







2.中级篇
1.非二元变量
在基础篇中我们处理的是购物篮数据,一个事务中是否包含某个项。如果我们面对的数据是,每个事务中都会包含大多数项,但是重要的区别是一个事务中包含某个项的多少是不同的,换句话说,如果我们将项看成是变量(属性),购物篮数据处理的是二元变量,而有可能我们需要处理的是分类变量,甚至是连续型变量。那么我们应该挖掘项集之间的关联性?
基础篇中实战例子处理的便是分类变量,这类变量还是比较容易转变成多个二元变量。针对连续型变量,我们也可以先离散化,转变成分类变量。也可以重新的定义支持度的概念,使之满足一些性质,比如支持度反单调性:
s(A,B)≥s(A,B,C)
,A,B,C是项。
2.序列模式.
基础篇中提到的事务型数据只考虑到了项的同时出现的情况,但是并没有考虑到项的时间属性,比如在超市的顾客购物数据中,会出现顾客在不同时间购买的商品。这样商品便有了序列属性。所以我们需要其他的数据存储方式—序列数据库。下图便是一种序列数据库截图。
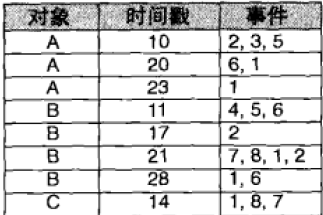
数据中一个对象会出现多次,但是有时间戳来进行区别。我们将一个对象的所有数据整合成一个序列,比如针对对象A,其对应的序列为
<{2,3,5},{1,6},{1}>
<script type="math/tex" id="MathJax-Element-9"><\{2,3,5\},\{1,6\},\{1\}></script>,该序列中有三个
元素
,分别为
{2,3,5}
,
{1,6}
,
{1}
,元素
{2,3,5}
包含三个
事件
,分别为2,3,5.如果一个序列
t
中每个有序元素都是序列
和事务性数据类似,我们首先对频繁序列感兴趣。给定序列数据集
D
和用户指定的最小支持度阈值,序列模式发现的任务是找到支持度大于或者等于minsup的所有序列。对于给定n个事件的集族,所谓的

算法的关键之处在于如何由频繁k-1序列来生成候选k-序列,和apriori算法类似,我们由两个频繁k-1序列合并成一个候选k-序列。这里所用的方法是:序列是按照字典排序构成的(注意)

这种序列合并方法是完备的,也就是不会丢失任何可行的候选,也不会重复的候选序列出现。合并之后,我们需要根据先验规则除去那些不是显然不是频繁的k-序列。然后对原数据进行扫描,确定候选k-序列的支持度。
3.时限约束.
序列数据和事务性数据集的一个很大的区别就是:序列数据是可以对时间进行约束的。具体的约束方式如下:
- 最大时间跨度. 最大时间宽度约束是指整个序列中所允许的事件的最早和最晚发生时间的最大时间差。举个例子来说,假定我们面对的序列为 <{1,3},{3,4},{4},{5},{6,7},{8}> <script type="math/tex" id="MathJax-Element-30"><\{1,3\},\{3,4\},\{4\},\{5\},\{6,7\},\{8\}></script>,时间戳为 (1,2,3...,) 那么子列 <{1,3},{6}> <script type="math/tex" id="MathJax-Element-32"><\{1,3\},\{6\}></script>的最大时间跨度是4原因是三个事件1,3,6发生的最晚的是6,发生时间为5,最早发生时间1,发生时间为1, 所以最大跨度为4.
- 最小时间间隔和最大时间间隔. 时间间隔约束是通过限制序列中的两个相继元素之间的时间差来确定。最大时间间隔 (maxgap) ,表示元素中的事件必然在前一个元素的事件出现后的maxgap内出现。















 2547
2547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









