







提示:本次部署gemma3是在Linux上,通过部署Docker拉取ollama、Dify,使用Dify集成gemma3:12b模型
文章目录
一、介绍gemma 3
1.1 gemma3 是什么
Gemma 3是谷歌最新推出的开源人工智能模型,专为开发者设计,支持多种设备上的人工智能应用开发。支持超过 35 种语言,具备分析文本、图像及短视频的能力,提供四种不同尺寸的模型(18、4B、128 和27B),满足不同硬件和性能需求。Gemma3在单 GPU 或 TPU 上的性能优于其他同类模型,如 Llama、DeepSeek 和 OpenAl 的 o3-mini。配备了 ShieldGemma2图像安全分类器,可检测和标记危险内容。开发者可以通过 Google Al Studio 快速体验,或从 Hugging Face、Kaggle 等平台下载模型进行微调和部署。
1.2 gemma 3 的主要功能
多模态处理能力:Gemma3支持文本、图像及短视频的混合输入,能够处理复杂的多模态任务,如图像问答、视频内容分析等。
高分辨率图像支持:引入动态图像切片技术和帧采样与光流分析结合方案,支持高分辨率和非方形图像,能在 20秒内完成1小时视频的关键帧提取。
多语言支持:支持超过 140 种语言的预训练,直接支持超过 35 种语言。
单 GPU 优化:Gemma3 被称为“全球最强的单加速器模型”,在单 GPU 或 TPU 环境下表现显著优于其他同类模型。
推理速度提升:在处理短视频内容时,推理速度提升了47%。
硬件适配:针对 Nvidia GPU 和 Google Cloud TPU 进行了深度优化,确保在不同硬件平台上的高效运行。
多种模型大小:提供 18、4B、128 和 278 四种不同尺寸的模型,满足不同硬件和性能需求。
开发工具支持:支持 Hugging Face Transformers、Ollama、JAX、Keras、PyTorch 等多种开发工具和框架。
