







前言
看了mnist和cifar的实例,是不是想我们现实中一般都是一张张的图片,和实例里面都不一样呢?那么如何来进行训练呢?为了能够简便点,我们就不自己去采集数据集了,因为第一自己采集的数据集量可能不够,第二,采集的数据集可能标注有很大问题,比如噪声太多等,第三针对每一种数据,我相信有不同的模型去进行classification,并不是一味地套用别人的模型,当然也可以在别人基础上做微调fine tuning。
在这一个教程中,我们利用cifar数据集去模拟现实中的训练。
如果你有自己的数据,可直接进行第二步
第一步
cifar数据集的可视化。读者如果有自己数据集,可以忽视此步骤,此步骤主要用于将cifar 的数据全部转为png图片,并制作相应标签。
先看看我的代码的目录结构:
接下来介绍每一个文件的由来:
①test和train文件夹是我用来存储cifar每一张图片的位置,一个是训练集、一个是测试集
②几个mat文件,从cifar的官网去下载matlab version的数据集,解压就可以得到。
③几个.m文件就是我们用来可视化以及图片转存的代码。
下面看这几个程序:
ReadImage.m
function image = ReadImage( data )
%data是一维的,1*3072,转换为32*32*3的图片
image(:,:,1)=reshape(data(1,1:1024),32,32);
image(:,:,2)=reshape(data(1,1025:2048),32,32);
image(:,:,3)=reshape(data(1,2049:3072),32,32);
end
%cifar转image,可视化
%N*3072维度,每1024分别代表RGB,图像大小32*32
clear
clc
load('batches.meta.mat')
numpic=0;
fp=fopen('./train/train_labels.txt','wt');
for i=1:5
count=0;
str=['data_batch_' num2str(i) '.mat'];
fprintf('load %s\n',str);
load(str)
figure(1)
set (gcf,'Position',[50,50,900,900], 'color','w')
for j=1:size(data,1)
%% 读取图片和标签
count=count+1;%每次可视化计数subplot位置
numpic=numpic+1;%为图片编号从1开始,规则:序号+图片标签(1-cat,2-frog)
image=ReadImage(data(j,:));%按顺序读取图片
label=label_names{labels(j,1)+1};%读取对应标签名字
%% 每读100张显示一次图片
subplot(10,10,count)
image=uint8(image);
imshow(image);
title(label)
if mod(count,100)==0
count=0;
pause(0.1)
end
%% 存储在文件夹train中
picture_name=['./train/' num2str(numpic) label '.png'];
name=[num2str(numpic) label '.png'];
imwrite(image,picture_name,'png')
fprintf(fp,'%s %s\n',name,num2str(labels(j,1)));
end
end
fclose(fp);read_test.m
%cifar转image,可视化
%N*3072维度,每1024分别代表RGB,图像大小32*32
clear
clc
close all
load('batches.meta.mat')
numpic=0;
fp=fopen('./test/test_labels.txt','wt');
fp1=fopen('./test/test_labels1.txt','wt');
count=0;
load test_batch.mat
figure(1)
set (gcf,'Position',[50,50,900,900], 'color','w')
for j=1:size(data,1)
%% 读取图片和标签
count=count+1;%每次可视化计数subplot位置
numpic=numpic+1;%为图片编号从1开始,规则:序号+图片标签(1-cat,2-frog)
image=ReadImage(data(j,:));%按顺序读取图片
label=label_names{labels(j,1)+1};%读取对应标签
%% 每读100张显示一次图片
subplot(10,10,count)
image=uint8(image);
imshow(image);
title(label)
if mod(count,100)==0
count=0;
pause(0.1)
end
%% 存储在文件夹test中
picture_name=['./test/' num2str(numpic) label '.png'];
name=[num2str(numpic) label '.png'];
imwrite(image,picture_name,'png')
