







R-FCN: Object Detection via Region-based Fully Convolutional Networks
Code: https://github.com/daijifeng001/r-fcn
https://www.arxiv.org/abs/1605.06409
本文针对目标检测问题,对候选区域进行分块处理,以此来解决分类和检测之间的一个矛盾:分类网络具有一定的平移不变性,而目标检测需要对位置保持敏感性。a dilemma between translation-invariance in image classification and translation-variance in object detection。
目标分块处理,一个很直接的结果就是对目标局部遮挡效果比较好。
本文没有探讨解决目标尺度问题。
1 Introduction
R-CNN 目标检测系列将目标检测问题分为两个步骤:卷积特征提取+候选区域分类,这两个步骤通过 RoI 池化层连接起来。卷积特征提取独立于RoI,RoI后面的计算不能共享计算。造成这种情况是由于历史原因:早期的网络模型如 AlexNet and VGG Nets 有两个子网络:卷积网络以空间池化层结束,全链接层。这个空间池化层就演变为后来的 RoI 池化层。
最近提出的分类网络如 Residual Nets (ResNets) [ 9 ] and GoogLeNets [ 24 , 26 ] 都是全卷积网络,很自然的想法就是对检测系统使用全卷积网络,不要RoI 池化层,这样可以共享计算。但是实验发现这样做的效果不好。ResNet paper
[ 9 ]又加入了 RoI 池化层,这样做提高了检测精度,但是增加了计算量,因为对每个候选区域的计算没有共享该计算。
去掉RoI 池化层为什么效果会不好了,这主要是因为类网络具有一定的平移不变性,而目标检测需要对位置保持敏感性。这里我们提出了一个简单的解决方法:对候选区域进行分块处理,这里使用了k×k = 3×3 , 这9个区域分别表示:上中下左中右。{ top-left, top-center,top-right, …, bottom-right}
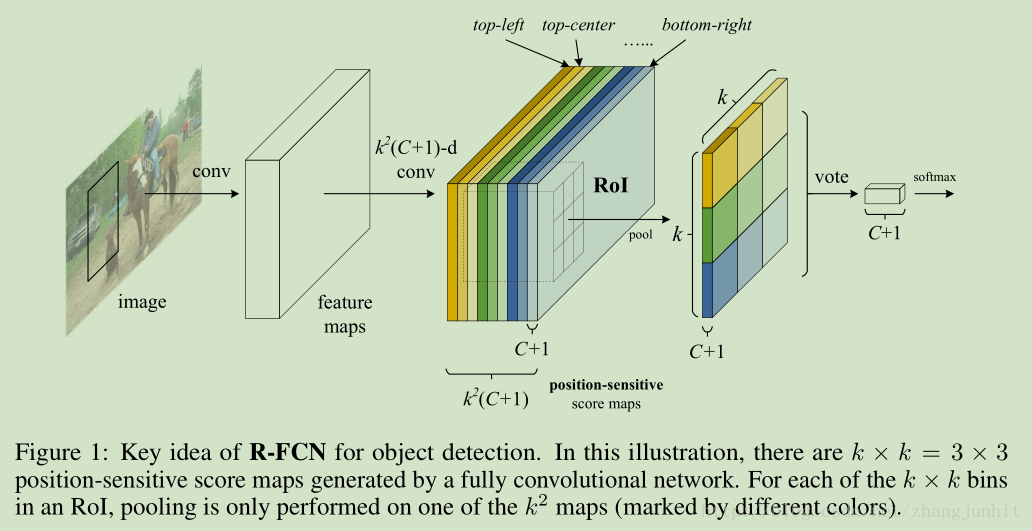
输入一幅图像,经过卷积网络提取整个图像的卷积特征,然后使用一个 k*k*(C+1)-d 卷积网络提取 k*k position-sensitive score maps,假设 k=3, 就是将一个候选区域分成 3*3=9个块,对应9个 position-sensitive score maps,上图显示第一个 position-sensitive score map是 top-left,就是目标左上块的卷积响应图,其他响应图以此类推。得到9个分块响应图之后,对于一个候选区域,我们可以从这9个分块响应图中得到完整的候选区域响应图。再对这个完整的候选区域响应图进行处理,得到分类结果。
行人分块检测示意图:

