






前言
前言
现在大火的stable diffusion系列,Sora,stable video diffusion等视频生成模型都是基于了diffusion模型。而diffusion模型的基石就是DDPM算法(之后有一些diffusion的加速方法,但是原理上还是DDPM),所以需要我们对DDPM有一定的了解,了解了DDPM可以帮助我们更好的理解diffusion模型。
DDPM全称是Denoising Diffusion Probabilistic Models,最开始提出是用于去噪领域。原始论文中数学公式比较多,需要一定的数理基础。
所有的AI设计工具,安装包、模型和插件,都已经整理好了,👇获取~
实际上,DDPM也没那么复杂,我们两个层面上理解下DDPM的过程,分别是基于vae和基于傅立叶变换。 下文中diffusion默认指代的是DDPM文中的diffusion model。
首先,我们可以简单对比下vae和diffusion的推理过程
-
vae 把图像可学习的方式压缩到一个latent space
-
diffusion 把图像通过n step 压缩成噪声,噪声再通过n step 去噪成图像
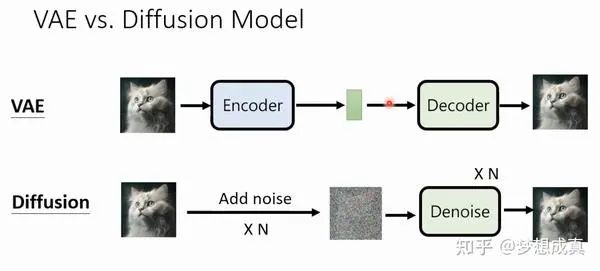
不同于vae encoder/decoder的叫法,diffusion 的两个过程称为前向过程(加噪)和反向过程(去噪),这两个过程的中间态是一个和输入图像相同尺寸的高斯噪声。 而vae是通过数据驱动的方式压缩到一个一维隐空间,这个隐空间也是一个高斯分布,并且不需要n step,而是只需要 1 step。
那其实主观上,可能我们觉得vae多直接啊,而且非常优雅!为啥不用vae?确实,生成模型用了很长时间vae,最后gan变成主流,现在是diffusion。生成模型越来越复杂了。 为什么越来越复杂大家还要用?最简单的解释就是,diffusion虽然很麻烦,但是效果好啊,架不住可以新发(水)几篇paper啊 ️。了解光流的同学一定听过RAFT等一个网络不够,我就cascade(级联)多个网络去学习的范式,diffusion也是类似的想法,但是这里并不是简单的把级联,diffusion建模的是信号本身的restoration,意味着diffusion这套建模可以用到1维分布、2维分布、一直到N维分布都可以。 这非常重要,接下来我们从第二个点进一步了解。
第二,我们可以通过傅立叶变换的思路去理解diffuison。不了解傅立叶变化的我简单说下,就是用一系列不同频率的余弦函数我们可以逼近任意的时域分布。
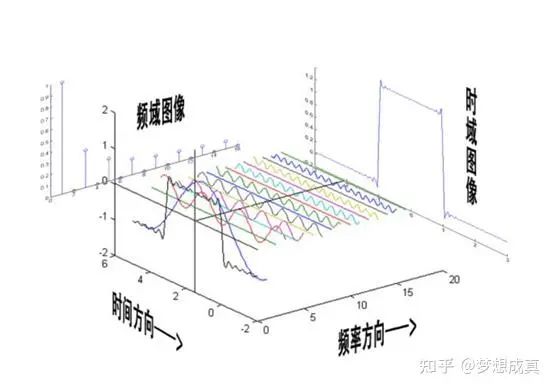
我们看最右边蓝色时域分布是一个非常奇怪的分布,实际上可以在频域拆解成若干 不同频率的余弦去表达。那么理论上,余弦可以表达任意分布!
我们学过中心极限定理:无论原始数据的分布如何,只要样本量足够大,这些样本均值的分布将近似为正态分布。我们再回过头看看,为什么我们能从一个高斯分布,通过diffusion model 还原出clear image,甚至是segmentation mask,depth等等表达,都是因为我们的源头是一个包含了所有可能分布的总和啊!
DDPM
我会通过尽可能简单的语言,带大家一起理解
-
diffsuion 前向过程 和 反向过程的基本数学表达
-
为什么diffusion 的loss是那么设计的
-
diffusion 训练/推理的时候是如何运作的
基本符号
diffusion原文中用 表示clear image, 表示高斯噪声, T一般都很大, 比如1000。 表示中间的图像和噪声混合的中间态, t越大, 混杂的噪声越大。
表示去噪过程中给定 的分布。
表示加噪过程中给定 的分布。
前向过程(加噪)
加噪过程为前向过程

