







RTL可拓展设计:VerilogHDL实现2^N位宽无符号整数乘法器
参考资料
应用场景与设计目标
一般来说,FPGA中会带有一定数量的硬件乘法器。但是,很多情况下这些乘法器的数量并不足以应对大规模卷积的场景,很多场景也并不需要有如此高速的乘法器。因此,需要利用LUT资源来对不足的乘法器资源进行补充。
本设计着眼于这个应用场景,实现一种2N(N大于等于1)位宽乘法器,用于执行无符号整数的乘法。
使用方法
文件构成
multiplier/unsigned/Makefile:用于测试的make脚本文件multiplier/unsigned/multiplier_unsigned_b2.v:2位宽输入、4位宽输出的乘法器multiplier/unsigned/multiplier_unsigned.v:2N(N大于等于1)位宽输入、2N+1(N大于等于1)位宽输出的乘法器multiplier/unsigned/testbench.sv:测试激励文件multiplier/td:安路测试工程(仅用于资源使用估计,不可直接下载运行)
主模块信号及其参数配置
主模块所在文件及其接口定义:
// multiplier/unsigned/multiplier_unsigned.v
module multiplier_unsigned #(
parameter BITWIDTH_INPUT = 4
) (
input clk,
input rstn,
input [ BITWIDTH_INPUT - 1:0] a,
input [ BITWIDTH_INPUT - 1:0] b,
output [(BITWIDTH_INPUT * 2) - 1:0] q
);
| 参数 | 备注 |
|---|---|
BITWIDTH_INPUT | 定义输入位宽为2N |
| 方向 | 位宽 | 信号 | 备注 |
|---|---|---|---|
| 输入 | 1 | clk | 系统时钟信号 |
| 输入 | 1 | rstn | 同步复位信号,低有效 |
| 输入 | BITWIDTH_INPUT | a | 乘数 |
| 输入 | BITWIDTH_INPUT | b | 乘数 |
| 输出 | BITWIDTH_INPUT * 2 | p | 结果数 |
信号时序
2位宽乘法器的时序图如下:
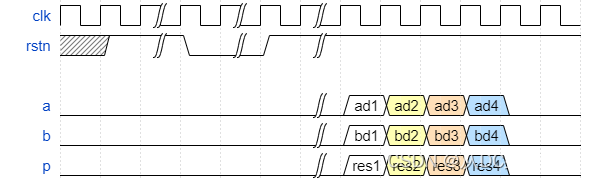
需要注意的是,复位信号是同步触发的,这有利于系统时序,降低毛刺出现的概率。
如图可见,p与a、b在同一个时钟周期之中,这样可以认为延迟是0个时钟周期。如果位宽为4,则延迟为2个时钟周期。如果位宽大于4,则延迟与位宽的关系为:
D e l a y P e r i o d = l o g 2 ( B I T W I D T H _ I N P U T ) ∗ 2 − 1 DelayPeriod=log_2(BITWIDTH\_INPUT)*2-1 DelayPeriod=log2(BITWIDTH_INPUT)∗2−1
如果想要确认这个结果,可以在安装Iverilog和GTKWave之后,在multiplier/文件夹内运行make进行仿真。
设计原理
2位宽乘法器
2位宽乘法器利用查表的方法实现。两个2位宽输入组成一个4位宽地址,一共是24=16项:
// multiplier/unsigned/multiplier_unsigned_b2.v
module multiplier_unsigned_b2 (
input clk,
input rstn,
input [1:0] a,
input [1:0] b,
output reg [3:0] q
);
wire [4:0] res_rom[0:15];
assign res_rom[4'b0000] = 4'b0000;
assign res_rom[4'b0001] = 4'b0000;
assign res_rom[4'b0010] = 4'b0000;
assign res_rom[4'b0011] = 4'b0000;
assign res_rom[4'b0100] = 4'b0000;
assign res_rom[4'b0101] = 4'b0001;
assign res_rom[4'b0110] = 4'b0010;
