter/tokens.py 替换掉 python 依赖库中的 graphrag/index/verbs/text/chunk/strategies/tokens.py 即可
3. 使用中文提示词(chinese-prompt)
初始化后,在 prompts 目录中可以看到 GraphRAG 的四个 prompt 文件的内容都由英文书写,并要求 LLM 使用英文输出。
为了更好地处理中文内容,这里我使用 gpt-4o 模型,将 prompts/ 中的四个 prompt 文件都翻译成中文,并要求 LLM 用中文输出结果。
如果你有更好的想法,想要自定义提示词,同样可以通过修改这四个 prompt 文件来实现,但注意不要修改提示词的文件名,以及不要修改和遗漏了在原提示词中有关输出的关键字段和格式,以免 GraphRAG 无法正常获取它们。
3. Neo4j可视化
这一部分参考大佬在Github上的Notebook:blogs/msft_graphrag/ms_graphrag_retriever.ipynb at master · tomasonjo/blogs 大佬的代码也是基于早期版本的GraphRAG写的,所以如果我们装的是比较新的GraphRAG就会遇到很多问题(我就是在这里把版本从0.5.0改回0.1.1的)
不过大佬用的Neo4j应该是4.x的,而我服务器上跑的是neo4j-community-3.5.22,因此对大佬代码中涉及的一些Cypher语句做了修改,最终将GraphRAG结果导入了Neo4j数据库进行可视化。
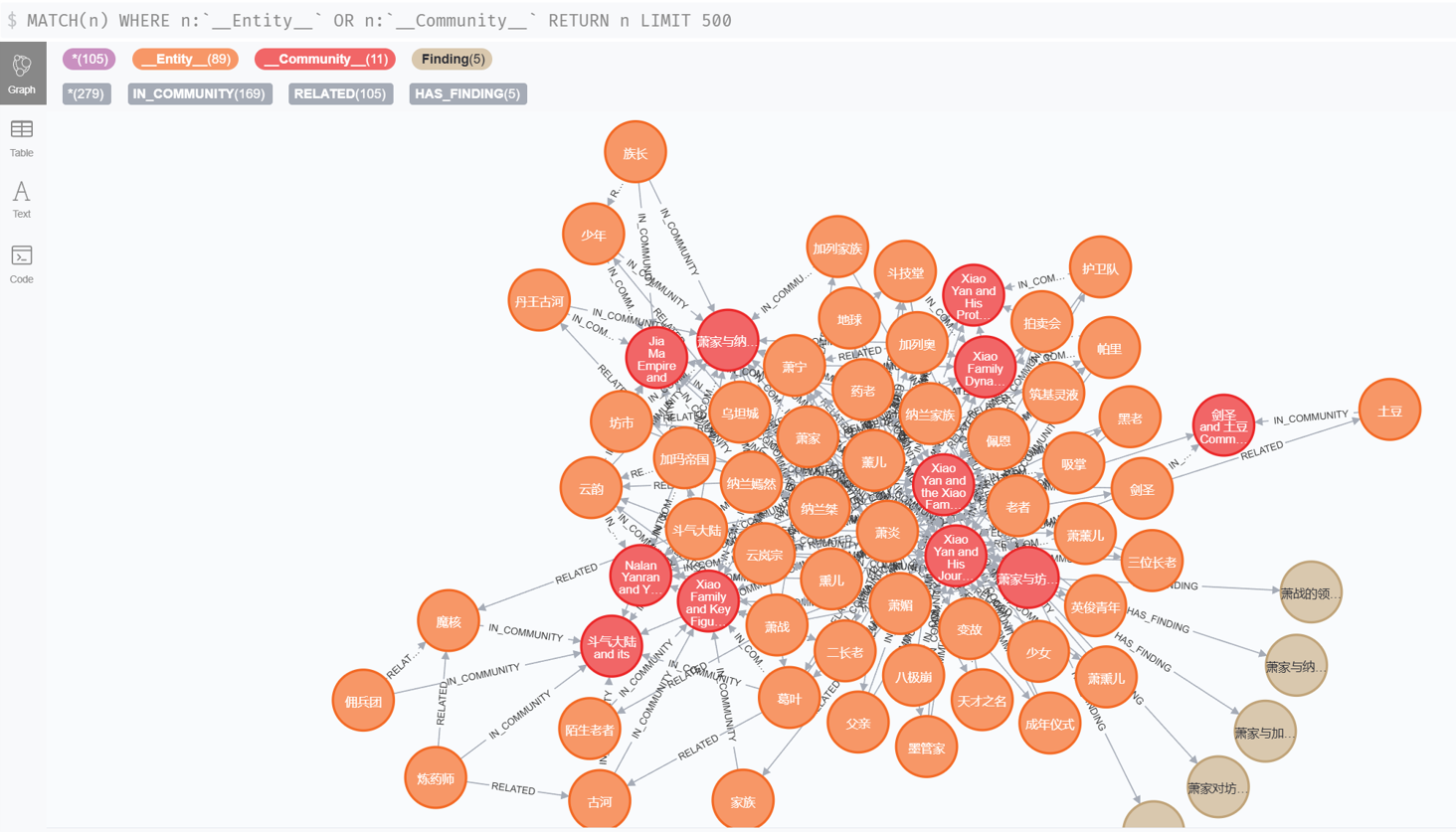
TODO
提示优化

















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