fprintf(fp,'%s %s\n',name,num2str(labels(j,1)));
fprintf(fp1,'%s 0\n',name);
end
fclose(fp);
fclose(fp1);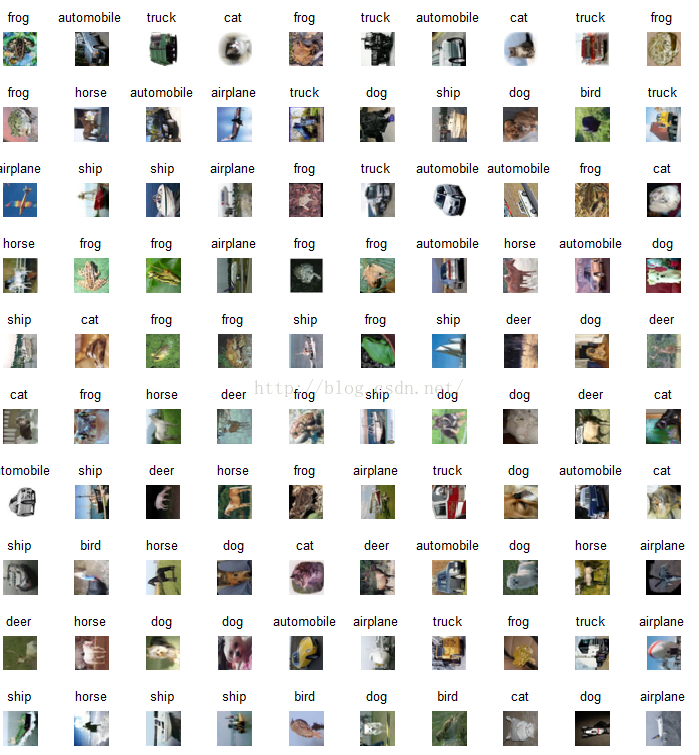
读取完毕以后,在train里面有50000张图片和一个标签txt文件,test里面有10000张图片和两个标签txt,一个是正确标注,一个是全标注为0。
【附cifar的几个文件】
①matlab version的mat文件:链接:http://pan.baidu.com/s/1bUAgf8 密码:wk6t
②读取完毕的train文件夹:链接:http://pan.baidu.com/s/1sl5tqxR 密码:krhn
③读取完毕的test文件夹:链接:http://pan.baidu.com/s/1mhJ0vXI 密码:o69i
好了,至此我们已经得到了现实中经常使用的数据格式。
【注】如若想掰正图像,可以使用 qq_35446561提供的方法解决
subplot(10,10,count)
image=uint8(image);
image=permute(image,[2,1,3]);%加上这句话会好一些
imshow(image);第二步
以cifar的test集的制作为例吧。
先说一下现实基础:数据集必须分为两个文件夹(一个train,一个test),然后每一个文件夹必须再分文件夹,每一个文件夹代表一类数据。
比如cifar,上面提取的数据分别存储在train和test文件夹,但是并未归类。那么,我在E:\CaffeDev\caffe-master\data\cifar10\cifar-visual\cifar10内新建一个文件夹test,然后在test内部新建了airplane、cat、frog三个文件夹,在每一个文件夹中分别放入了从第一步提取的 test 集中随便取的对应类别的56张图片。
还是看一下目录结构吧
云盘分享可以看出目录结构:链接:http://pan.baidu.com/s/1i5nuKb7 密码:xlr4
接下来就是读取每一张图片,并且添加相应的数据标签到txt里面去了,在E:\CaffeDev\caffe-master\data\cifar10\cifar-visual\cifar10新建了一个test_label.txt,然后使用matlab书写文件写入的代码:
【注】一定千万要记住,图片名字不要有空格。
%读取图片,制作cifar测试集
fprintf(2,'Reading test data.... \n');
rt_data_dir = './test_cifar'; %测试集的根目录
data_dir='test_cifar'; %标签txt中不需要根目录前面的./,所以新建一个变量存储
subfolders = dir(rt_data_dir); %根目录结构
totalclass=0;%用于存储有类别数
fp=fopen('test_label.txt','wt');
for ii = 1:length(subfolders),
subname = subfolders(ii).name;%获取根目录下的所有文件夹名称
%有两个隐藏文件夹,用于./和../跳转,读取数据集不需要它俩
if ~strcmp(subname, '.') && ~strcmp(subname, '..'),
totalclass=totalclass+1;%每一个文件夹都是一个类别
label_name{totalclass} = subname; %读取此文件夹的名称,也可以自己建立一个标签集,依次取
data = dir(fullfile(rt_data_dir, subname, '*.png')); %取出所有后缀为png的数据
c_num=length(data);%当前类别有多少个数据
for jj=1:c_num
name=fullfile(data_dir, subname, data(jj).name);
fprintf(fp,'%s %s\n',name,num2str(totalclass-1));%从0开始编号
end
fprintf(1,'正在处理类别:%s\n',label_name{totalclass});
end
end
主要功能就是完成了当前目录下的test文件夹下每一个类别的全部数据的文件名(比如\test_cifar\airplane\9483airplane.png)读取,并且写入到txt里面。
第三步
转换leveldb格式
主要调用caffe.sln编译完毕得到的convert_imageset.exe这个程序,首先看一下使用说明
按照这个说明,首先是找到exe的路径,然后是数据集文件夹,数据集标签,转换以后的数据存储位置,-backend设置转换格式(leveldb/lmdb)
【注意】如果是你自己的数据集,这个地方的标签一定要注意,读取的时候是按照“数据文件夹/标签内容”依次读取的,不然无法读取成功。比如在下例中,如果你的标签内容第一行为airplane\9483airplane.png,数据集文件夹是test_cifar\ 那么读取的时候就是test_cifar\airplane\9483airplane.png,但是如果标签内容为test_cifar\airplane\9483airplane.png,那么读取的时候就读取test_cifar\test_cifar\airplane\9483airplane.png ,显然读取失败,不存在此文件,因为前面重复了根目录,这个地方一定要注意。
