







爬虫的基本原理
所谓爬虫就是一个自动化数据采集工具,你只要告诉它要采集哪些数据。其背后的基本原理就是爬虫程序向目标服务器发起 HTTP 请求,然后目标服务器返回响应结果,爬虫客户端收到响应并从中提取数据,再进行数据清洗、数据存储工作。
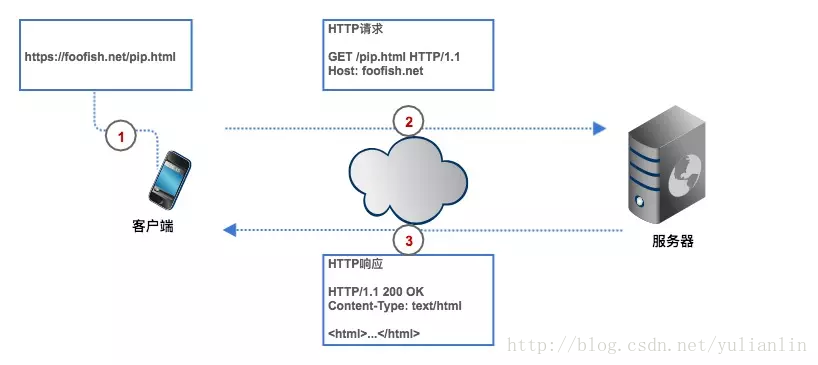
Http请求格式和响应格式

