






最近,AI圈又被OpenAI“狠狠地”刷了一波存在感。
在4月14日的发布会上,OpenAI正式带来了新一代多模态大模型——GPT-4.1。不仅有性能层面的质变提升,还有Mini和Nano轻量级系列同步登场,简直是一场AI技术的“大秀场”。
今天就来带大家一起深扒GPT-4.1发布会的全貌,不夸张、不吹捧,用通俗易懂的方式,看看这代AI究竟厉害在哪,又有哪些实际意义。
🧠 一句话总结:GPT-4.1,就是“又大、又聪明、还便宜”
如果你没时间看完全场发布会,只记住这一句也行:
GPT-4.1支持百万级上下文窗口、推理能力更强、代码能力爆炸提升,还便宜了不少。
是的,这代GPT基本把“更强、更快、更便宜”三大关键词玩明白了。
🔍 重点一:百万Token上下文,长文、代码、小说都能Hold住!
GPT-4.1最大的“亮眼更新”,毫无疑问是它的上下文窗口扩大到了惊人的100万个Token。
什么意思?
想象一下你给它一部《三体》小说全文、一个100页的产品技术文档、或是一整份代码库——GPT-4.1可以一口气“读完”它们,并在此基础上生成、归纳、重写、甚至修bug!
要知道,前一代GPT-4o最多128K token,GPT-4只有32K,而现在直接干到了1M,这不仅是“升级”,是代际飞跃。
📌 实际用途:
-
长文档翻译/总结
-
小说续写、重构剧情
-
阅读并调试大型代码库
-
做“AI助理”处理长对话历史(比人还记得清)
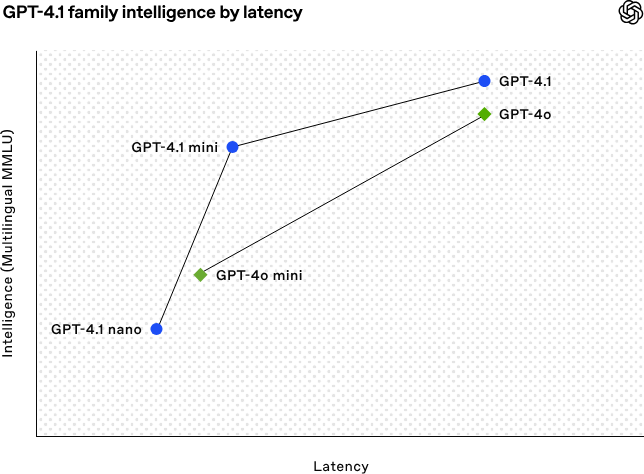
💻 重点二:代码能力大提升,能当副程序员了
本次发布会演示了GPT-4.1在编程上的爆发性进步:
- 在SWE-Bench基准测试中得分高达55%,比GPT-4o高出21%
- 可以一次处理8倍以上的代码量
- 能读懂依赖关系复杂的代码模块,进行自动重构或修复
甚至演示了:只需要一个任务描述,它就能写出一整套语言学习App的前后端代码,配UI、处理逻辑、还能解释写法。
真正实现了“你说我写,你改我调”。
这对开发者、创业者来说,简直就是效率天花板 + 成本救世主。
🧩 重点三:三款模型,按需选配更灵活
这次不仅有“正代旗舰GPT-4.1”,还同步上线了两个版本:
| 模型 | 特点 | 适用场景 |
|---|---|---|
| GPT-4.1 | 百万上下文 + 全功能 | 高性能需求、企业部署 |
| GPT-4.1 Mini | 精简 + 性价比,功能保留 | 移动端、小模型推理 |
| GPT-4.1 Nano | 超轻快,极致低资源消耗 | IoT、边缘计算 |
也就是说,不论你是要部署在云端做AGI实验,还是跑在树莓派上监控传感器数据,都能找到合适的选项。