转换数据使用的convert.bat内容如下:
E:\CaffeDev\caffe-master\Build\x64\Debug\convert_imageset.exe ./test_cifar/ test_label.txt test_leveldb -backend=leveldb
pause也可以设置一下[FLAGS]重新把所有的图像resize一下,注意caffe的输入数据集必须是统一大小
更新日志2017-1-9
这个地方resize开始写博客的时候写成28*28了,导致caffe -test命令自动终止,而无测试的batch信息,改成32*32的原始大小即可了,这个大小必须和train的数据集的大小相同,不然会导致同一个模型参数,接受了不同尺寸大小的图片输入。
E:\CaffeDev\caffe-master\Build\x64\Debug\convert_imageset.exe --resize_width=32 --resize_height=32 ./test_cifar/ test_label.txt test_leveldb -backend=leveldb
pause
运行时候内容如下:
E:\CaffeDev\caffe-master\data\cifar10\cifar-visual\cifar10>E:\CaffeDev\caffe-mas
ter\Build\x64\Debug\convert_imageset.exe ./test_cifar/ test_label.txt test_lev
eldb -backend=leveldb
I1017 17:25:38.574908 16872 convert_imageset.cpp:86] A total of 168 images.
I1017 17:25:38.584908 16872 db_leveldb.cpp:18] Opened leveldb test_leveldb
I1017 17:25:38.768919 16872 convert_imageset.cpp:150] Processed 168 files.
E:\CaffeDev\caffe-master\data\cifar10\cifar-visual\cifar10>pause
请按任意键继续. . .如果显示的读取图片数量为0,或者图片不存在,那么肯定是文件夹名写错或者是标签问题,确切地说,是标签里面的路径问题,一定要注意这一点。
【注】如果这个步骤你想转换为lmdb格式,只需要修改-backend=lmdb即可。
转换完毕以后可以用已经训练好的模型来测试一下这三类模型(注意区分这时的test虽然取自val,但是作用并非val的作用,而是作为test集的,详细自行查找机器学习三个数据集的作用):链接:http://pan.baidu.com/s/1jHPGMpw 密码:g97n
第四步
总结一下,容易出错的地方在于:
①bat 内部书写出问题,严格按照第三步的几个顺序书写
②标签txt 内部的路径问题,很可能与bat 所书写的根路径重复
训练模型回看前面的
【caffe-Windows】cifar实例编译之model的生成:http://blog.csdn.net/zb1165048017/article/details/51476516
重中之重
【更新日志】2017年5月21日11:50:28
如果是灰度图像,一定要记得convert.bat 要加入一条信息
授人以鱼不如授人以渔,所以我是怎么发现这个问题的,方法就是看数据集转换的说明书

E:\CaffeDev\caffe-master\examples\help1>E:\CaffeDev\caffe-master\Build\x64\Debug
\convert_imageset.exe
convert_imageset.exe: Convert a set of images to the leveldb/lmdb
format used as input for Caffe.
Usage:
convert_imageset [FLAGS] ROOTFOLDER/ LISTFILE DB_NAME
The ImageNet dataset for the training demo is at
http://www.image-net.org/download-images
No modules matched: use -help
E:\CaffeDev\caffe-master\examples\help1>pause
请按任意键继续. . .E:\CaffeDev\caffe-master\examples\help1>E:\CaffeDev\caffe-master\Build\x64\Debu
\convert_imageset.exe -help
convert_imageset.exe: Convert a set of images to the leveldb/lmdb
format used as input for Caffe.