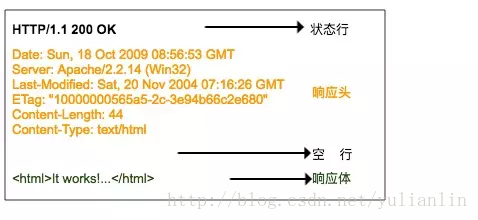
用Pyton内建模块 urllib 请求一个 URL 代码示例如下:
import ssl
from urllib.request import Request
from urllib.request import urlopen
# 创建一个未验证的上下文
context = ssl._create_unverified_context()
# HTTP 请求
request = Request(url="https://foofish.net/pip.html",
method="GET",
headers={"Host": "foofish.net"},
data=None)
# HTTP 响应
response = urlopen(request, context=context)
headers = response.info() # 响应头
content = response.read() # 响应体
code = response.getcode() # 状态码使用Requests爬虫
内建模块过于低级, 使用 Requests 更加便捷
pip install requestsimport requests
# 服务器反爬虫机制会判断客户端请求头中的User-Agent是否来源于真实浏览器,所以,我们使用Requests经常会指定UA伪装成浏览器发起请求
headers = {'user-agent': 'Mozilla/5.0'}
r1 = requests.get("https://httpbin.org/ip", headers=headers) # Get请求
print(r1) # 响应对象
print(r1.content) # 响应内容
print(r1.status_code) # 响应码
# POST请求
r2 = requests.post('http://httpbin.org/post', data={'key': 'value'})requests 支持将参数抽离出来作为方法的参数(params)传递过去
>>> url = "http://httpbin.org/get"
>>> r = requests.get(url, params={"key":"val"})
>>> r.url
u'http://httpbin.org/get?key=val'指定Cookie
Cookie 是web浏览器登录网站的凭证,虽然 Cookie 也是请求头的一部分,我们可以从中剥离出来,使用 Cookie 参数指定
>>> s = requests.get('http://httpbin.org/cookies', cookies={'from-my': 'browser'})
>>> s.text
u'{\n "cookies": {\n "from-my": "browser"\n }\n}\n'设置超时时间
r = requests.get('https://google.com', timeout=5)设置代理
一段时间内发送的请求太多容易被服务器判定为爬虫,所以很多时候我们使用代理IP来伪装客户端的真实IP。
import requests
proxies = {
'http': 'http://127.0.0.1:1080',
'https': 'http://127.0.0.1:1080',
}
r = requests.get('http://www.kuaidaili.com/free/', proxies=proxies, timeout=2)使用 Session
如果想和服务器一直保持登录(会话)状态,而不必每次都指定 cookies,那么可以使用 session,Session 提供的API和 requests 是一样的。
import requests
s = requests.Session()
s.cookies = requests.utils.cookiejar_from_dict({"a": "c"})
r = s.get('http://httpbin.org/cookies')
print(r.text)
# '{"cookies": {"a": "c"}}'
r = s.get('http://httpbin.org/cookies')
print(r.text)
# '{"cookies": {"a": "c"}}'爬取知乎专栏关注的列表
现在我们使用Requests完成一个爬取知乎专栏用户关注列表的简单爬虫为例,找到任意一个专栏,打开它的关注列表,通过Chrome开发者工具可以找到关注列表的网页地址
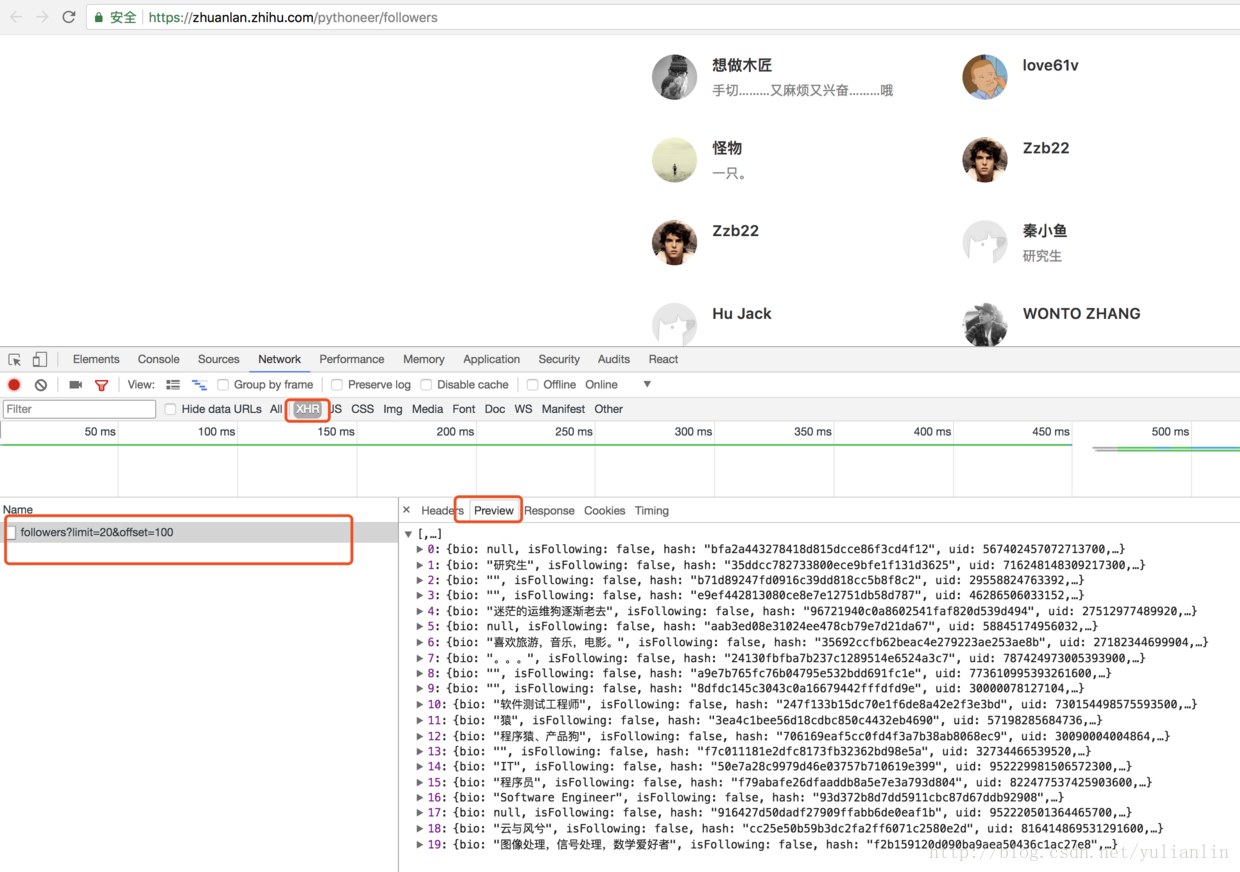
import json
import requests
class SimpleCrawler:
init_url = "https://zhuanlan.zhihu.com/api/columns/SVlaw/followers"
offset = 0
def crawl(self, params=None):
# 必须指定UA,否则知乎服务器会判定请求不合法
headers = {
"Host": "zhuanlan.zhihu.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36",
}
response = requests.get(self.init_url, headers=headers, params=params)
print(response.url)
data = response.json()
# 分页加载更多,递归调用 这里为了演示只获取前100条数据
while self.offset < 100:
self.parse(data)
self.offset += 20
params = {"limit": 20, "offset": self.offset}
self.crawl(params)
def parse(self, data):
# 以json格式存储到文件
with open("followers.json", "a", encoding="utf-8") as f:
for item in data:
f.write(json.dumps(item))
f.write('\n')
if __name__ == '__main__':
SimpleCrawler().crawl()
参考
本文主要参考: 使用 Requests 实现一个简单网页爬虫















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









