









Learning Object Interactions and Descriptions for Semantic Image Segmentation
CVPR2017
本文主要是从训练数据的角度来提升CNN分割性能的。由于像素级别标记的样本很少,制作样本成本高。这里直接根据关键词从网络上搜索相关图像,建立了一个数据库 IDW, 结合 VOC12上面的训练数据联合训练,对此设计了一个 IDW-CNN 模型,经过联合训练得到的模型用于分割,性能提升比较大。
首先来看看这个IDW数据库的建立
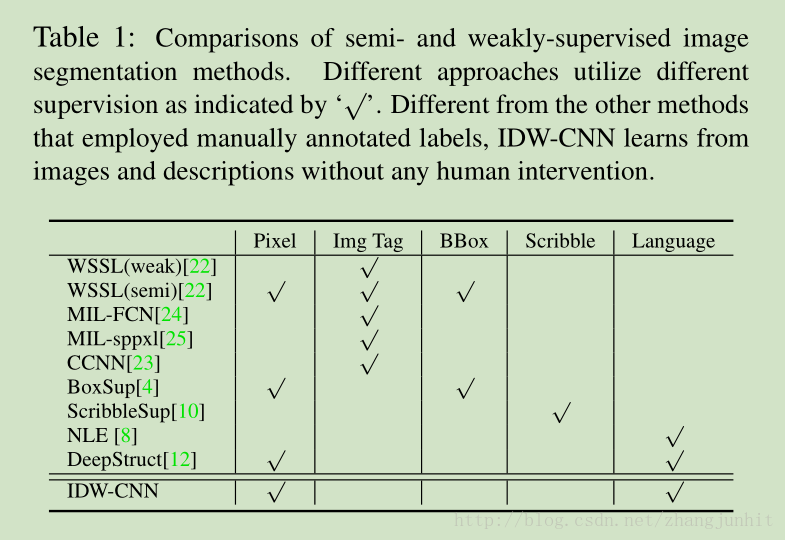
IDW 和 VOC12 两个样本的对比

看看大家都是怎么使用额外的信息
- Learning Image Descriptions