Usage:
convert_imageset [FLAGS] ROOTFOLDER/ LISTFILE DB_NAME
The ImageNet dataset for the training demo is at
http://www.image-net.org/download-images
Flags from ..\..\tools\convert_imageset.cpp:
-backend (The backend {lmdb, leveldb} for storing the result) type: string
default: "lmdb"
-check_size (When this option is on, check that all the datum have the same
size) type: bool default: false
-encode_type (Optional: What type should we encode the image as
('png','jpg',...).) type: string default: ""
-encoded (When this option is on, the encoded image will be save in datum)
type: bool default: false
-gray (When this option is on, treat images as grayscale ones) type: bool
default: false
-resize_height (Height images are resized to) type: int32 default: 0
-resize_width (Width images are resized to) type: int32 default: 0
-shuffle (Randomly shuffle the order of images and their labels) type: bool
default: false
Flags from D:\Work\lib\gflags\gflags\src\gflags.cc:
-flagfile (load flags from file) type: string default: ""
-fromenv (set flags from the environment [use 'export FLAGS_flag1=value'])
type: string default: ""
-tryfromenv (set flags from the environment if present) type: string
default: ""
-undefok (comma-separated list of flag names that it is okay to specify on
the command line even if the program does not define a flag with that
name. IMPORTANT: flags in this list that have arguments MUST use the
flag=value format) type: string default: ""
Flags from D:\Work\lib\gflags\gflags\src\gflags_completions.cc:
-tab_completion_columns (Number of columns to use in output for tab
completion) type: int32 default: 80
-tab_completion_word (If non-empty, HandleCommandLineCompletions() will
hijack the process and attempt to do bash-style command line flag
completion on this value.) type: string default: ""
Flags from D:\Work\lib\gflags\gflags\src\gflags_reporting.cc:
-help (show help on all flags [tip: all flags can have two dashes])
type: bool default: false currently: true
-helpfull (show help on all flags -- same as -help) type: bool
default: false
-helpmatch (show help on modules whose name contains the specified substr)
type: string default: ""
-helpon (show help on the modules named by this flag value) type: string
default: ""
-helppackage (show help on all modules in the main package) type: bool
default: false
-helpshort (show help on only the main module for this program) type: bool
default: false
-helpxml (produce an xml version of help) type: bool default: false
-version (show version and build info and exit) type: bool default: false
E:\CaffeDev\caffe-master\examples\help1>pause
请按任意键继续. . . Flags from ..\..\tools\convert_imageset.cpp:
-backend (The backend {lmdb, leveldb} for storing the result) type: string
default: "lmdb"
-check_size (When this option is on, check that all the datum have the same
size) type: bool default: false
-encode_type (Optional: What type should we encode the image as
('png','jpg',...).) type: string default: ""
-encoded (When this option is on, the encoded image will be save in datum)
type: bool default: false
-gray (When this option is on, treat images as grayscale ones) type: bool
default: false
-resize_height (Height images are resized to) type: int32 default: 0
-resize_width (Width images are resized to) type: int32 default: 0
-shuffle (Randomly shuffle the order of images and their labels) type: bool
default: falsebackend: 格式就不说了,后续我会研究研究官网对caffe的输入数据格式的转换及对应使用
check_size: 应该是检查是不是所有图像都是同样的大小
encode_type: 图片的格式
encoded: 咳咳,这个我也不知道,后续知道了再补充,有知道的同学,可以在评论区说一下哈
gray: 是否转换为灰度图,一定要注意,默认不是灰度图,也就是说就算你的图像是灰度图,它转换也是当做彩色图像转换,这样很容易导致你的测试数据与模型参数不匹配,只要记住,图像是灰度的,就把gray=1打开
resize_height和resize_width: 把图片切成你设置的大小
shuffle:随机打乱数据和对应标签,原因和机器学习里面一样
附录
顺带把mnist可视化和转换方法打包一下了,有兴趣可以下载看看,直接把mnist对应的四个文件:t10k-images-idx3-ubyte,t10k-labels-idx1-ubyte,train-images-idx3-ubyte,train-labels-idx1-ubyte放到与代码并列的目录即可,然后运行vis_mnist.m将可视化手写数字存成jpg格式。
链接:http://pan.baidu.com/s/1cpilB4 密码:jr5h















 3470
3470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