忽略化简过程,整个马尔可夫链可以表示为
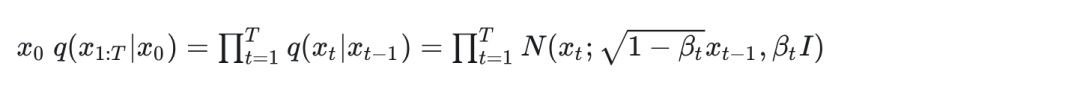
首先需要理解的是。
这里的 可以表示为 , 很明显, 这个正态分布的均值方差如下:
-
表示均值, 均值是
-
方差是 的正态分布,
那么根据正态分布的性质,我们可以得到如下转换:
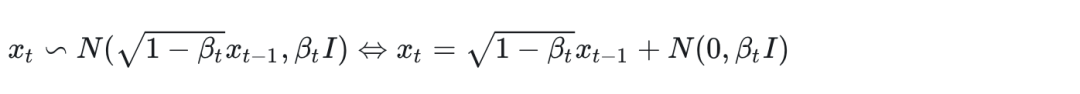
所以最后 , 看起来就非常清晰了。 就是 和一个高斯噪声加权 得到的。这里的权重 和噪声水平相关。当噪声比较大的时候, 信号的权重比较小, 相反, 当噪声比较小的时候, 图像权重比较大。一般来说 都比较小, 且小于1。
根据上面的式子, 我们可以直接递推出,给定 的情况下, 的分布 。这对后面损失函数 的化简有帮助。不要惧怕新的符号, 这里的 并且 只是为了美观引入了新的变量, 让表达式更加简洁。也就是说在diffusion 加噪过程中, 只要知道了 clean image 和 , 就能推导出任意时刻的 。
所以我们也需要理解
文中称 为 variance schedule。我们需要保证足够大的T的时候, 最后的分布是一个isotropic Gaussian (各向同性的高斯分布)。 值一般在正向过程 中增加(和时间 相关)比如 。
反向过程(去噪)
diffusion的目标是学习reverse process(或者叫 diffusion process),即训练一个**,从噪声还原回干净的图像。**

我们可以写出最开始纯高斯分布的表达式
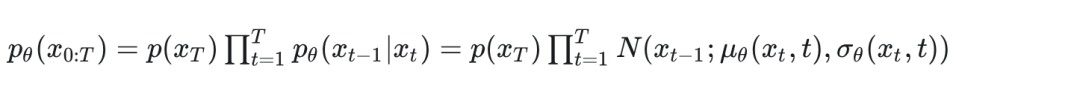
是已知的,我们还可以写出马尔可夫链单步的递推表达式:
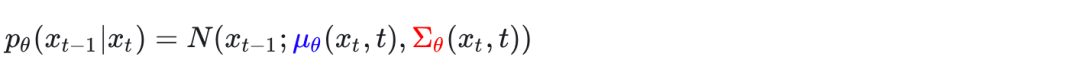
安装上节的写法可以写成
注意,均值 就是DDPM要训练的单元,方差****在DDPM中是固定的,后续DDPM的优化工作也做成可训练的了。
目标函数
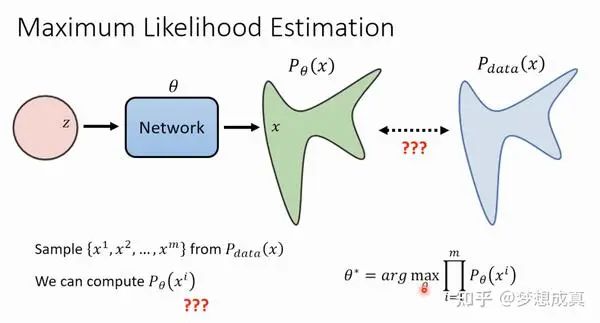
众所周知,生成式网络都是为了让估计出来的分布更加接近真实的分布。由于分布这个东西很抽象,一般都是使用一个dataset,然后都是要最大化网络估计出来的后验分布似然,也就是上图中右下角的公式。实践中,这个公式不能直接优化,需要转化,VAE中优化ELBO也是同理。这里省略推导。
对于扩散模型,扩散模型是通过寻找使训练数据的可能性最大化反向马尔可夫转移来训练的。在实践中,训练等同于最小化负对数似然的变分上界。
了解KL 散度的同学应该知道,这个问题就是要 优化 KL 散度,使得预测的分布更加接近真实分布。更直观的可以看下图,红色表示真实分布,蓝色表示预测分布。
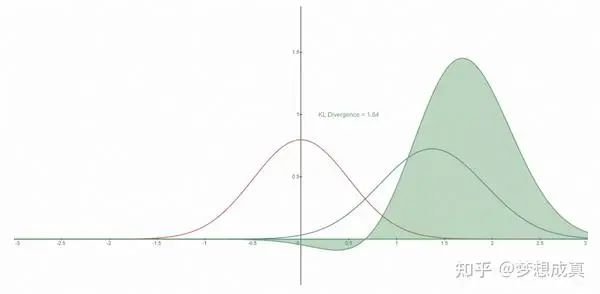
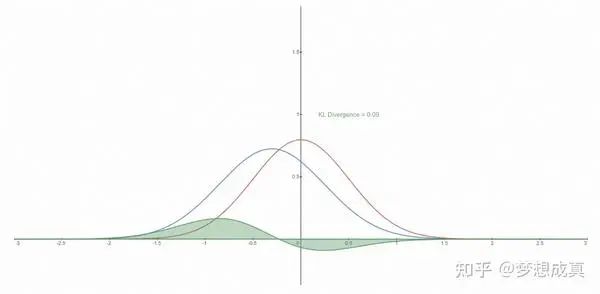
DDPM 把负对数的上界叫vlb,其实就是 负的ELBO。最终要优化的目标是