候选区域框发生偏移的效果:

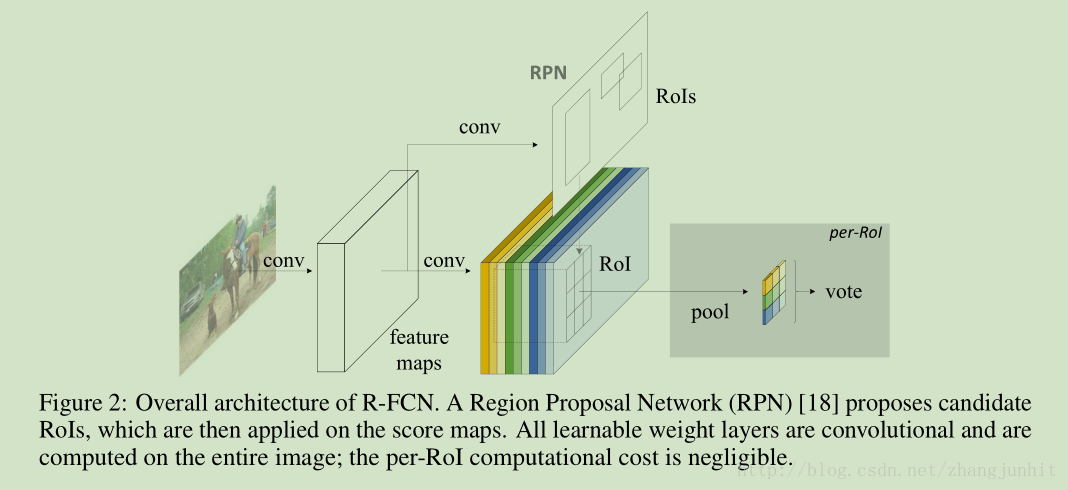
整个系统如下所示,使用 RPN提取候选区域,卷积计算都共享
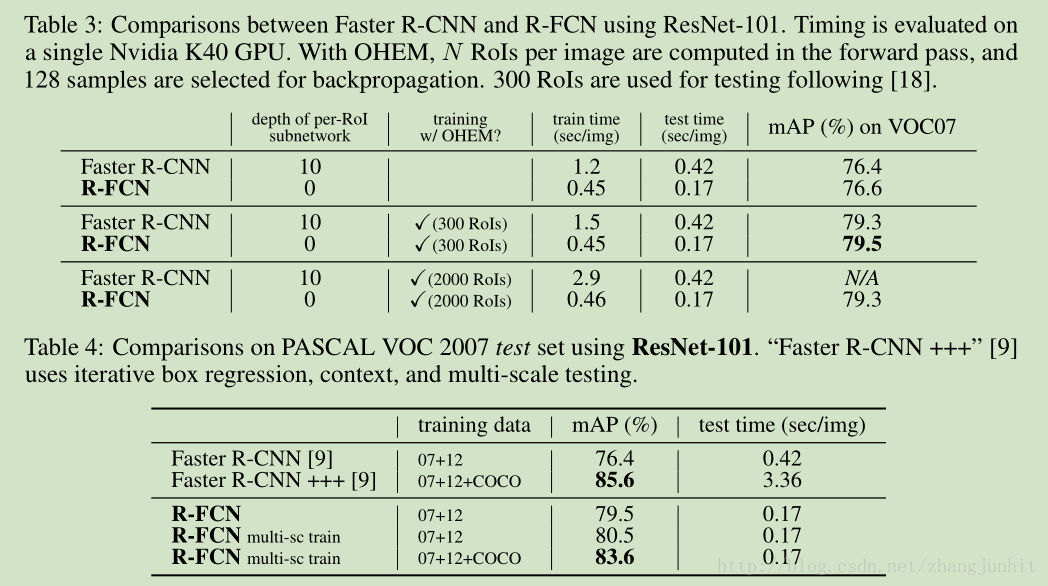
R-FCN 和 Faster R-CNN 对比:

检测效果图:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









