







ImageNet Classification with Deep Convolutional Neural Networks
Advances in Neural Information Processing Systems. 2012
http://code.google.com/p/cuda-convnet/
AlexNet 在 ILSVRC-2012 一举成名,成为深度学习兴起的标志。后面的 VGG、GoogleNet等均在此基础之上改进的。所以这里来看看这篇文章,后面再深入其 python 代码。
2 The Dataset
公共测试数据库让大家有一个共同的测试基准,这样可以对不同算法的性能进行比较,孰优孰劣就一目了然了。在深度学习中数据库最有名气的当然是 ImageNet ,李飞飞等人建立的(最近加入了 Google了)。
这里大致介绍一下 ImageNet,该数据库包含 1千5 百万张标记的高清图像,大约 22000个类。这些图像从网络收集的,人工标记类别。 在这个数据库基础上 有了一个 ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) 用于大家算法比武测试用的。大约 1.2百万张训练图像, 5万张验证图像,15万张测试图像。 ILSVRC-2010 的测试数据的真值标签是可以得到的,所以本文的大多数实验在该数据集上进行。结果主要以 top-1 and top-5 来衡量。
ImageNet 中很有不同尺寸的图像,我们的系统输入需要固定尺寸的图像,所以我们将图像下采样之256*256。对于一个矩形图像,我们首先将短的一边缩放至256,然后在此图像上中间位置裁出 256*256 大小的图像。除了在训练数据集上对每个像素值减去图像的均值外,我们不做任何的预处理。
3 The Architecture
在介绍整个网络之前,我们首先看看这个网络的几个特别之处:
3.1 ReLU Nonlinearity
以前大家常用的激活函数是 tan(x) 函数 或 sigmoid函数。这里我们采用 ReLU 激活函数(Rectified Linear Units (ReLUs))。主要是其训练速度快。ReLU 激活函数 公式 f(x)= max(0,x)
这里稍稍说一下激活函数,为什么要用activation function 了?如果使用线性的激活函数,那么激活函数其实是可以不需要的,因为前面的权值矩阵 W 是线性,两个线性表示完全可以由一个线性关系来表示。所以关键是引入非线性激活函数,非线性激活函数的引入主要是提取特征中的非线性关系,提高网络对特征的表达能力,这个是线性函数无法表达的。 现实中还是有很多非线性的问题需要来表达和解决的。同样,图像中也有非线性的特征需要提取。
再说说 ReLU 为什么好?
从SGD训练的角度分析,sigmoid or tanh 都会面临 gradient vanshing 问题,这是由于这sigmoid函数的偏导只有在-4到+4之间有比较大的值,再大或者小则梯度接近0。vanishing gradient在网络层数多的时候尤其明显,是加深网络结构的主要障碍之一。相反,Relu的gradient大多数情况下是常数,有助于解决深层网络的收敛问题。Relu的另一个优势是在生物上的合理性,它是单边的,相比sigmoid和tanh,更符合生物神经元的特征。而提出sigmoid和tanh,主要是因为它们全程可导。还有表达区间问题,sigmoid和tanh区间是0到1,或着-1到1,在表达上,尤其是输出层的表达上有优势。
Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
ReLU更容易学习优化。因为其分段线性性质,导致其前传,后传,求导都是分段线性。
3.2 Training on Multiple GPUs
这里我们采用两块 GTX 580 GPU进行训练,将网络并行化以加快训练速度。
3.3 Local Response Normalization
这里是对某些卷积层使用 ReLU 之后,我们对激活函数的输出做了一个局部归一化。这种归一化可以提高精度。 Response normalization reduces our top-1 and top-5 error rates by 1.4% and 1.2%, respectively.
归一化公式:
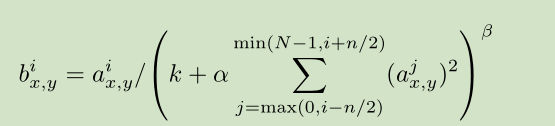
3.4 Overlapping Pooling
我们发现重叠池化可以提高系统精度,对防止过拟合有一点帮助。This scheme reduces the top-1 and top-5 error rates by 0.4% and 0.3%, respectively
3.5 Overall Architecture
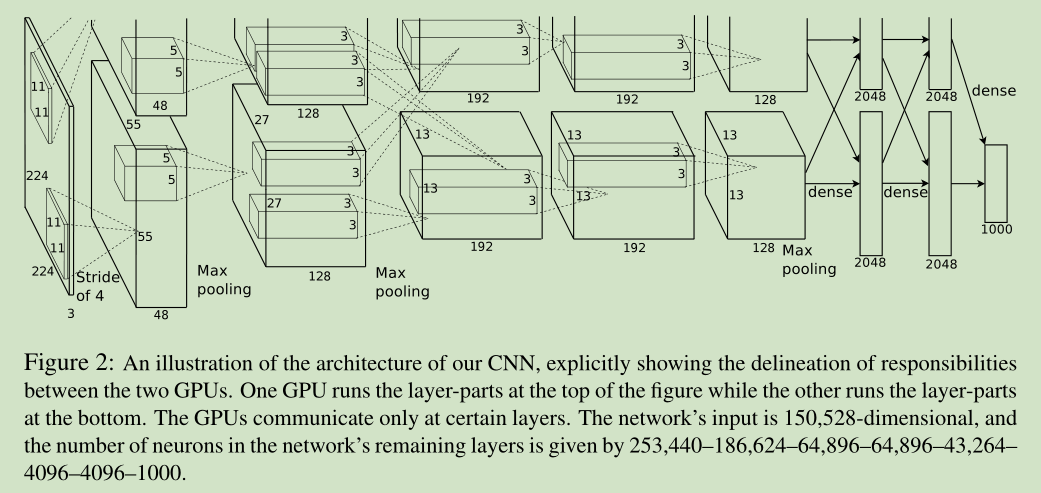