其中
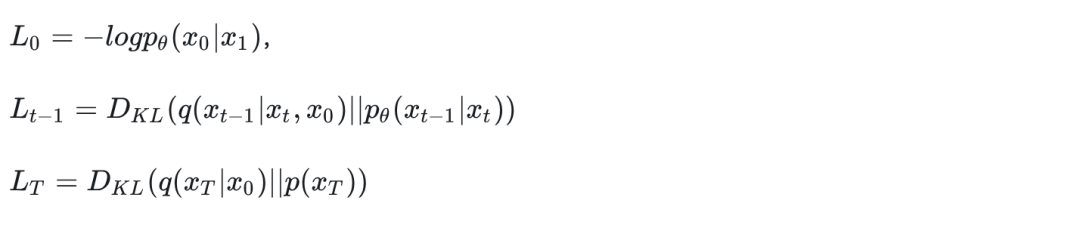
上式中, target distribution predicted distribution)表示KL 散度。接下来,我们分别解释下
中 . 没有可学习的参数, 所以在训练的时候 是一个常量, 可以直接忽略! 的取值范围是 , q (.) 没有可学习的参数, target 分布是 的原因是化简的过程中用到了贝叶斯公式。我们可以写出预测的分布 的表达式:

在DDPM中,假设**多元变量高斯分布是具有相同方差的独立高斯分布的乘积,这个方差值可以随时间t变化。**在前向过程中,**我们将这些方差设置为相同的大小。**t比较小的时候,方差比较小,t比较大的时候,方差比较大。最终方差值没有采用学习策略,而是经验设置了常数,如下:

所以预测的分布 变成了
注意! 中另外一项 和 都是通过配方法配的权重, 具体参数见论文下式
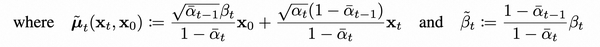
注意:上面的 在推理过程中是不知道的!!!所以需要利用网络进行预测!!!
这里是为了美观,设置了两个变量 并且
所以,有趣的来了,我们不难看出,对于两个高斯分布求KL散度,变量还只有均值项,所以可以直接写成MSE的形式,因为它们肯定是正相关的。
, 而作者实验发现在预测 的时候给定timestep t会取得更好的效果。
还记得前向过程中, 我们推导得到给定 的情况下, 的分布 吗? 我们可以简单的表达 。
作者为了清晰起见定义了一个 是噪声, 符合 0 均值, 1 方差的正态分布。 变成了 是因为对于一个正态分布, 乘一个系数, 方差会变成系数的平方哦。
我们再把因变量放进去就可以得到 , 带入这个式子到
可以得到最终需要预测的表达式是:

所以简化为 必须预测 , 因为我们输入中已经包含了 了,,所以我们就必须要预测噪声!