assign res_rom[4'b0111] = 4'b0011;
assign res_rom[4'b1000] = 4'b0000;
assign res_rom[4'b1001] = 4'b0010;
assign res_rom[4'b1010] = 4'b0100;
assign res_rom[4'b1011] = 4'b0110;
assign res_rom[4'b1100] = 4'b0000;
assign res_rom[4'b1101] = 4'b0011;
assign res_rom[4'b1110] = 4'b0110;
assign res_rom[4'b1111] = 4'b1001;
always @(posedge clk) begin
if (!rstn) begin
q <= 4'b0;
end else begin
q <= res_rom[{a, b}];
end
end
endmodule
这个实现也没什么好讲的,纯纯的穷举。
2N位宽乘法器实现
先上代码:
module multiplier_unsigned #(
parameter BITWIDTH_INPUT = 4
) (
input clk,
input rstn,
input [ BITWIDTH_INPUT - 1:0] a,
input [ BITWIDTH_INPUT - 1:0] b,
output [(BITWIDTH_INPUT * 2) - 1:0] q
);
generate
if (BITWIDTH_INPUT > 2) begin : g_normal_mul
reg [(BITWIDTH_INPUT * 2) - 1:0] q_buf;
assign q = q_buf;
wire [(BITWIDTH_INPUT / 2) - 1:0] a_h;
wire [(BITWIDTH_INPUT / 2) - 1:0] a_l;
wire [(BITWIDTH_INPUT / 2) - 1:0] b_h;
wire [(BITWIDTH_INPUT / 2) - 1:0] b_l;
assign a_h = a[BITWIDTH_INPUT-1:(BITWIDTH_INPUT/2)];
assign a_l = a[(BITWIDTH_INPUT/2)-1:0];
assign b_h = b[BITWIDTH_INPUT-1:(BITWIDTH_INPUT/2)];
assign b_l = b[(BITWIDTH_INPUT/2)-1:0];
// H*H
wire [BITWIDTH_INPUT-1:0] q_bl_hh;
multiplier_unsigned #(
.BITWIDTH_INPUT(BITWIDTH_INPUT / 2)
) multiplier_unsigned_hh_inst (
.clk (clk),
.rstn(rstn),
.a(a_h),
.b(b_h),
.q(q_bl_hh)
);
// H*L
wire [BITWIDTH_INPUT-1:0] q_bl_hl;
multiplier_unsigned #(
.BITWIDTH_INPUT(BITWIDTH_INPUT / 2)
) multiplier_unsigned_hl_inst (
.clk (clk),
.rstn(rstn),
.a(a_h),
.b(b_l),
.q(q_bl_hl)
);
// L*H
wire [BITWIDTH_INPUT-1:0] q_bl_lh;
multiplier_unsigned #(
.BITWIDTH_INPUT(BITWIDTH_INPUT / 2)
) multiplier_unsigned_lh_inst (
.clk (clk),
.rstn(rstn),
.a(a_l),
.b(b_h),
.q(q_bl_lh)
);
// L*L
wire [BITWIDTH_INPUT-1:0] q_bl_ll;
multiplier_unsigned #(
.BITWIDTH_INPUT(BITWIDTH_INPUT / 2)
) multiplier_unsigned_ll_inst (
.clk (clk),
.rstn(rstn),
.a(a_l),
.b(b_l),
.q(q_bl_ll)
);
// Output buffer adder 0
