







“夸父”现身,大模型赋能人形机器人
原创 科技产业微观察 科技产业微观察 2024年06月23日 09:56 北京
6月21日下午,华为开发者大会2024(HDC 2024)举行。会上除发布原生鸿蒙操作系统与盘古大模型5.0之外,还有令人颇感意外的人形机器人“夸父”登场亮相。同时,这也让人们领略到了大模型+人形机器人所带来的革命性创新。
“夸父+盘古”带来的新变革
据了解,“夸父”是乐聚机器人最新一代人形机器人,其搭载了华为盘古具身智能大模型。乐聚公司是一家老牌人形机器人公司,创立于2016年3月,总部位于深圳,同时在哈尔滨及杭州设有研发及生产基地,核心成员来自哈工大博士团队。

夸父机器人是该公司最新一代的人形机器人,发布于2023年12月,是国内首款可跳跃、可适应多地形行走的开源鸿蒙人形机器人,重约45kg,全身26个自由度,行走速度最高可达4.6km/h,可快速连续跳跃,跳跃高度超20cm。在HDC 2024大会上,“夸父”机器人展示了识别物品/问答互动/击掌/递水等一系列能力,智能化运控能力突出。
2024年3月,华为云与乐聚机器人签署战略合作协议,建设“人形机器人+”具身智能开放生态平台。盘古大模型旨在提升机器人泛化操作能力。据华为云CEO张平安介绍,盘古大模型赋能人形机器人具备多模态 (文本/图像/视频)能力,可让机器人完成10+步数的复杂任务规划,并实现多场景泛化能力。除了人形,盘古大模型还可以赋能工业/服务机器人,帮助人类从事危险和繁重的工作。
特斯拉与英伟达早已投入
随着新技术、新产品、新业态的快速发展,人形机器人正在成为全球科技创新的新热点,而大模型在人形机器人的渗透与赋能则可视为产业发展的一道分水岭。大模型让人形机器人拥有感知、思考、决策等能力的预期不再遥不可及。
目前有越来越多的科技巨头开始涌入人形机器人领域,以大模型赋能人形机器人。近日,特斯拉在美国德克萨斯州奥斯汀举行2024年度股东大会。会上,马斯克充满信心地表示,到明年特斯拉将拥有1000个,甚至可能达到数千个Optimus机器人投入运行。马斯克在对比自动驾驶和人形机器人市场潜力后乐观地认为,自动驾驶产业的市场规模可能达到5万亿-7万亿美元,但人形机器人的市场潜力可能更大,高达25万亿美元。

特斯拉已经投入人形机器人领域发展多年。在2021年首届AI DAY上,特斯拉首次公布Optimus的概念图。2022年Optimus原型机实现首秀。2023年特斯拉开始使用自研的超算 Dojo为Optimus提供算力支持,加快训练速度。而特斯拉最新发布的视频中,Optimus已经具备走进工厂的工作能力。视频中,Optimus可以实现在电池流水线上进行搬运、分拣等动作,展示了在工业场景下操作熟练的运控细节和精细化工作能力。
英伟达则侧重在产业生态上进行布局。资料显示,早在十年前,即2014年,英伟达就已开始介入机器人领域。当时,黄仁勋曾亲手将一台NVIDIA DGX AI超级计算机交付给OpenAI。2023年英伟达在COMPUTEX上发布全新Jetson AGX Orin工业级计算平台。该平台可以提供更强的计算能力,意味着在农业、建筑、能源、航空抗体、卫星等极端环境中打造更强劲的机器人有了可能。2024年,英伟达围绕具身智能加速布局,宣布成立通用具身智能体研究实验室GEAR。
大模型赋能人形机器人
以往受到算法模型的局限,人形机器人很难具备“泛化”能力,只能针对特定领域进行训练,满足某一特定用途,这极大限制了人形机器人的应用场景。而AI大模型的渗透被视为人形机器人产业发展的一道分水岭,具备强大泛化能力的大模型出现,使人形机器人有了大幅跃升的现实基础,它让人形机器人拥有感知、思考、决策等方面的能力。
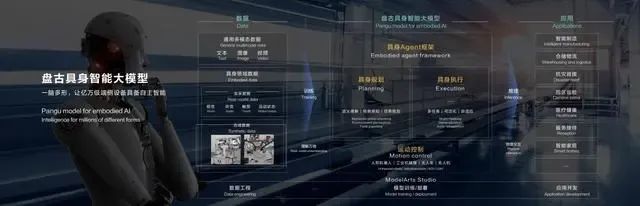
国际上很早就开始了这方面的探索。去年4月,AI公司Levatas便与波士顿动力合作,将ChatGPT以及谷歌公司的语音合成技术接入Spot机器狗,使其成功实现与人类的交互。多模态大模型则能让人形机器人能够通过“视觉”与外部环境交互。去年7月,谷歌DeepMind推出RT-2,这是全球首个VLA模型,可控制机器人的视觉-语言-动作。通过将VLA预训练与机器人数据相结合,能够端到端输出机器人的控制指令。通过测试,RT-2 与之前的模型相比,在符号理解、推理和人类识别 三个方面具有更高的任务成功率以及更强的泛化和涌现能力。可以说,大模型赋予了人形机器人一个通识大脑,能够顺畅地和外部对话,还可以增加任务理解、拆分和逻辑推理等方面的决策能力。
数据与芯片算力仍是瓶颈
值得注意的是,机器人大模型距离实际应用还面临不少问题。首先面临的就是可用于机器人训练的高质量数据非常匮乏。由于机器人需要通过多种传感器感知环境状态,然后执行实际动作,完成任务,因此训练用于机器人的大模型需要用到大量机器人在真实世界中与环境进行交互的数据集。对于ChatGPT来说,公开的互联网数据十分充足,有大量的公域数据可供爬取。但现实中的人形机器人保有量却太少,可用于收集训练数据的机器人就更加稀少。如何解决机器人算法的训练需要大量数据是当前行业面临的一大挑战。
另一个瓶颈是芯片算力问题。机器人大模型对机器人行动控制的周期仍太长,无法做到实时响应。谷歌RT-2的演示视频需要2倍速播放才能实现比较流畅的机器人动作,而斯坦福大学李飞飞团队提出了智能系统 VoxPoser更是需要8倍速才能有流畅的动作表现。实时性的提升依赖于算力,对于面对高复杂性环境的人形机器人尤其重要。

近日,英伟达宣布开源旗下Nemotron-4 340B(3400亿参数)模型,开发人员可使用该模型生成合成数据,用于大模型的训练。有观点认为,英伟达此举的目标或许就是指向人形机器人的数据集市场。由于现实数据过于稀少,因此合成数据已被视为解决机器人领域高质量训练数据不足、采集效率低下问题的重要途径。机器人智能体可以通过模仿学习在生成的数据集上进行训练。英伟达Nemotron-4 340B使用了,可以为开发人员提供一个可扩展的生成合成数据模型。此举或将进一步巩固其在人形机器人训练市场的核心地位。

















 2760
2760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









