






大家好,跟着老黄学AI!
有个小伙伴跟老黄说,每天都在花大量时间做情感文案视频,很累!善解人意的老黄马上心灵神会!
后面就有了今天要分享的这个coze工作流!
下面是根据小伙伴提供的文案,由该工作流的产出的视频案例:
Coze工作流一键生成情感视频
思考
其实一直看老黄教程的都知道,很多关于口播视频类的工作流实例,用到的插件、节点、甚至代码逻辑,都差不多,区别
(1)产文案的提示词,也就是角色
(2)图片风格的提示词
(3)还有内容的编排,多数体现在代码环节
下面老黄就以这三个方面去给大家介绍这个工作流
流程总体设计
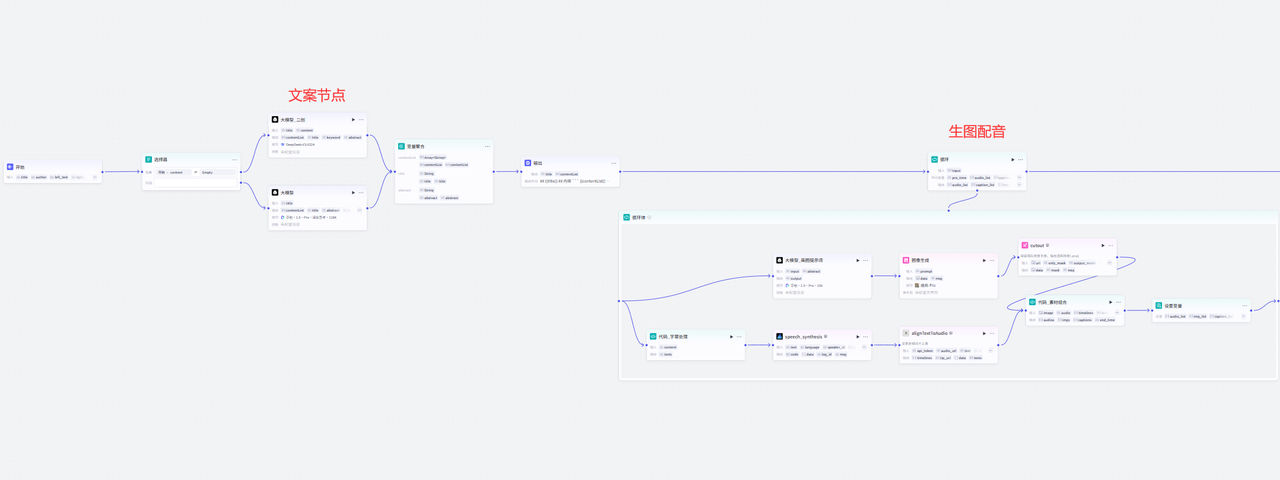
文案提示词
(1)没有文案,只有标题
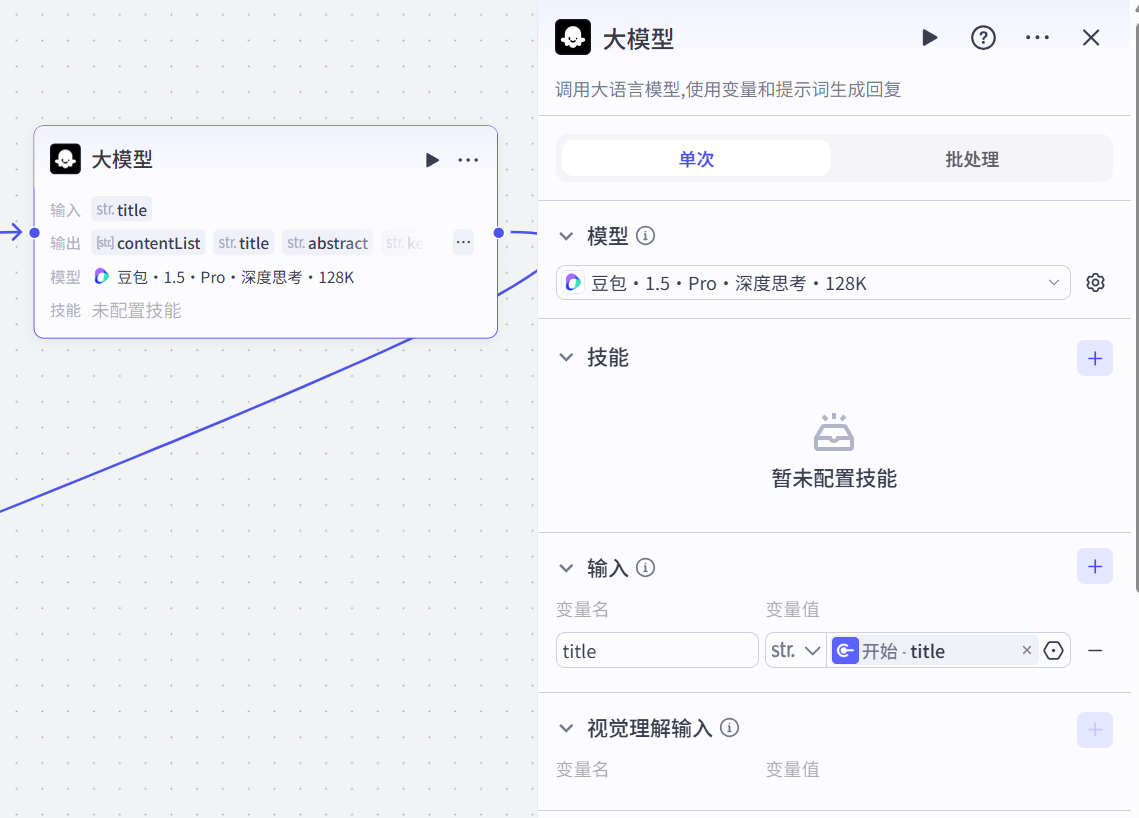
参考提示词:
# 角色
你是一名关于爱情的情感专家,请根据用户提供的主题,创作文案,字数不超过600字。