是可学习参数,就是一个可学习的噪声预测器。带入到最终损失函数表达式,我们可以得到
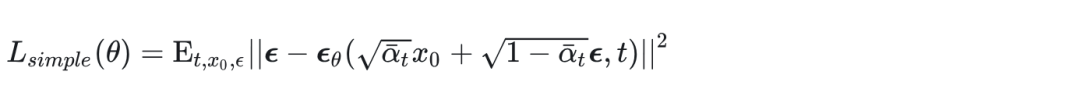
我们可以简单理解下 这个损失函数,这个损失函数有两个参数,一个是,我们可以理解为带有噪声的图像(clean image 和 noise 以一定的权重相加),另一个就是t,也就是到了中间哪个timestep。
网络结构
理论上,对网络结构的要求只有输入和输出维度一致。 作者最后选择了U-Net也不足为奇。

总结

对于training
repeat 表示 重复2-5行直到收敛
第二行表示从数据集中采样一张clean image,q 表示一个真实的数据分布
第三行表示从1-T(T很大,比如1000),采样一个t
第四行表示是噪声,从零均值,1方差的正态分布采样
最终的损失函数如 ,是在restore noise 而不是图像!最后计算的是restored noise 和 real noise 之间的MSE。
对于Sampling
也就是推理过程,实际上就是要递推
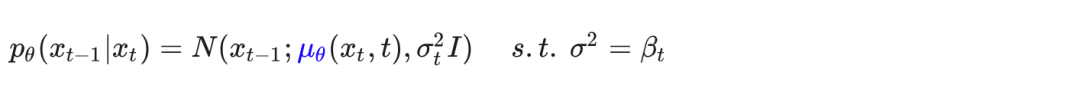
而我们网络学习到的,代入即可得到 算法2中第四行的式子
剩余细节
的处理我们还没有讲, ,简单提一下。在反向过程结束时,回想一下我们正在尝试生成一个由整数像素值组成的图像。因此,我们必须设计一种方法来获取所有像素上每个可能像素值的**离散(对数)似然。**详细的推导就不介绍了。