We construct an image description in the wild (IDW) dataset to improve the segmentation accuracy in VOC12
这里我们建立一个IDW数据库的图像描述用于提升 VOC12分割性能
In the first stage 根据 VOC12 里的20个类别,选择 21 prepositions and verbs 进行组合,得到 subject + verb/prep. + object’ leads to 20×21×20 = 8400
然后对其进行过滤,得到 hundreds of meaningful phrases,用这些语言描述去搜索图像,根据图像数量再过滤一下,把太少的过滤掉。最终得到 59 valid phrases
IDW has 41,421 images and descriptions
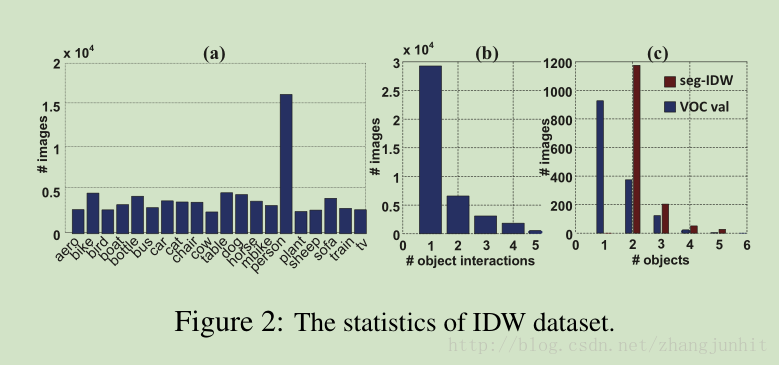
Image Description Representation
根据图像在网络上语言描述信息提取用于分割的关键信息
IDW-CNN 网络结构示意图
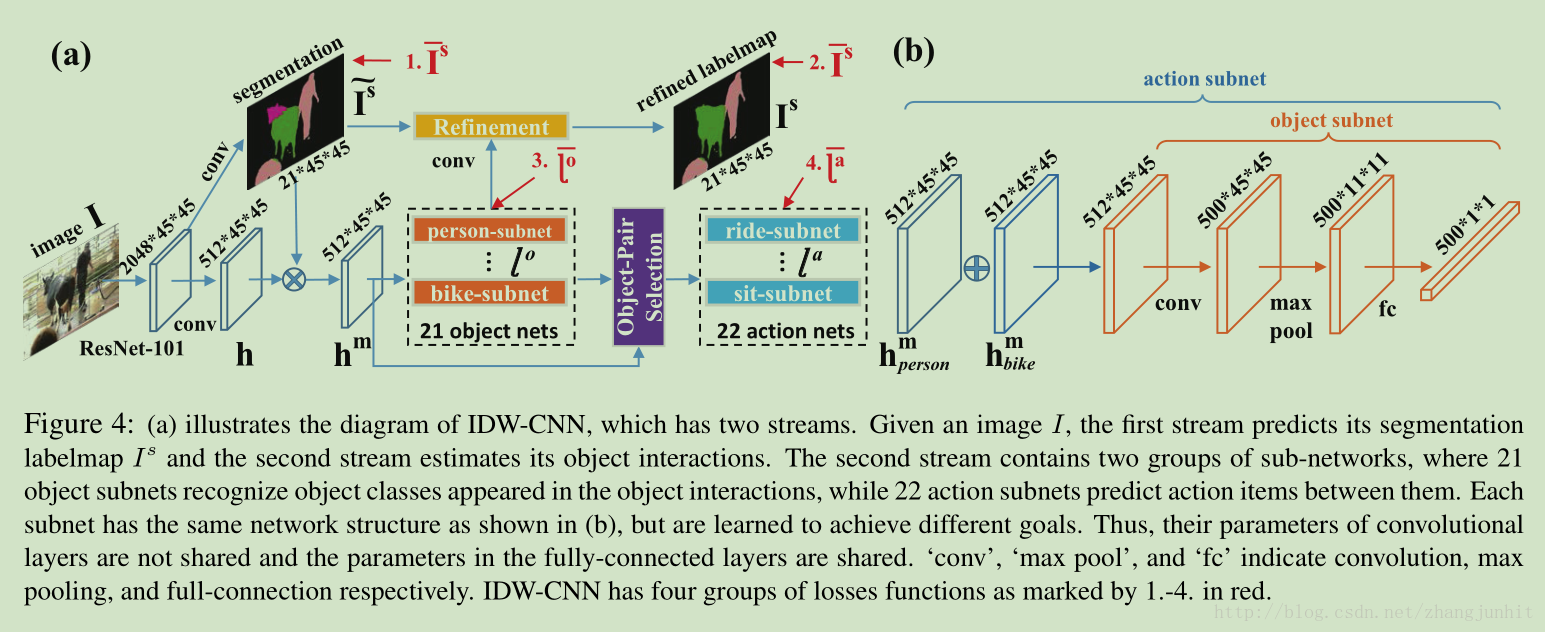
IDW-CNN 首先使用 ResNet-101 提取特征,然后有两个 streams: 第一个 stream 用于预测初步分割结果,第二个 stream 用于估计 物体之间的相关性 object interactions。这里面有 21 object nets 和 22 action nets
