







Caffe 中的卷积中的效果不是很好,经常被人所诟病。首先来看看作者本人是怎么回答这个问题的。
https://github.com/Yangqing/caffe/wiki/Convolution-in-Caffe:-a-memo
it is a graduate-student level design choice when I was writing the Caffe framework in just 2 months’ budget with a looming thesis deadline.
作者当时只有2个月时间来写 Caffe 框架,马上要博士毕业答辩。所以没有对卷积进行深入优化,找了一个投机取巧的实现方法,将卷积变为矩阵乘法,矩阵运算有现成的优化库可以用。
这里来看看 Caffe 中是怎么实现卷积的。
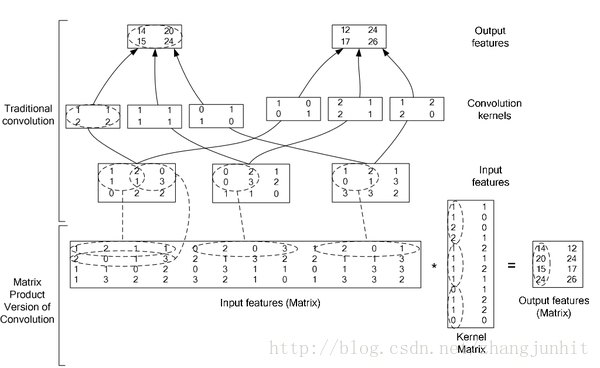
Caffe中的卷积计算是将卷积核矩阵和输入图像矩阵变换为两个大的矩阵A与B,然后A与B进行矩阵相乘得到结果C(利用GPU进行矩阵相乘的高效性或CPU对应的一些库 MKL, ATLAS, OpenBLAS).
https://www.zhihu.com/question/28385679
http://blog.csdn.net/xiaoyezi_1834/article/details/50786363

卷积网络性能对比:
https://github.com/soumith/convnet-benchmarks
从这个对比中可以看出 Caffe 的卷积效率不高。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