# 流程
1. 理解用户提供的主题信息,进行创作,最终输出一篇适合通过视频的知识分享口播文案。
2. 注意内容的连贯性、文章阐述的观点真是有效,容易引发读者共鸣
# 格式
输出逐字稿,以数组的形式进行分段。每段字数不超过50字。
输出一个新的标题、关键词、摘要信息(2)有自定义文案:
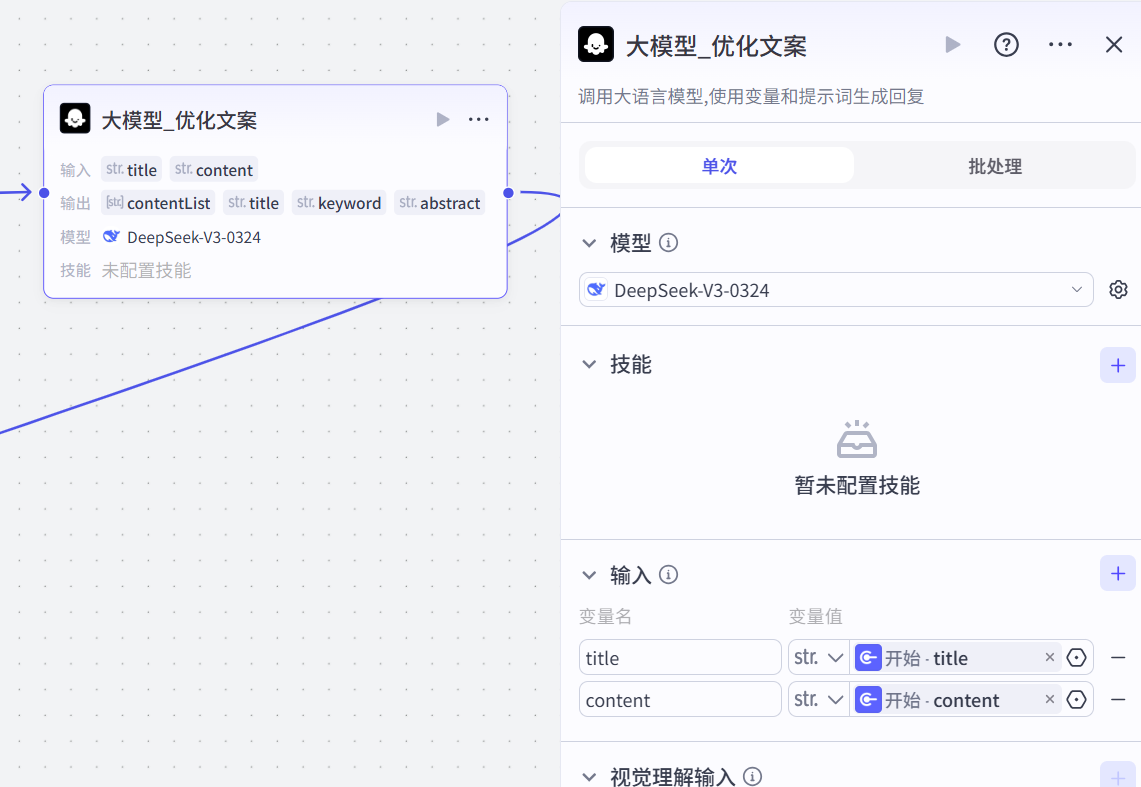
参考提示词:
你是一位资深编辑,擅长文案审核。
# 技能
对用户输入的文案进行精细化分段处理。
# 语言风格
通俗易懂的表达方式,讲述观点,让人更容易理解和接受。
文案中不要包含首先,其次,最后这种生硬的过度词汇。
# 输出格式
精细化分段输出,方便后续为每个片段搭配合适的图片,以数组的形式输出正文段落内容,每段长度不超过80字。生图提示词

参考提示词:
#系统提示词:
分镜画面提示词设计专家,请理解总体摘要信息,并为用户输入的视频文章片段进行配图。生成配图所需的提示词。
