






特别说明:参考官方开源的DETR代码、TensorRT官方文档,如有侵权告知删,谢谢。
完整代码、测试脚本、测试图片、模型文件 点击下载
1、转tensorrt 输出全为 0 老问题回顾
在用 TensorRT 部署 DETR 检测模型时遇到:转tensorrt 输出全为 0 的问题。多次想放弃这个模型部署,花了很多时间查阅,最终解决方法用了两步:
第一步,修改onnx模型输出层Gather的参数;
第二步,转tensorrt 模型时不能量化,使用float32。
以上两步解决的详细内容参考DETR tensorRT 部署,感兴趣的可以看一下。
修改Gather的参数时只取最后一个输出头的结果,当时也很困惑,但没有多思考,先解决问题。后来就琢磨这个事情,既然只取最后一个头的结果,那么中间的头完全可以不要,这样就可以不使用Gather操作,且可以加快模型的推理速度。想法形成后,说干就干。最终想法得以验证,且不会在遇到“转tensorrt 输出全为 0 问题”。
转tensorrt 输出全为 0 的可能的本质原因:(1)Gather的参数中的取最后一个维度数据用的是自动推断的-1,可能是算子不支持,需改成指定的维度;(2)辅助头中数据很小超出了float16的表示范围,影响整体使用float16量化效果。
2、导出onnx去除辅助头,规避Gather算子
导出onnx去除辅助头需要修改两个地方:(1)修改TransformerDecoder,(2)修改DETR获取模型结果的代码规避Gather算子。
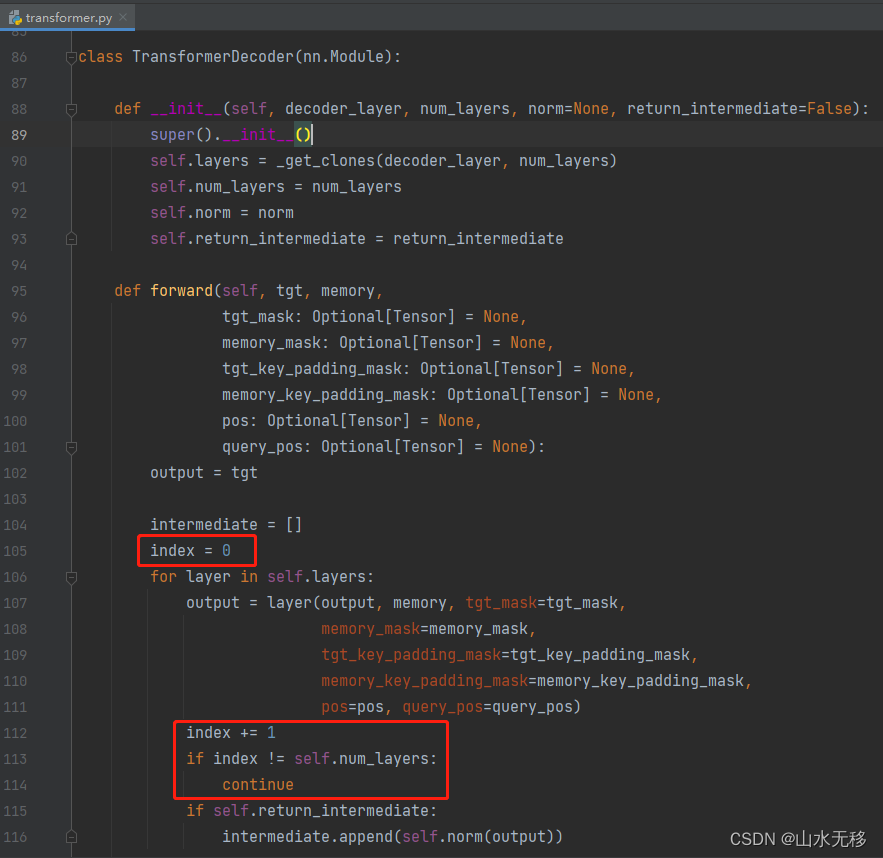
(1)修改TransformerDecoder
新增如下几行代码:
(2)修改DETR获取模型结果的代码规避Gather算子
修改如下: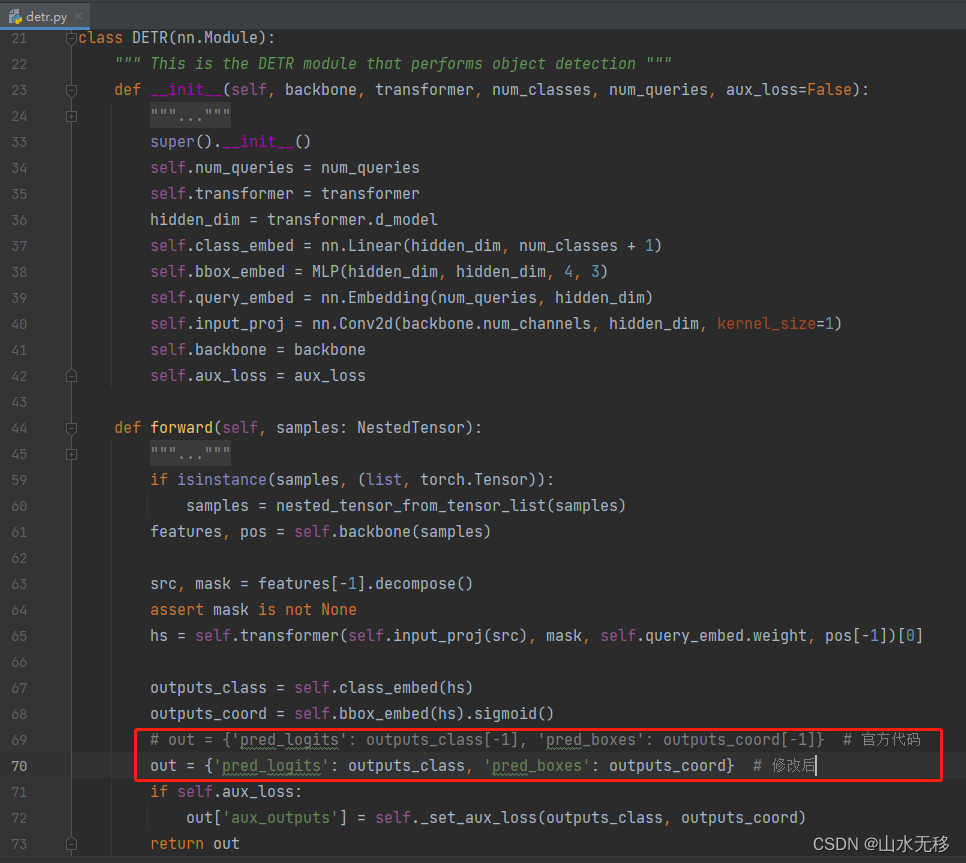