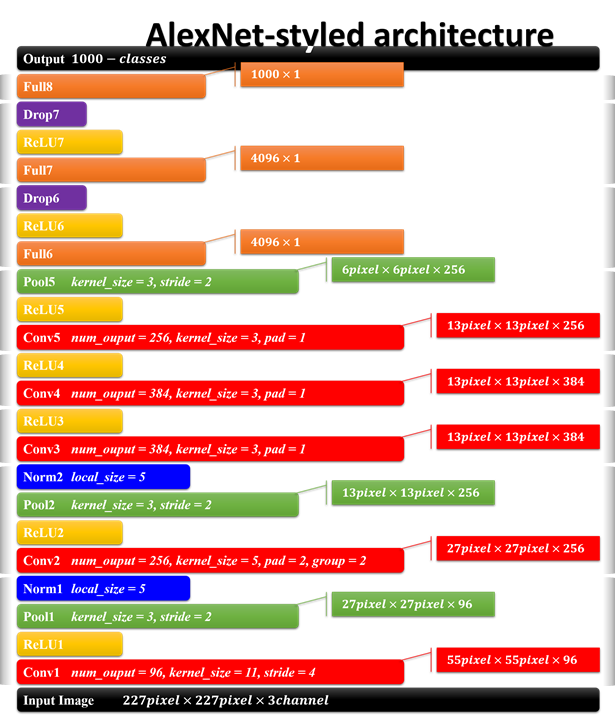
整个网络包括5个卷积层,3个全链接层。最后一个全链接层的输出作为 1000类 softmax 的输入,对应1000个类别。这个网络最大化 多项逻辑回归目标函数,其等同于最大化 在预测分部下 对训练样本类别做出正确预测的 log概率 均值。
4 Reducing Overfitting
该系统一共有 6千万个参数,训练样本不足以训练这样参数,所以为了防止过拟合,我们采取以下措施:
4.1 Data Augmentation
这里对原来的样本做些简单的变换得到新的样本。这里我们用了两种方法。This scheme reduces the top-1 error rate by over 1%.
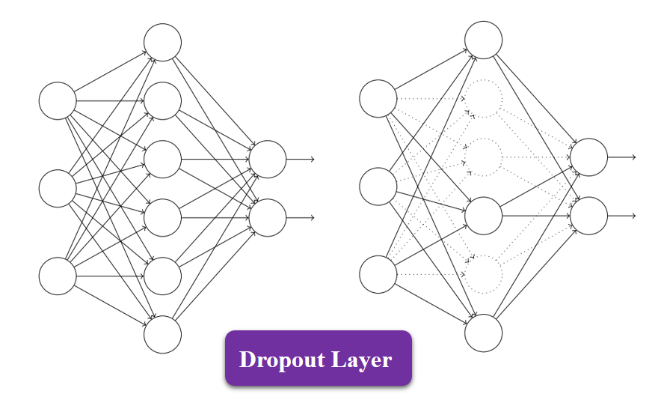
4.2 Dropout
三个臭皮匠赛个诸葛亮,显然如果我们训练多个不同模型,将这些模型结合起来可以降低 test errors。但是主要问题是训练时间太长。这里我们采用了 dropout, 就是随机的冻结一些神经元,不让这些冻结神经元参与网络的前向计算和后向传播。这样做可以提高网络的泛化能力,减轻系统过拟合。
5 Details of learning
这里主要介绍的是学习的一些细节,参数设置等。
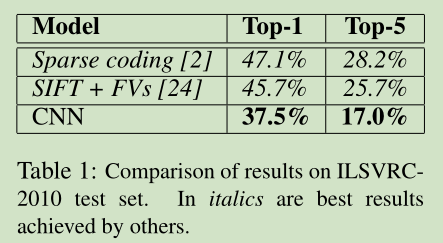
6 Results















 536
536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