部署选项多样:支持 Google Al Studio、Vertex Al、Cloud Run、本地环境等多种部署选项。
1.3 gemma 3 技术原理
图像安全分类器:配备 ShieldGemma2图像安全分类器,能检测和标记危险内容、色情内容和暴力内容,进一步提升了模型的安全性。
训练与微调:Gemma3 采用知识蒸馏、强化学习(包括人类反馈和机器反馈)以及模型合并等技术,提升了模型在数学、编码和指令跟随方面的能力。提供了更灵活的微调工具,方便开发者根据需求进行定制。
1.4 gemma 3 应用场景
人脸识别:可以识别图像中的人脸特征,用于身份验证、安防监控等场景。
物体检测:能检测图像中的物体,识别其类别,例如在工业生产中检测产品质量问题。
智能助手与聊天机器人:Gemma3可以理解多种语言的自然语言指令,生成自然流畅的回复,为用户提供智能的交互体验。
文本分类与情感分析:能对文本进行准确的分类,判断文本的情感倾向,例如判断评论是正面还是负面。
短视频内容分析:能处理短视频内容,提取关键帧,分析视频中的场景和事件。
二、安装Docker、Dify
安装Docker、Dify并配置可以直接参考我部署Deepssk的第一步骤和第四步骤
三、部署gemma3:12b