⚡ 重点四:推理更准,执行指令更贴心
GPT-4.1在复杂指令执行方面也更稳定了。
以前你给ChatGPT布置个多步骤任务,它可能中途就“跑偏”了。现在的GPT-4.1对任务的执行逻辑更完整,可以少很多“你听懂没?”的尴尬。
比如:
- 执行一个带逻辑条件的任务:能拆解并按优先级完成
- 理解含糊命令,自动补全语境
- 多轮对话中保持逻辑一致性
这意味着它在智能代理Agent、自动办公助手、甚至AI客服中的表现会更加“像个人”。
💰 重点五:价格打下来,性能拉上去
这波更新不仅仅是“技术+功能”,成本上的优化更是令人惊喜:
- 推理速度提升40%
- API调用成本降低80%
- 多项接口统一,开发者体验更流畅
OpenAI这次明显在做厚开发者生态。更便宜、更快、更稳定,对想做AI产品的公司和个人来说,门槛拉低了不止一点点。
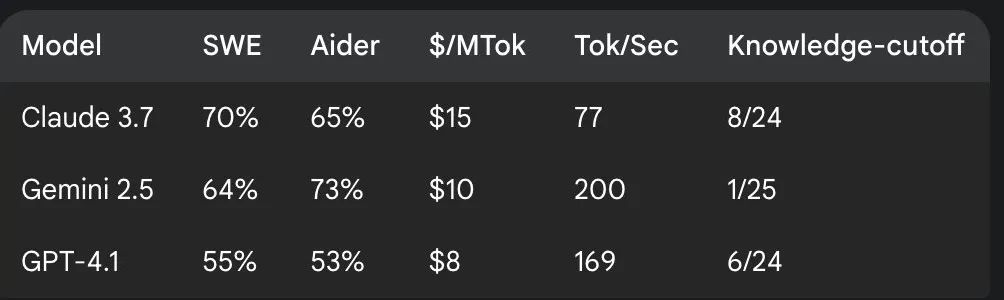
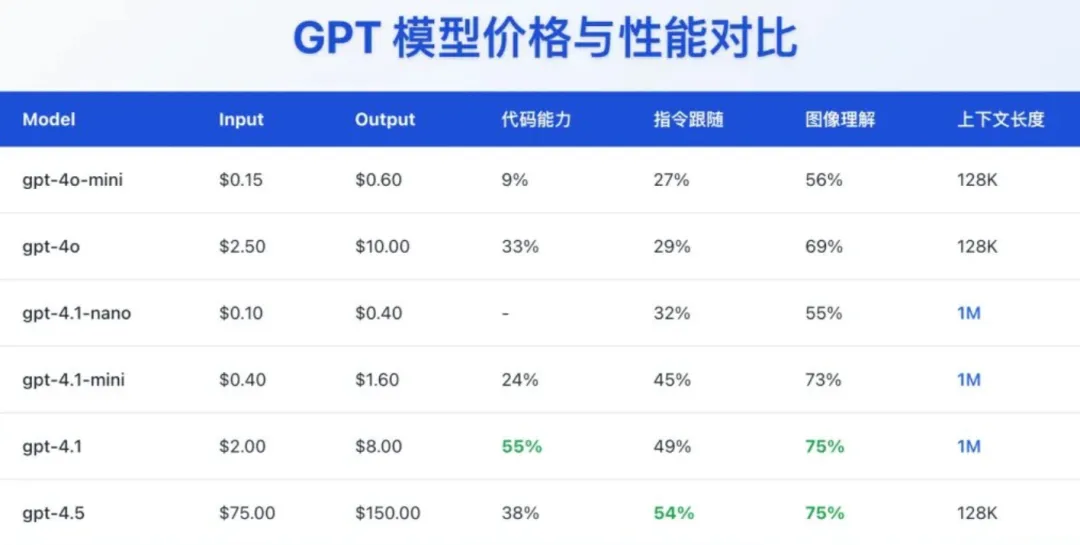
📝 重点六:记忆功能增强,对话更个性化
GPT-4.1还升级了“记忆系统”:
- 能记住你是谁、喜欢什么、过往说了什么
- 在多次对话中表现出更好的上下文延续性
- 可在后台手动查看和管理记忆内容(可删除/关闭)
这对常用ChatGPT的个人用户来说,是一次交互体验的进化。
从**“单次智能体”变成“有记忆的智能伙伴”**,这不就是传说中的“数字分身”雏形嘛。
📉 不吹不黑:GPT-4.1的短板也要说
虽然GPT-4.1的升级几乎覆盖了全方位,但也并非“完美无缺”,以下几点依旧需要理性看待:
-
上下文虽长,生成内容仍有“跳脱”可能
-
API接口仍非完全开放,部分功能需等待更新
-
轻量模型虽快,但能力差异明显

🔚 总结:GPT-4.1是AI进入实用时代的“催化剂”
GPT-4.1的发布不只是OpenAI的一次技术升级,它宣告着AI正在从“实验室”走向“主战场”:
- 更强大的记忆与推理能力
- 更长的上下文与理解范围
- 更便宜、更快、更普适的部署方式
无论你是开发者、产品经理、运营、创业者,还是单纯对AI感兴趣的普通人,都可以从GPT-4.1中找到属于自己的“打开方式”。
GPT-4.1的到来,也许就是这个时代的“起点”。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

















 1158
1158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