reg [(BITWIDTH_INPUT * 2) - 1:0] q_buf_0;
always @(posedge clk) begin
if (!rstn) begin
q_buf_0 <= {(2 * BITWIDTH_INPUT) {1'b0}};
end else begin
q_buf_0 <= {q_bl_hh, {(BITWIDTH_INPUT) {1'b0}}} + {q_bl_hl, {(BITWIDTH_INPUT / 2) {1'b0}}};
end
end
// Output buffer adder 1
reg [(BITWIDTH_INPUT * 2) - 1:0] q_buf_1;
always @(posedge clk) begin
if (!rstn) begin
q_buf_1 <= {(2 * BITWIDTH_INPUT) {1'b0}};
end else begin
q_buf_1 <= {q_bl_lh, {(BITWIDTH_INPUT / 2) {1'b0}}} + q_bl_ll;
end
end
// Output adder
always @(posedge clk) begin
if (!rstn) begin
q_buf <= {(2 * BITWIDTH_INPUT) {1'b0}};
end else begin
q_buf <= q_buf_0 + q_buf_1;
end
end
end else begin : g_b2_mul
multiplier_unsigned_b2 multiplier_unsigned_b2_inst (
.clk (clk),
.rstn(rstn),
.a(a),
.b(b),
.q(q)
);
end
endgenerate
endmodule
这里的generate里面的if和for语句都是有标识名的,注意这些标识名。
首先是g_normal_mul。这个if负责判断位宽。如果位宽为2,则直接例化一个multiplier_unsigned_b2模块;如果位宽大于2,则另寻解决方法。
那究竟要怎么处理呢?这里先放上一个典型的位分解的乘法器实现:
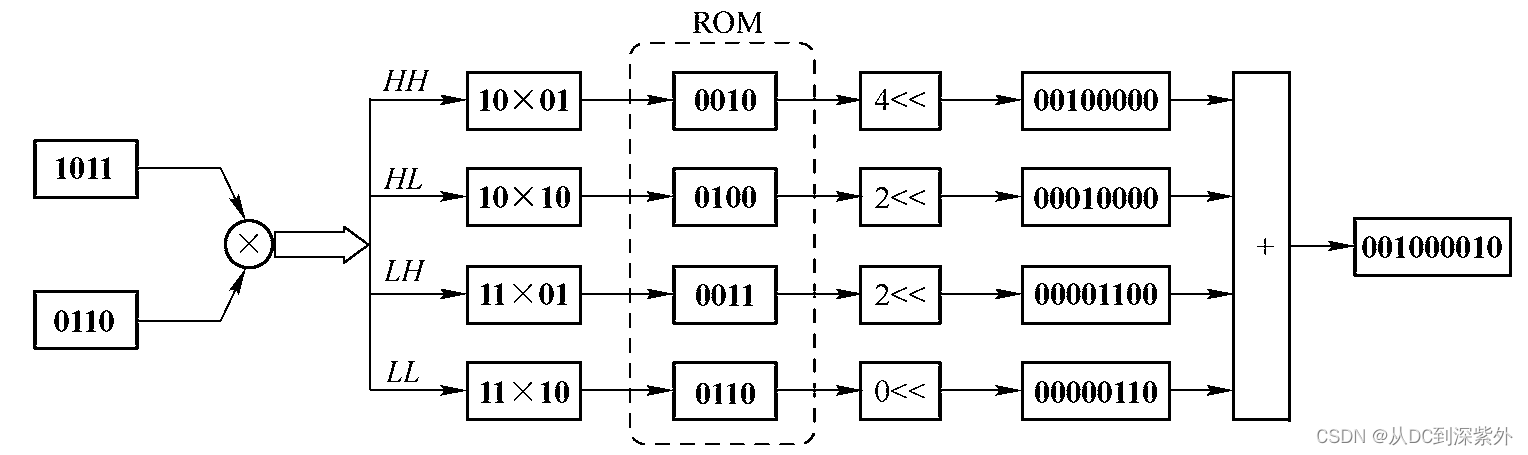
首先是这个出自《数字信号处理(高亚军)》图3.32的图。这个其实就是相当于做分解乘法:比如这幅图,乘数a是1011,转化成四进制就是23;乘数b是0110,那就是12。也就是说,这个数的乘法可以分解成:
23 ∗ 12 = 20 ∗ 12 + 3 ∗ 12 = 20 ∗ 10 + 20 ∗ 2 + 3 ∗ 10 + 3 ∗ 2 23*12=20*12+3*12=20*10+20*2+3*10+3*2 23∗12=20∗12+3∗12=20∗10+20∗2+3∗10+3∗2
其中,因为一位四进制可以一一对应2位二进制数,也就是说:
20
∗
10
=
2
∗
1
<
<
4
20*10=2*1<<4
20∗10=2∗1<<4
20
∗
3
=
2
∗
3
<
<
2
20*3=2*3<<2
20∗3=2∗3<<2
3
∗
10
=
3
∗
1
<
<
2
3*10=3*1<<2
3∗10=3∗1<<2
3
∗
2
=
3
∗
2
<
<
0
3*2=3*2<<0
3∗2=3∗2<<0
好了,那就已经证明了位分解乘法了。
为了实现这个东西,其实就是构造4个乘法器就完事了,分别实现a高位×b高位、a高位×b低位、a低位×b高位、a低位×b低位;然后在实现加法器把这些东西加起来就行了。因为同位宽的乘法器输出与输入的延迟时钟周期数相同,因此也不用考虑时钟周期对齐的问题。这就是全流水线架构带给我们的自信。
但是还是要考虑一下加法器的实现的,4个数直接相加会极大拉慢时钟,对于最终的时序约束不利。因此这里采用先在一个时钟内分别相加其中两个乘法器,下一个时钟周期再完成上一个时钟周期两个结果的相加并输出结果的方式。因此,在位宽8及以上时,每增加一倍位宽。将增加2个时钟周期的延迟。
补充设计:定点数乘法器
注意,这个模块的整数部分和小数部分的位宽都可以单独设置值,但是要求两者的位宽总和是2N。

















 6685
6685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