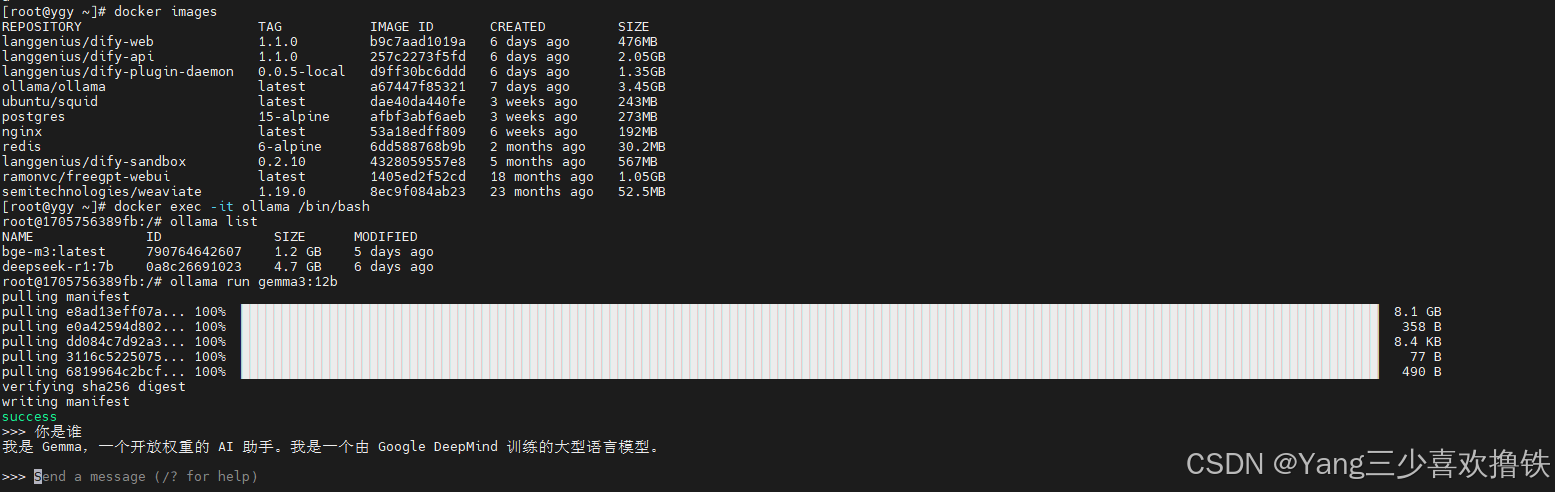
3.1 运行gemma3:12b
#运行服务
ollama run gemma3:12b
四、Dify集成gemma3:12b
4.1 登录Dify并安装ollama插件
Dify 社区版默认使用 80 端口,点击链接 http://your_server_ip 即可访问你的私有化 Dify 平台
4.2 ollama中添加gemma3模型
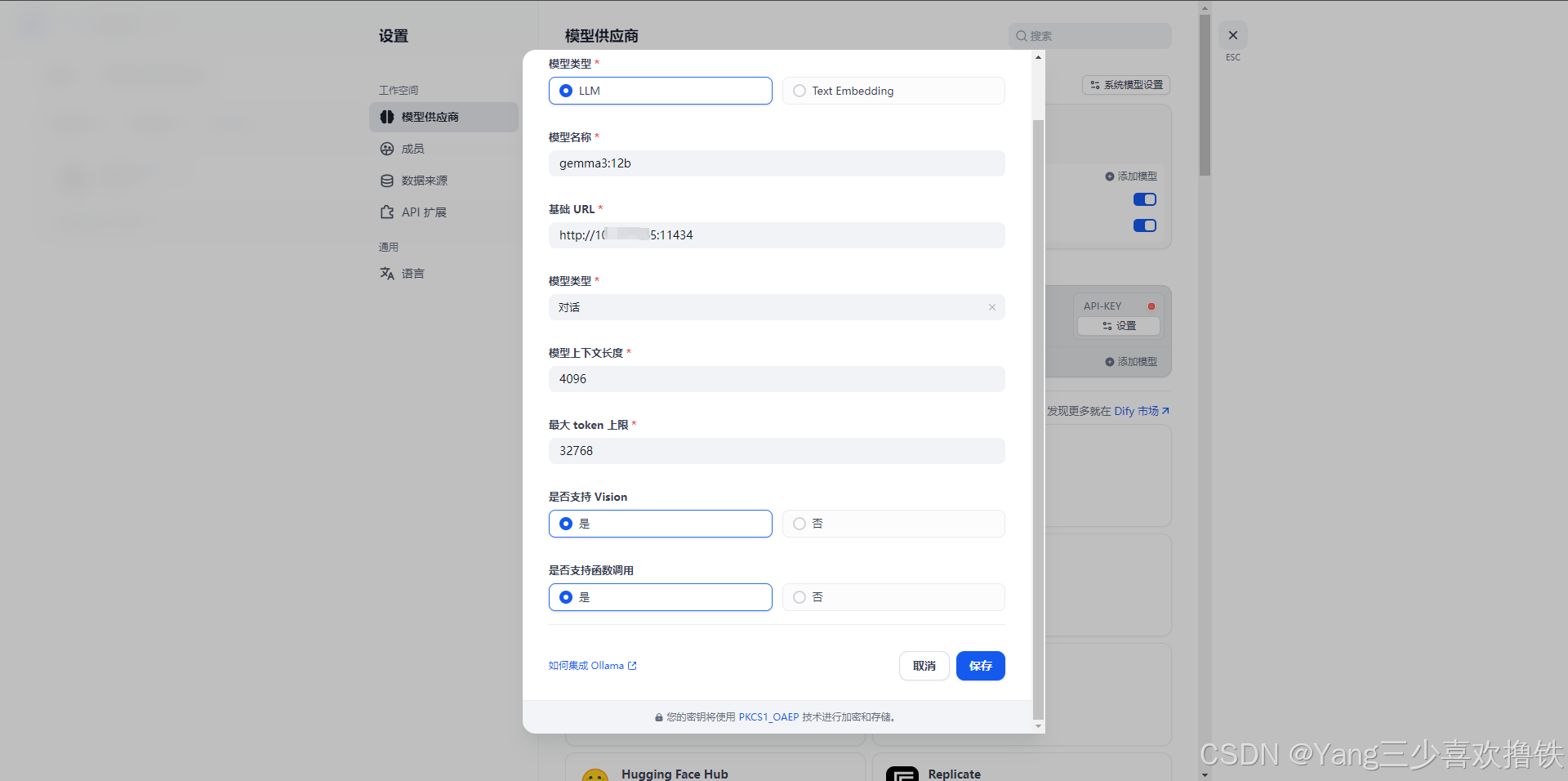
