







一、论文
首先回忆下,之前的NGCF为什么会被优化成lightGCN
1、lightGCN认为非线性激活函数和特征转换对CF模型没有用,因为LightGCN的输入是user和item的ID,没有关于user和item的特征信息,因此非线性激活函数和线性特征转换是没有用武之地的
LR-GCCF移除非线性激活函数,原因在于LR-GCCF的初始embedding也是要通过训练生成的,不包含额外的特征信息
摘要:

在本文中,从两个方面重新审视了基于 GCN 的 CF 模型。首先,凭经验表明,去除非线性会提高推荐性能,这与简单图卷积网络中的理论是一致的。其次,我们提出了一种专门为带有用户项交互建模的 CF 设计的残差网络结构,它缓解了使用稀疏用户项交互数据的图卷积聚合操作中的过度平滑问题。这就是这篇文章主要干的事情。
改进了信息聚合的方法。文章提出了残差的思想,但实际上和NGCF一模一样。
先上代码
def __init__(self, user_num, item_num, factor_num,user_item_matrix,item_user_matrix,d_i_train,d_j_train):
super(BPR, self).__init__()
"""
user_num: number of users;
item_num: number of items;
factor_num: number of predictive factors.
"""
self.user_item_matrix = user_item_matrix
self.item_user_matrix = item_user_matrix
self.embed_user = nn.Embedding(user_num, factor_num)
self.embed_item = nn.Embedding(item_num, factor_num)
for i in range(len(d_i_train)):
d_i_train[i]=[d_i_train[i]]
for i in range(len(d_j_train)):
d_j_train[i]=[d_j_train[i]]
self.d_i_train=torch.cuda.FloatTensor(d_i_train)
self.d_j_train=torch.cuda.FloatTensor(d_j_train)
self.d_i_train=self.d_i_train.expand(-1,factor_num)
self.d_j_train=self.d_j_train.expand(-1,factor_num)
nn.init.normal_(self.embed_user.weight, std=0.01)
nn.init.normal_(self.embed_item.weight, std=0.01)
def forward(self, user, item_i, item_j):
users_embedding=self.embed_user.weight
items_embedding=self.embed_item.weight
gcn1_users_embedding = (torch.sparse.mm(self.user_item_matrix, items_embedding) + users_embedding.mul(self.d_i_train))#*2. #+ users_embedding
gcn1_items_embedding = (torch.sparse.mm(self.item_user_matrix, users_embedding) + items_embedding.mul(self.d_j_train))#*2. #+ items_embedding
gcn2_users_embedding = (torch.sparse.mm(self.user_item_matrix, gcn1_items_embedding) + gcn1_users_embedding.mul(self.d_i_train))#*2. + users_embedding
gcn2_items_embedding = (torch.sparse.mm(self.item_user_matrix, gcn1_users_embedding) + gcn1_items_embedding.mul(self.d_j_train))#*2. + items_embedding
gcn3_users_embedding = (torch.sparse.mm(self.user_item_matrix, gcn2_items_embedding) + gcn2_users_embedding.mul(self.d_i_train))#*2. + gcn1_users_embedding
gcn3_items_embedding = (torch.sparse.mm(self.item_user_matrix, gcn2_users_embedding) + gcn2_items_embedding.mul(self.d_j_train))#*2. + gcn1_items_embedding
# gcn4_users_embedding = (torch.sparse.mm(self.user_item_matrix, gcn3_items_embedding) + gcn3_users_embedding.mul(self.d_i_train))#*2. + gcn1_users_embedding
# gcn4_items_embedding = (torch.sparse.mm(self.item_user_matrix, gcn3_users_embedding) + gcn3_items_embedding.mul(self.d_j_train))#*2. + gcn1_items_embedding
gcn_users_embedding= torch.cat((users_embedding,gcn1_users_embedding,gcn2_users_embedding,gcn3_users_embedding),-1)#+gcn4_users_embedding
gcn_items_embedding= torch.cat((items_embedding,gcn1_items_embedding,gcn2_items_embedding,gcn3_items_embedding),-1)#+gcn4_items_embedding#
user = F.embedding(user,gcn_users_embedding)
item_i = F.embedding(item_i,gcn_items_embedding)
item_j = F.embedding(item_j,gcn_items_embedding)
# # pdb.set_trace()
prediction_i = (user * item_i).sum(dim=-1)
prediction_j = (user * item_j).sum(dim=-1)
# loss=-((rediction_i-prediction_j).sigmoid())**2#self.loss(prediction_i,prediction_j)#.sum()
l2_regulization = 0.01*(user**2+item_i**2+item_j**2).sum(dim=-1)
# l2_regulization = 0.01*((gcn1_users_embedding**2).sum(dim=-1).mean()+(gcn1_items_embedding**2).sum(dim=-1).mean())
loss2= -((prediction_i - prediction_j).sigmoid().log().mean())
# loss= loss2 + l2_regulization
loss= -((prediction_i - prediction_j)).sigmoid().log().mean() +l2_regulization.mean()
# pdb.set_trace()
return prediction_i, prediction_j,loss,loss2
对于每个用户和物品,传播的矩阵形式:
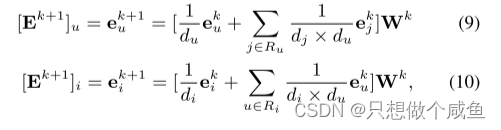
模型的输出是
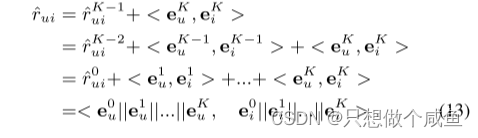
看到最后就会发现,和NGCF是一样的了
这篇文章,暂时也结束了















 2131
2131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