每个 subnet 结构如上图 (b)所示
两个类别物体特征可以直接相加
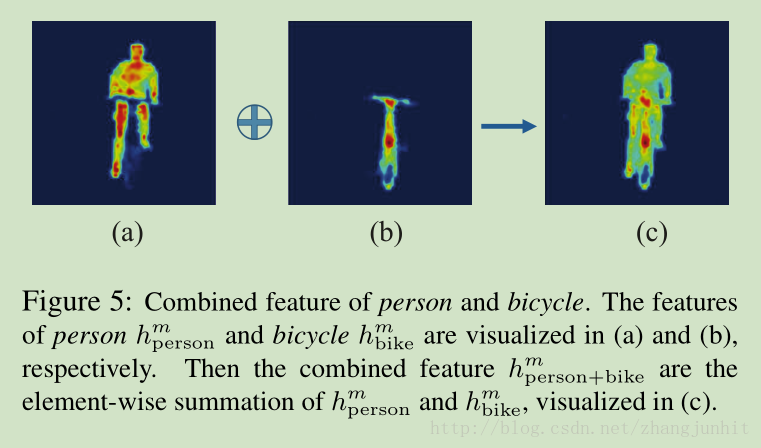

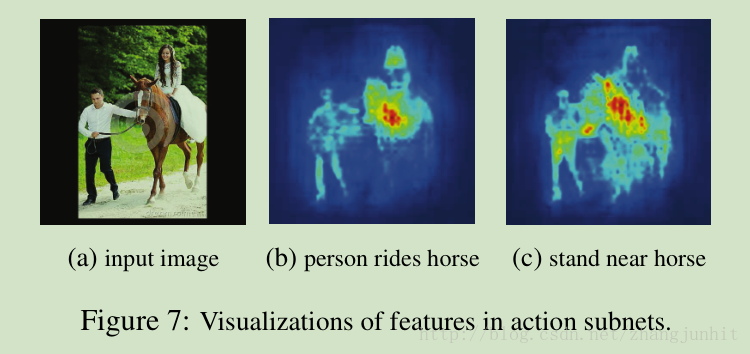
训练过程也是逐步进行的。
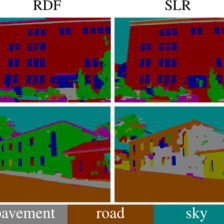
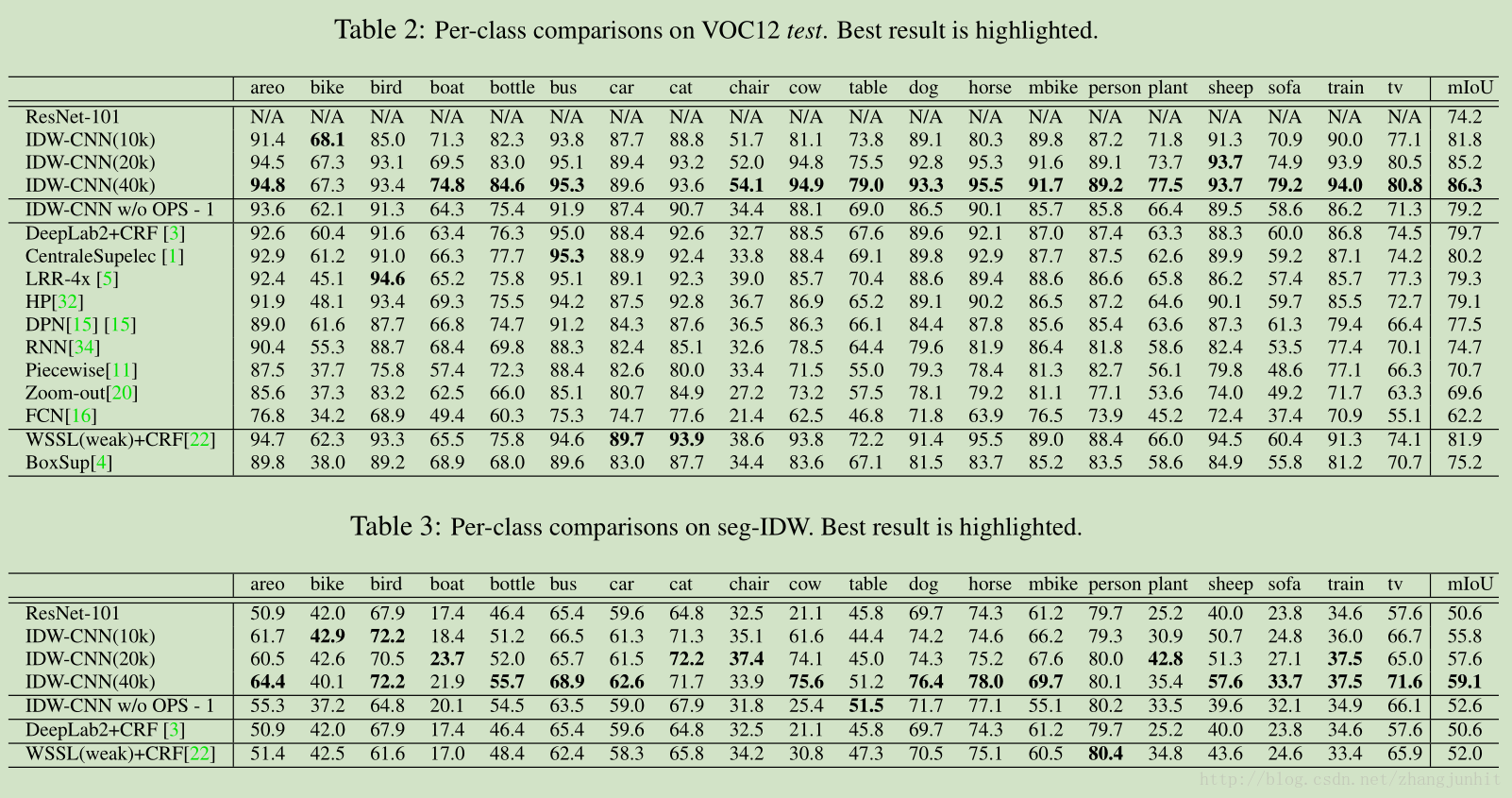
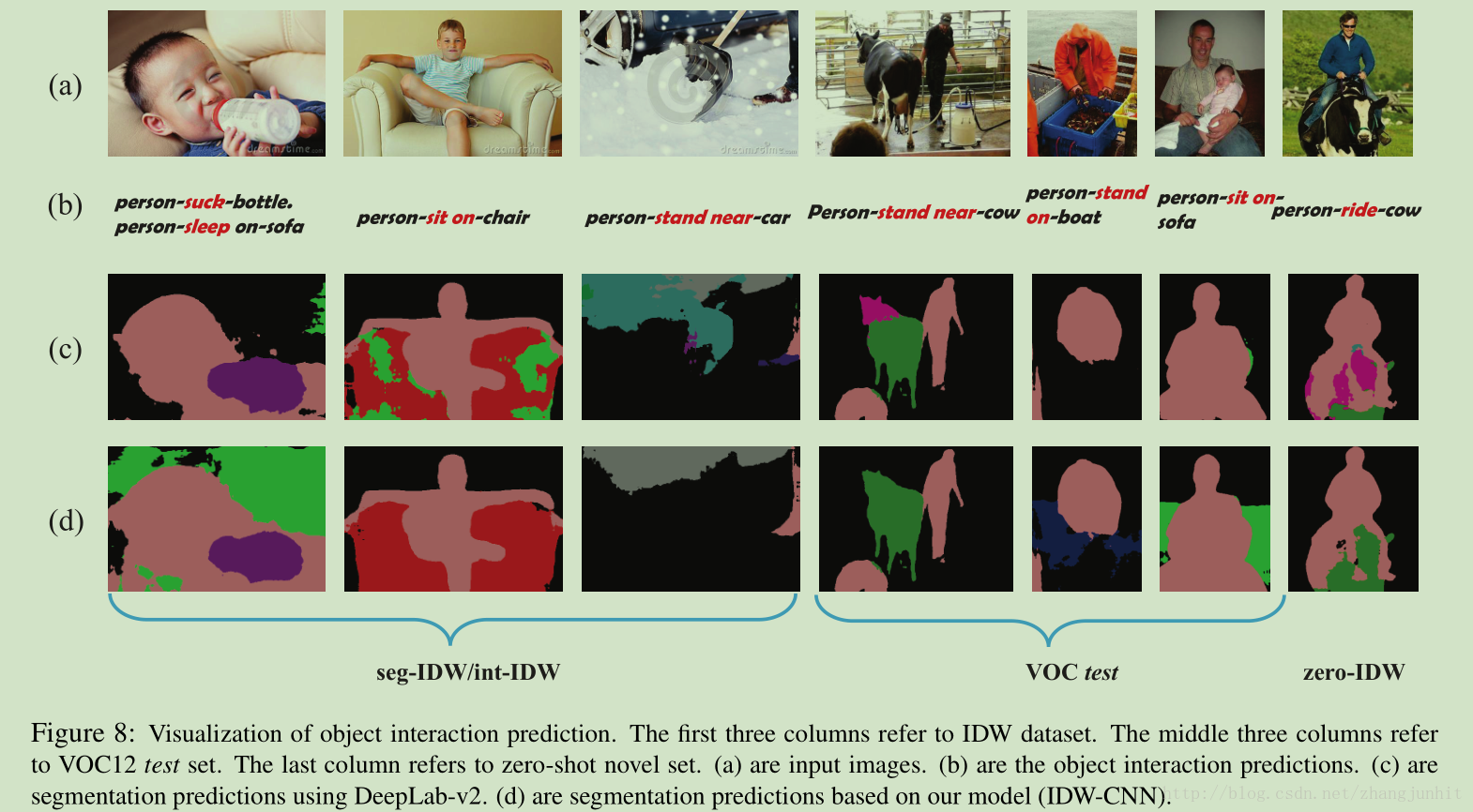
最后的分割结果:















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