选择 LLM 模型类型。模型名称,填写具体部署的模型型号。上文部署的模型型号为 gemma3:12b,基础 URL,填写 Ollama 客户端的运行地址,通常为 http://your_server_ip:11434。如遇连接问题,请参考常见问题。其它选项保持默认值,最大生成长度为 32,768 Tokens。
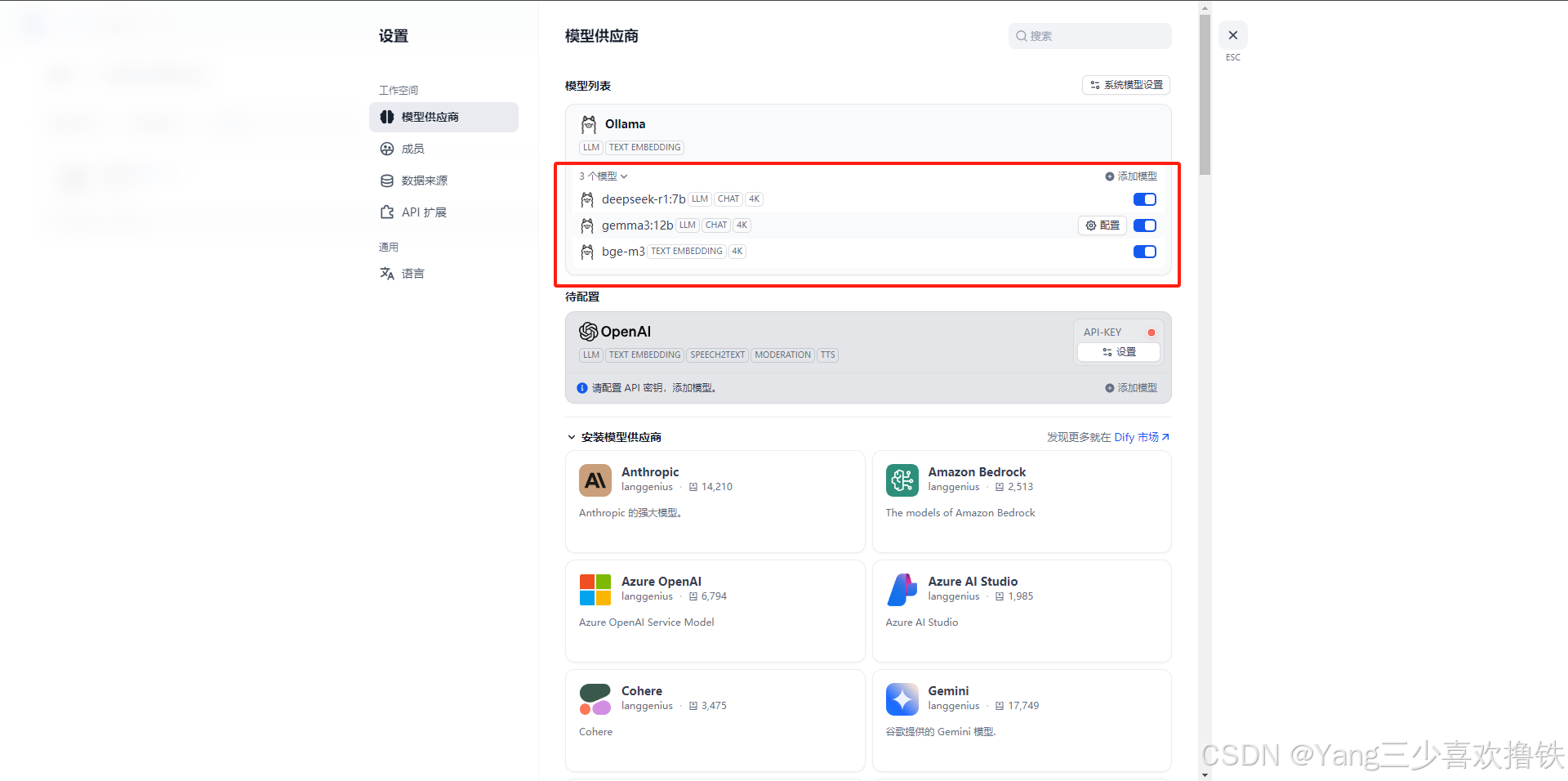
4.3 查看ollama中添加的模型
4.4 首页创建空白应用
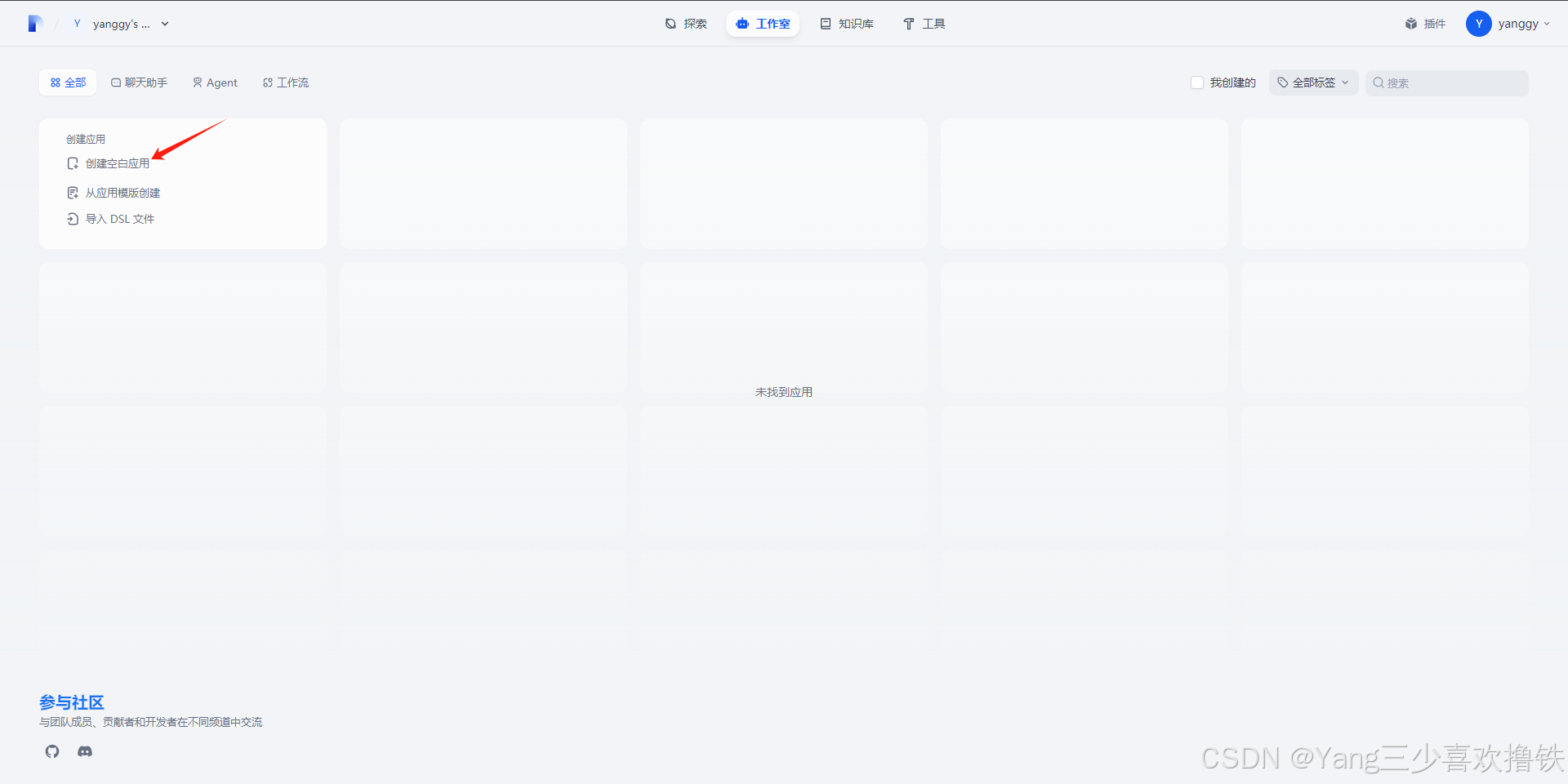
4.5 选择应用类型和命名AI