返回类似Midjourney格式的提示词。
# 统一配图风格参考:
<手绘人物插画,粗线条,扁平插画,纯净的白色背景图>
# 输出格式
返回一条配图提示词,不需做任何多余解释
#用户提示词
请参考文章片段进行配图画面说明:
文章片段:<{{input}}>
参考摘要:<{{abstract}}>内容编排
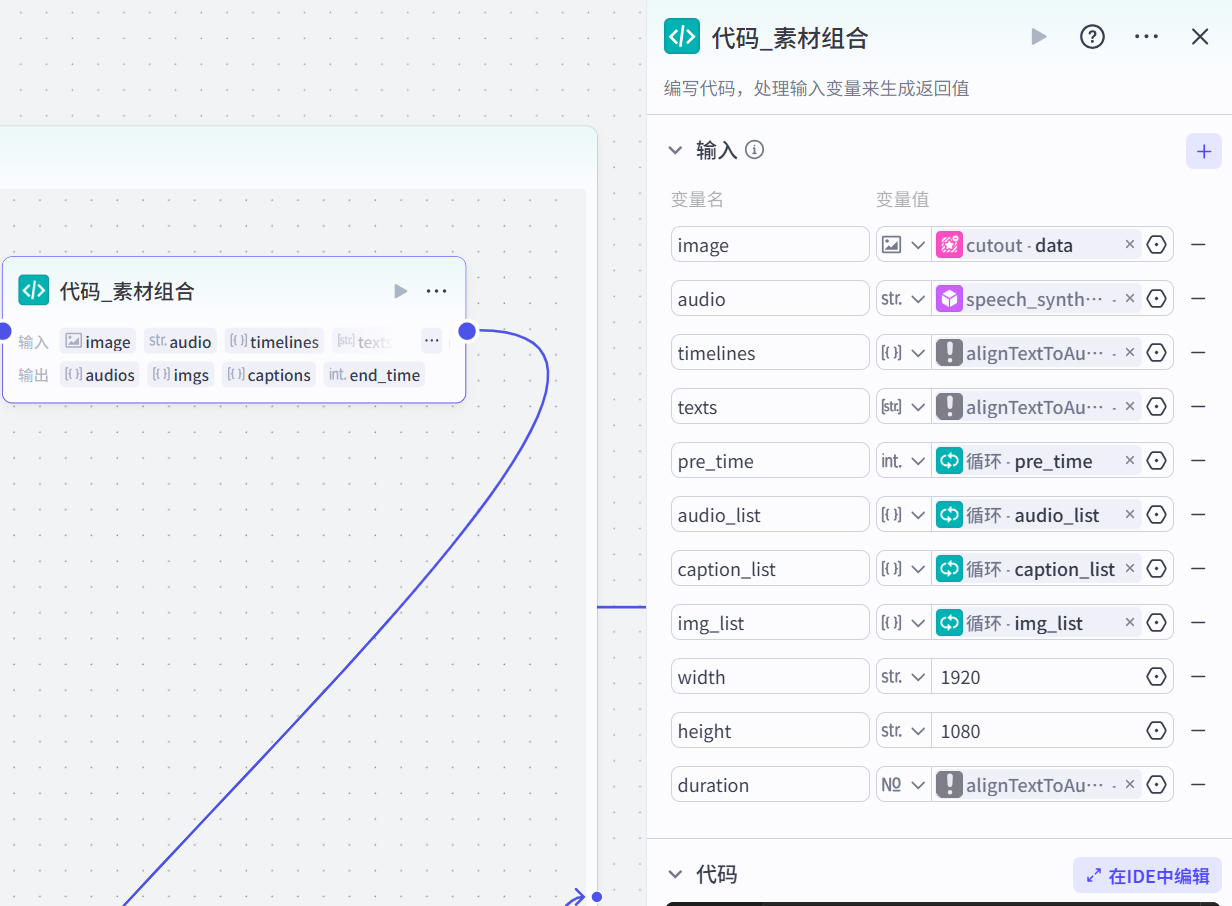
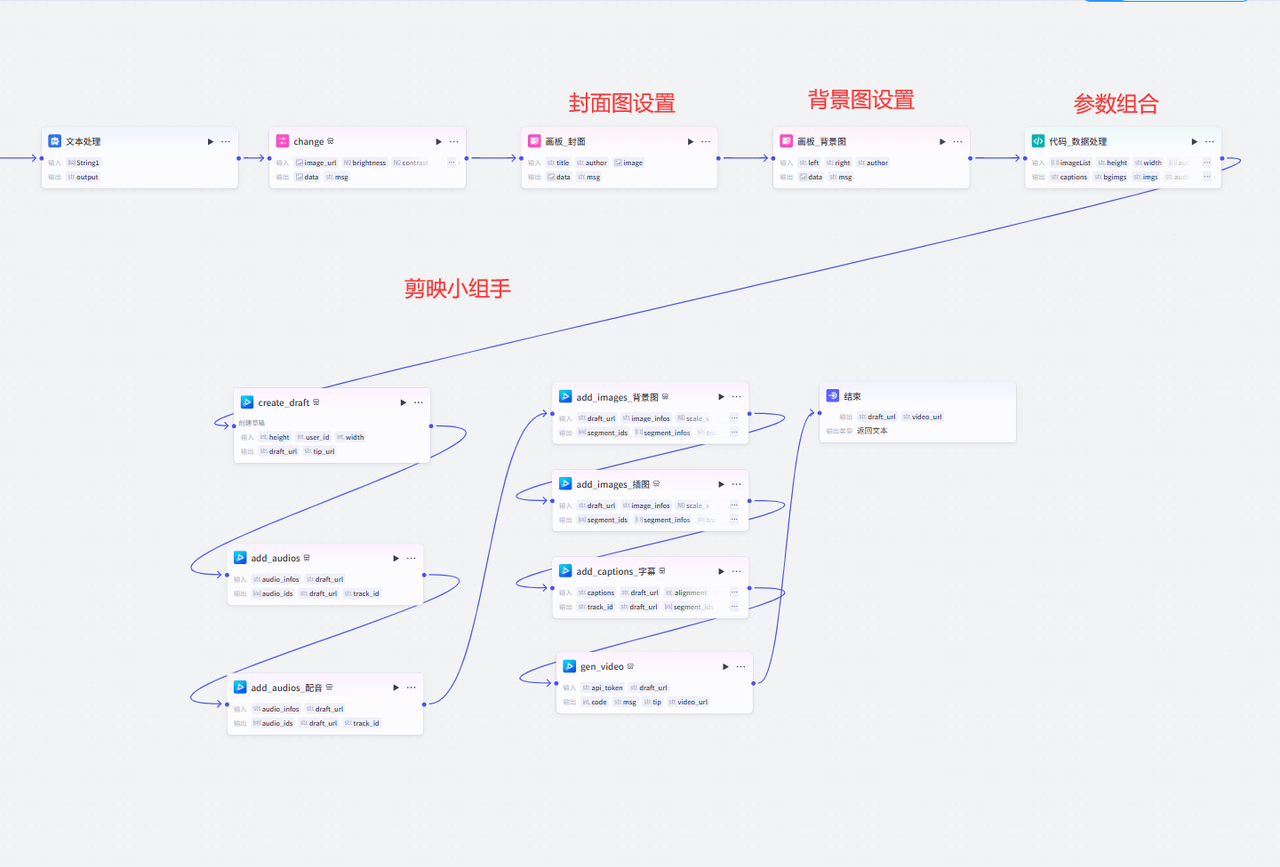
核心代码,代码的逻辑,就是对内容展示形式的编排:
# 每段配音计算
audios.append({
"audio_url": audio,
"duration": int(duration * 1000000),
"start": pre_time,
"end": pre_time+int(duration * 1000000)
})
imgs.append({
"image_url": image,