DDIM加速
DDIM(Denoising Diffusion Implicit Models)是后来提出的一种加速DDPM的方法,现在diffusion大多用的这个方法,一般可以加速差不多20倍,DDIM和DDPM有相同的训练目标,但是它不再限制扩散过程必须是一个马尔卡夫链,这使得DDIM可以采用更小的采样步数来加速生成过程,DDIM的另外是一个特点是从一个随机噪音生成样本的过程是一个确定的过程(中间没有加入随机噪音)。
如何加入condition
在最开始的时候,我买了一个坑说DDPM是从噪声还原出任意分布的一种建模方式,那么如何加入有效的引导,使这个生成变得可控呢?不妨看看google 的 Imagen,基于text 引导的 图像生成网络
https://www.assemblyai.com/blog/how-imagen-actually-works/#how-imagen-works-a-deep-dive
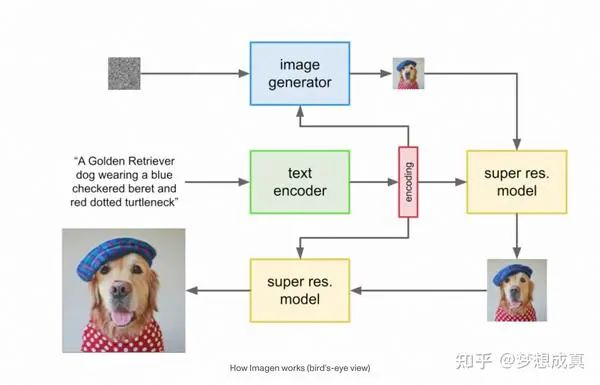
Imagen的流程如下
首先,将 caption 输入到一个 text encoder 中。这个 encoder 将文本形式的 caption 转换成一个数值表示,它封装了文本中的语义信息。
接下来,一个 image-generation model 通过从噪声,或者说 “TV static” 开始,逐渐将其转化为一个输出图像。为了引导这个过程,image-generation model 接收 text encoding 作为输入,这起到通知模型 caption 中包含了什么内容的作用,以便它能创建一个相应的图像。输出结果是一个小尺寸图像,它视觉上反映了我们输入到 text encoder 的 caption。
这个小尺寸图像随后被传递到一个 super-resolution model 中,这个模型将图像的分辨率提高。该模型同样将 text encoding 作为输入,这帮助模型决定在增加我们图像大小四倍时,如何填补由此产生的信息缺失。最终结果是我们所期望的中等大小的图像。
最后,这个中等大小的图像再被传递到另一个 super-resolution model 中,这个模型的运作方式与之前的几乎完全相同,只是这次它接收我们的中等大小图像,并将其扩大成一个高分辨率图像。成品是一个 1024 x 1024 像素的图像,它视觉上反映了我们 caption 中的语义。
在训练过程中,text-encoder 是冻结的,这意味着它不会学习或改变它创建 encodings 的方式。它只用于生成输入到模型其他部分的 encodings,而模型的这些部分是被训练的。
文本条件的引入
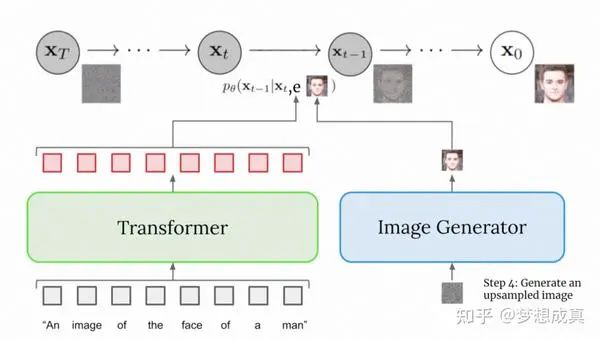
我们可以看下面这张图,实际上就是diffusion的反向过程中,他的条件加入了一个由文本编码得到的embedding。
这里分享给大家一份Adobe大神整理的《AIGC全家桶学习笔记》,相信大家会对AIGC有着更深入、更系统的理解。
有需要的朋友,可以点击下方免费领取!
AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
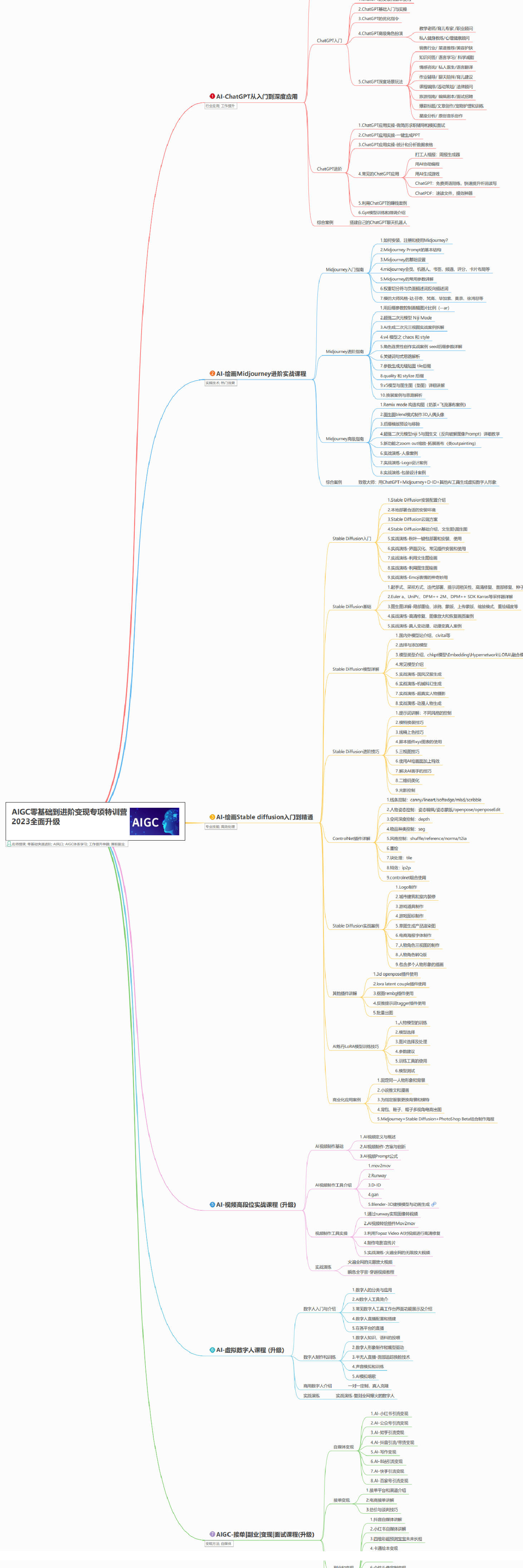
AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC

有需要的朋友,可以点击下方卡片免费领取!

精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。
AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。


















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









