









我们之前讨论的情况都是建立在样例线性可分的假设上,当样例线性不可分时,我们可以将特征映射到高维,这样很可能就可分了。然而,映射后我们也不能保证一定可分。从下图我们可以看出,当样本中有一个离群点时就会很大的影响到的超平面的位置。再有甚者,如果离群点在另外一个类中,那么这时候在当前维度就是线性不可分了。而我们也没有必要因为少量的这种样本而去继续映射升维。
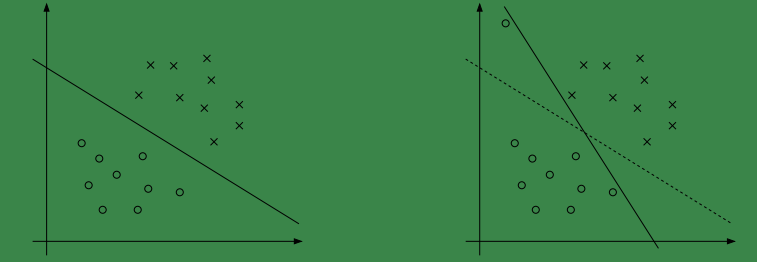
那怎么办呢,我们需要将模型进行调整,以保证在不可分的情况下,也能够尽可能地找出分隔超平面。
为了能够应对这种问题,改写我们的优化问题如下:
minδ,w,b12||w||2+C∑i=1mξis.t. yi(wTxi+b)≥1−ξi, i=1,...,mξi≥0, i=1,...,m
其中 ξi 称为惩罚项(也叫 松弛变量);C是一个权重,控制惩罚项对目标函数的影响程度。
因为现在的最小函数间距为 1−ξi 这样我们就允许存在函数间距小于1的样本了(也有可能小于0),并且在目标函数中要加上 Cξi ,补偿计算函数距离时的损失。
模型修改后, 拉格朗日公式也要修改如下:
L(w,b,ξ,α,r)=12wTw+C∑i=1mξi−∑i=1mαi[yi(xTw+b)−1+ξi]−∑i=1mriξi
上式中 α和r 是拉格朗日算子(这里有两个不等式约束)。我们和之前一样将该式看作是变量 w 和 b 的函数,分别对其求偏导,并令导数为0,得到 w 和 b 的表达式。然后代入公式中,求带入后公式的极大值。整个推导过程类似以前的模型,这里只写出最后结果如下:
maxα W(α)=∑i=1mαi−12∑i,j=1myiyjαiαj<xi,xj>s.t. 0≤αi≤C, i=1,...,m∑i=1mαiyi=0
此时,我们发现没有了参数 ξi ,与之前模型唯一不同在于限制条件由 αi≥0 变成了 0≤αi≤C 。并且求 b∗ 的公式也变了。
此时的KKT对偶条件可以得出下面的结论:
αi=0⇒yi(wTxi+b)≥1αi=C⇒yi(wTxi+b)≤10<αi<C⇒yi(wTxi+b)=1
第一个式子表明在两条间隔线外的样本点前面的系数为 0,离群样本点前面的系数为 C,而支持向量(也就是在超平面两边的最大间隔线上)的样本点前面系数在(0,C)之内。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