修改以上两个地方后导出onnx(导出onnx后用simplify处理以下),即为没有辅助头和Gather算子的结果,效果如下。
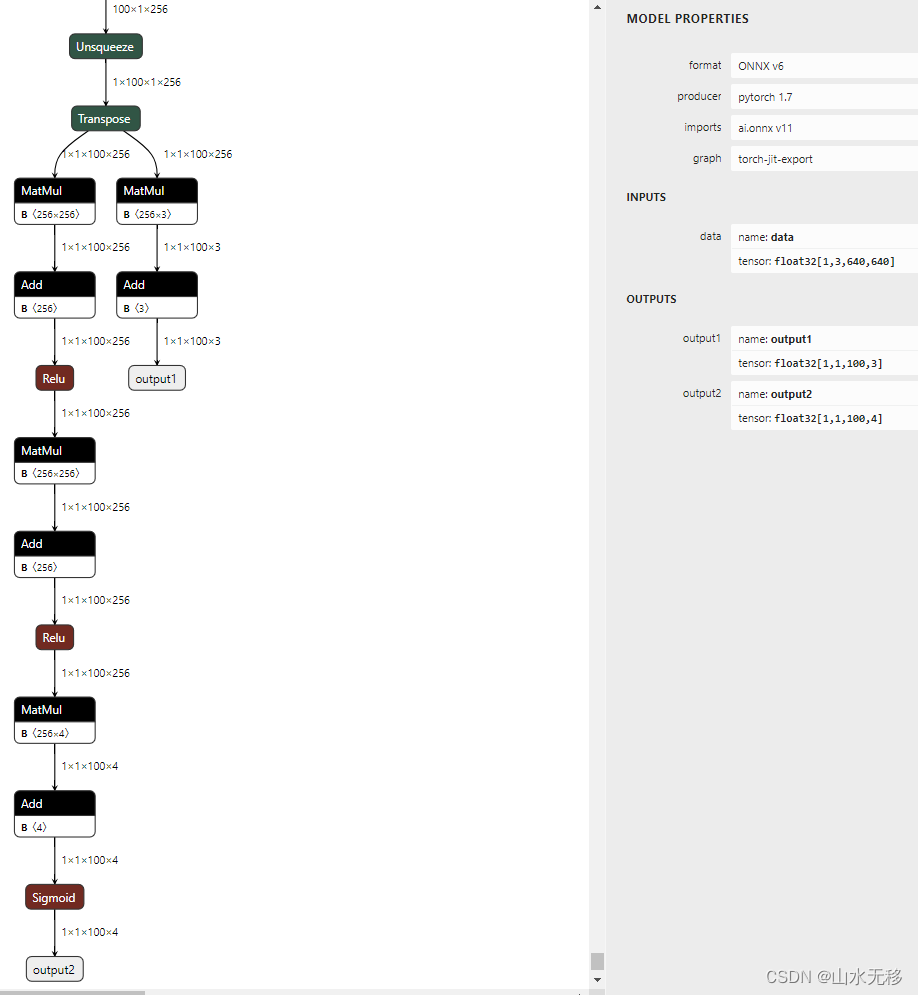
3 模型结果验证
导出onnx的结果是否和原始的是一致的这是最让人担忧的,以下进行验证对比:
(1)对比原始onnx检测结果和本示例导出的onnx检测结果;
(2)对比原始模型导出tensonRT的速度和本示例导出的导出tensonRT的速度;
(3)验证使用float16量化导出的tensorRT模型结果和速度。
(1)原始onnx检测结果和本示例导出的onnx检测结果
对比检测结果是一致的,用对比工具对比的结果也是一致的。
原始onnx的检测效果

本示例导出onnx检测结果

(2)对比原始模型导出tensonRT的速度和本示例导出的导出tensonRT的速度
导出tensorRT使用的是float32没有进行量化,对同一张图像推理1000次的平均时耗,还是有轻微的加速效果。
原始模型导出tensonRT模型推理时耗(fp32)

本示例导出的导出tensonRT模型推理时耗(fp32)

(3)验证使用float16量化导出的tensorRT模型结果和速度
基于本示例导出的onnx模型转tensorRT,对比使用float32和float16转出来的模型大小明显变小,推理速度也明显加快。

本示例导出的导出tensonRT模型推理时耗(fp32,对同一张图像推理1000次的平均时耗)

本示例导出的导出tensonRT模型推理时耗(fp16,对同一张图像推理1000次的平均时耗)

对比检测结果

















 1167
1167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