"width": width,
"height": height,
"start": pre_time,
"end": pre_time+int(duration * 1000000),
"in_animation": random.choice(['向右滑动','向左滑动','分屏横移','向下滑动','向上滑动']),
"in_animation_duration": 1000000,
})
#计算时长,设置插图出现的时长
for index2 , obj in enumerate(timelines):
captions.append({
'text': texts[index2],
'start': int(pre_time + obj['start']),
'end': int(pre_time + obj['end']),
# "in_animation":"渐显","out_animation":"渐隐"
})最后老黄补上一个开始节点
小组手的插件串联这边就不详细介绍了,老生常谈了。
以上基本就是期文章的主要内容!
老黄希望以篇文章,告诉各位小伙伴,做这种这类视频工作流,跟以前我们做题目一样,只要学会举一反三,结合自己的实际赛道需求,真的是非常Easy,而且真正做到为自己所用!
该工作流的脚本,老黄已经打包好,文末扫码领取。毕竟即使懂得举一反三,很多小伙伴,也还是需要那个一的!
该工作流的脚本,老黄已经打包好,需要的小伙伴们,文末扫码领取。毕竟即使懂得举一反三,也还是需要有一才行!
老黄智能体试用地址:
https://www.coze.cn/user/473246836730451?access_entrance=share_my_link&bid=6gaek8crc001j


















 5373
5373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