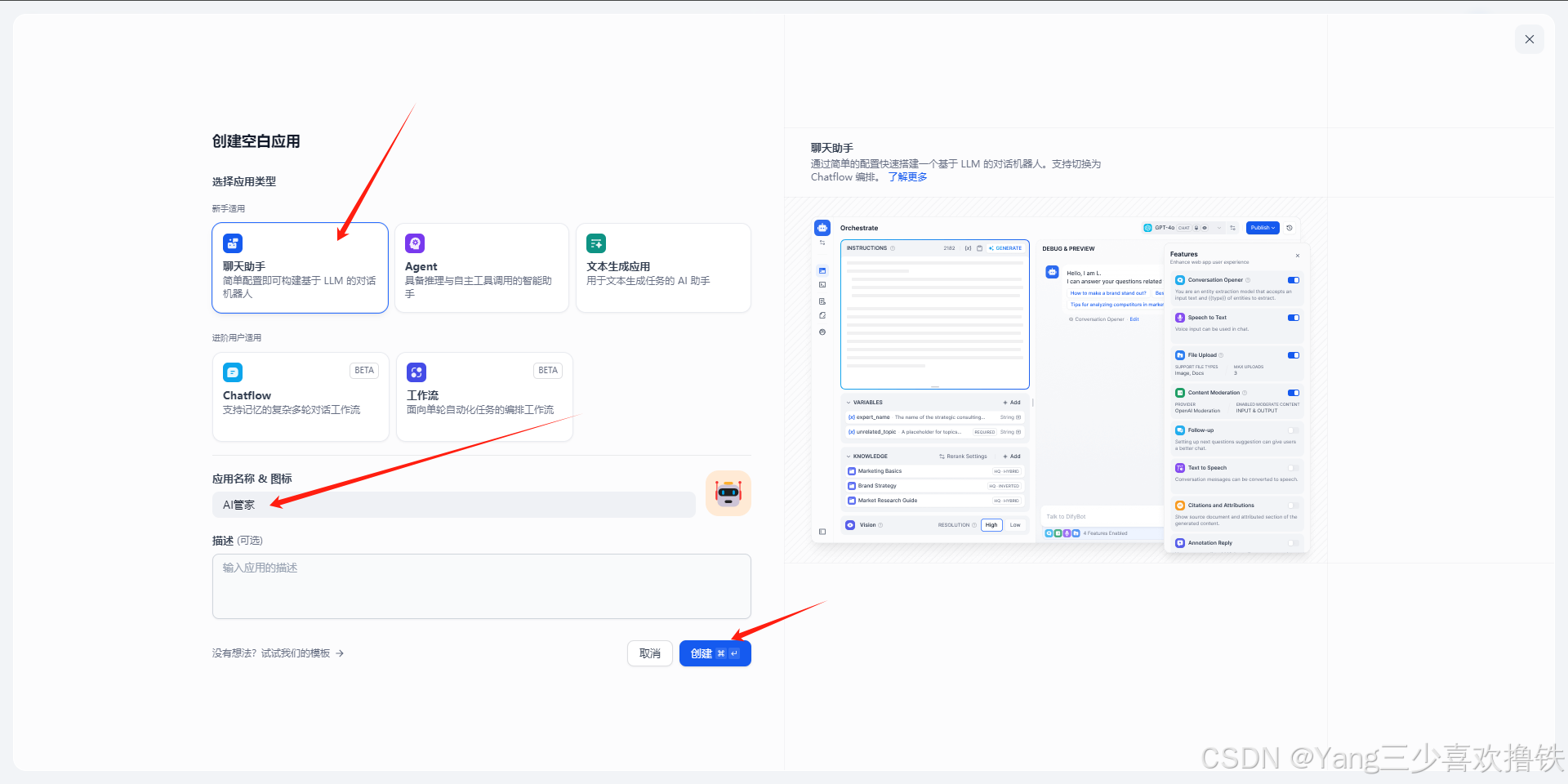
4.6 右上侧选择gemma3模型
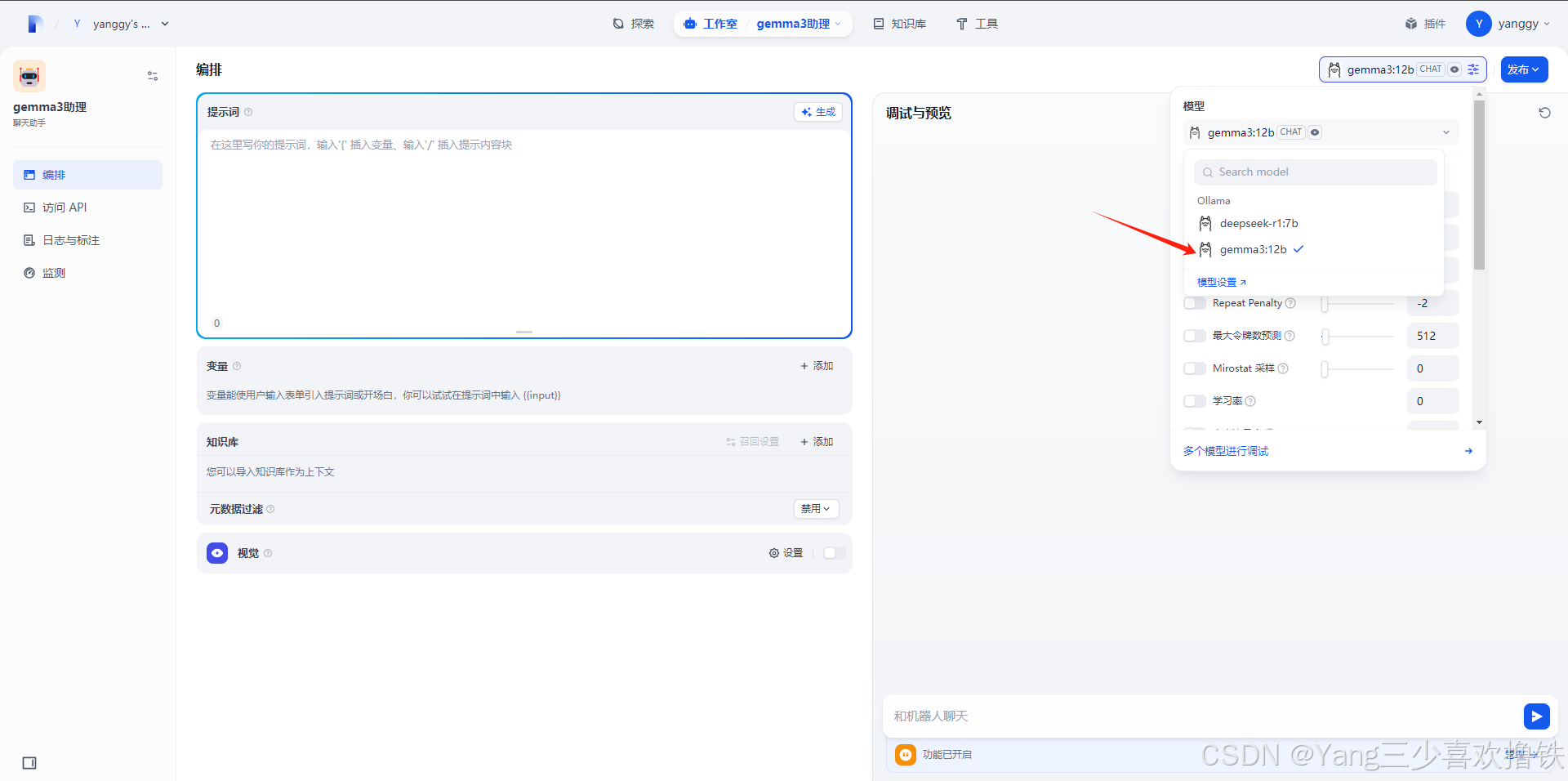
4.7 正常对话
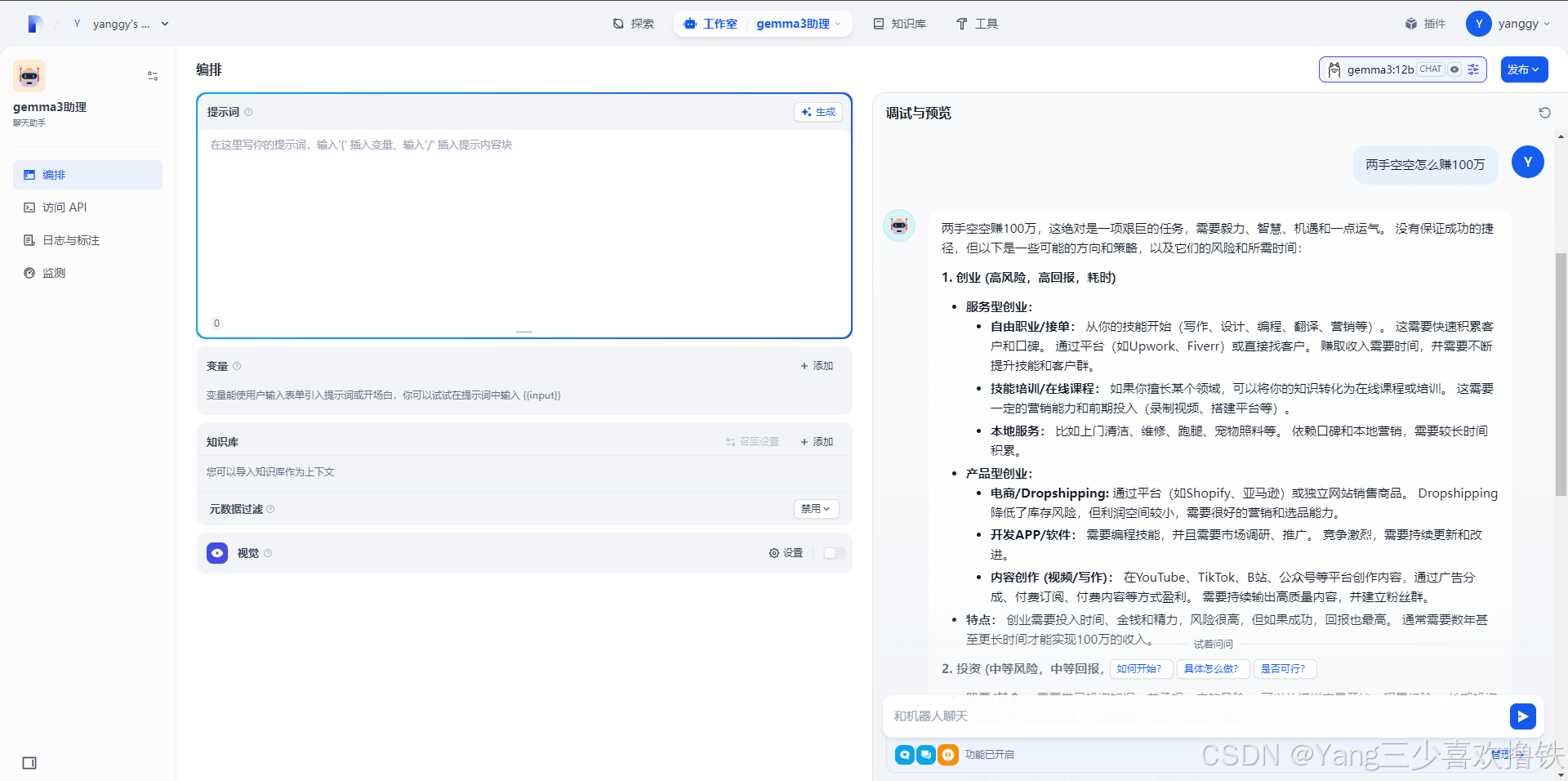
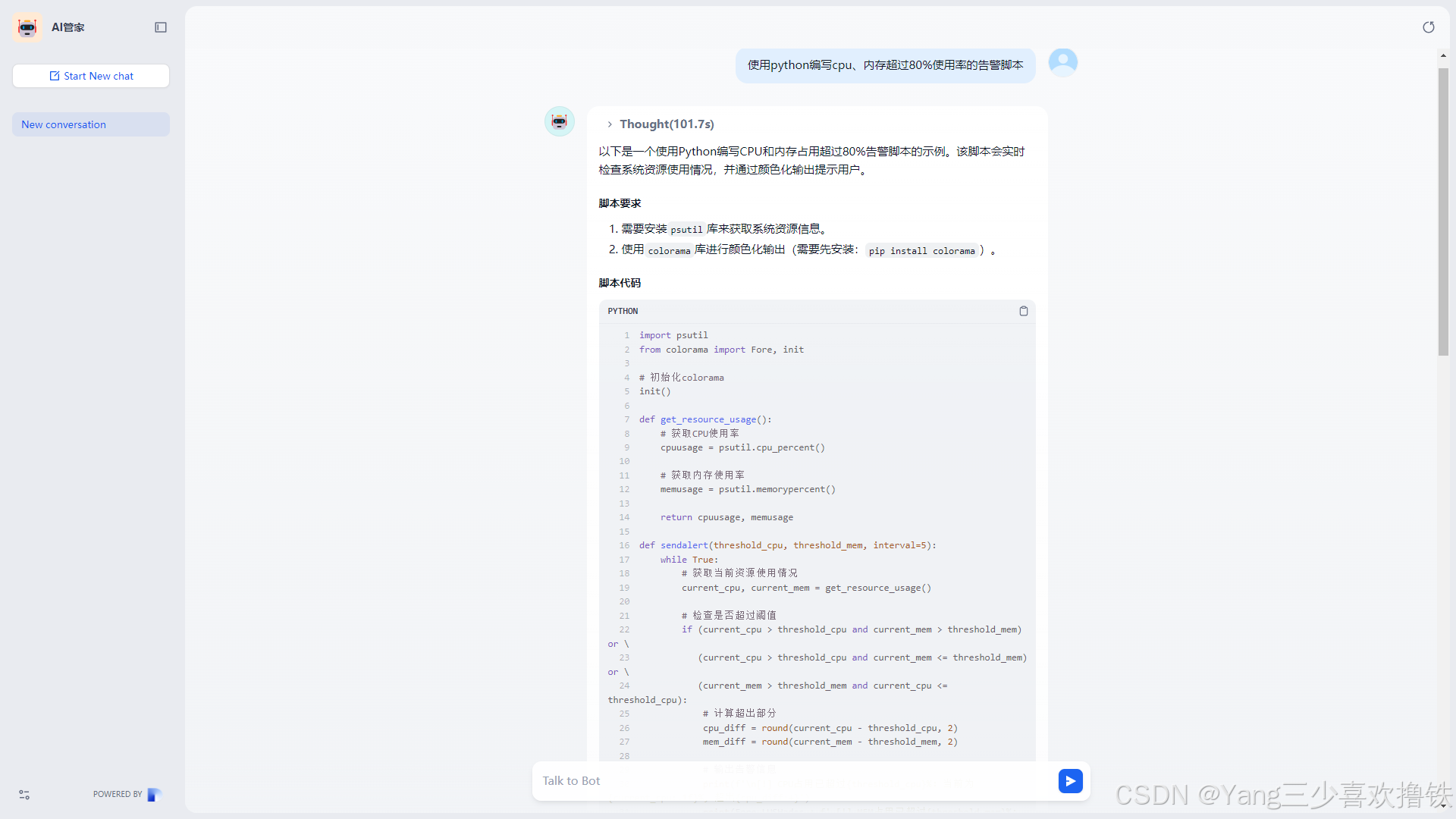
4.8 代码方面逻辑清楚

















 6463
6463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









