







 本文详细介绍了Transformer架构,特别是其与RNN的比较,包括自注意力机制、位置编码、多头注意力以及BERT模型的MaskedLanguageModel和NextSentencePrediction任务。同时涵盖了BERT在文本分类和问答任务中的应用和优势。
本文详细介绍了Transformer架构,特别是其与RNN的比较,包括自注意力机制、位置编码、多头注意力以及BERT模型的MaskedLanguageModel和NextSentencePrediction任务。同时涵盖了BERT在文本分类和问答任务中的应用和优势。
文章目录
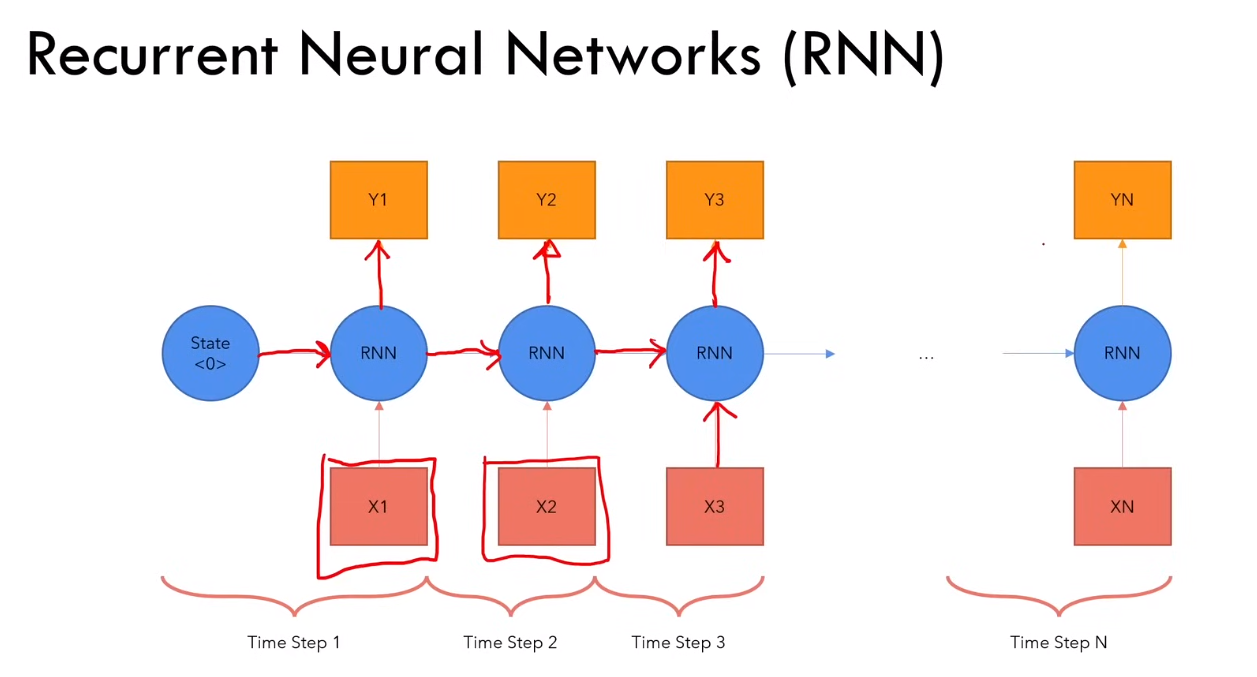
1. RNN
1.1 缺点
1)对于长序列,计算速度慢
2)梯度消失或梯度爆炸(由于链式法则来更新参数,随着计算长度的增加,越小的越小,梯度消失;越大的越大,梯度爆炸)
3)难以获得很长时间之前的信息
2. Transformer
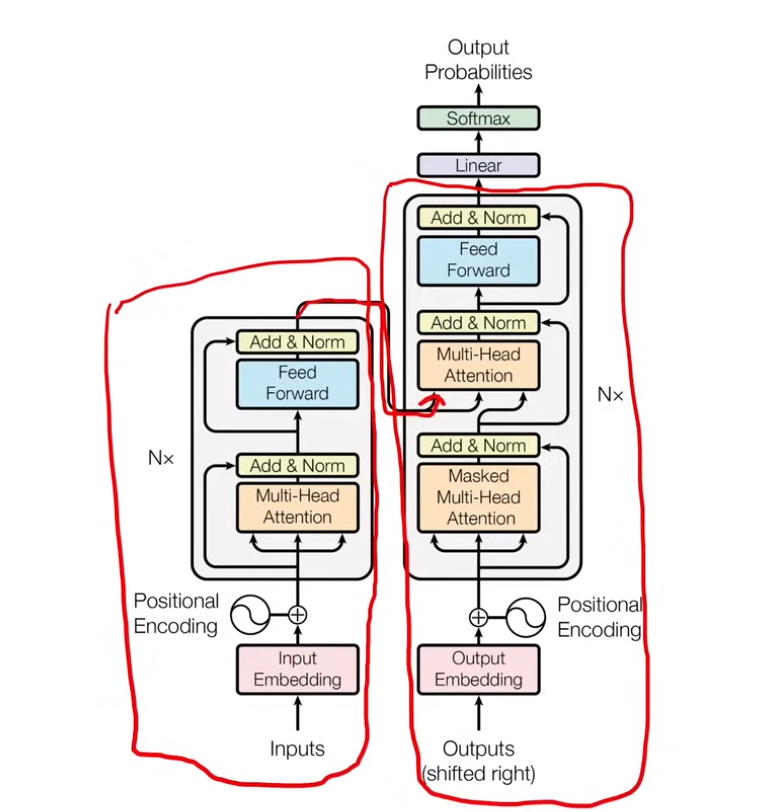
2.1 组成
三部分:encoder + decoder + decoder上面的 linear 层
2.2 Encoder
2.2.1 Input Embedding(嵌入层)
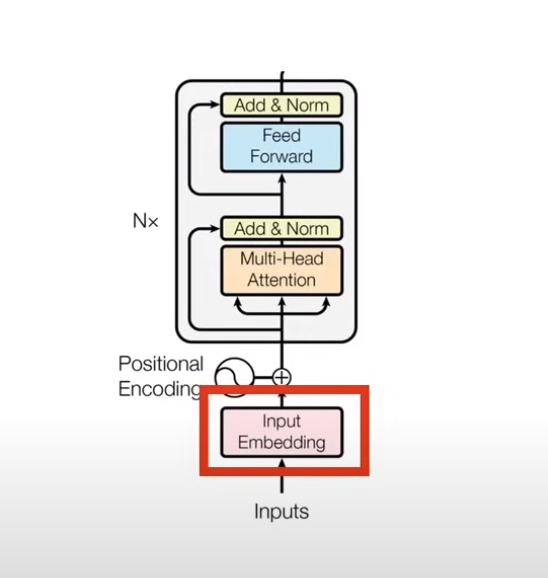

1)嵌入流程
a)将输入进行 tokenizer ,
b)每个 token 映射到单词表中的 token-id
c)每个 id 对应的 embedding(vector size模型有关,传统 Transformer 是512,Bert 是 768)
Ps:token-id 是固定的。但是 Embedding 中的数字是不固定的,值随模型训练而改变
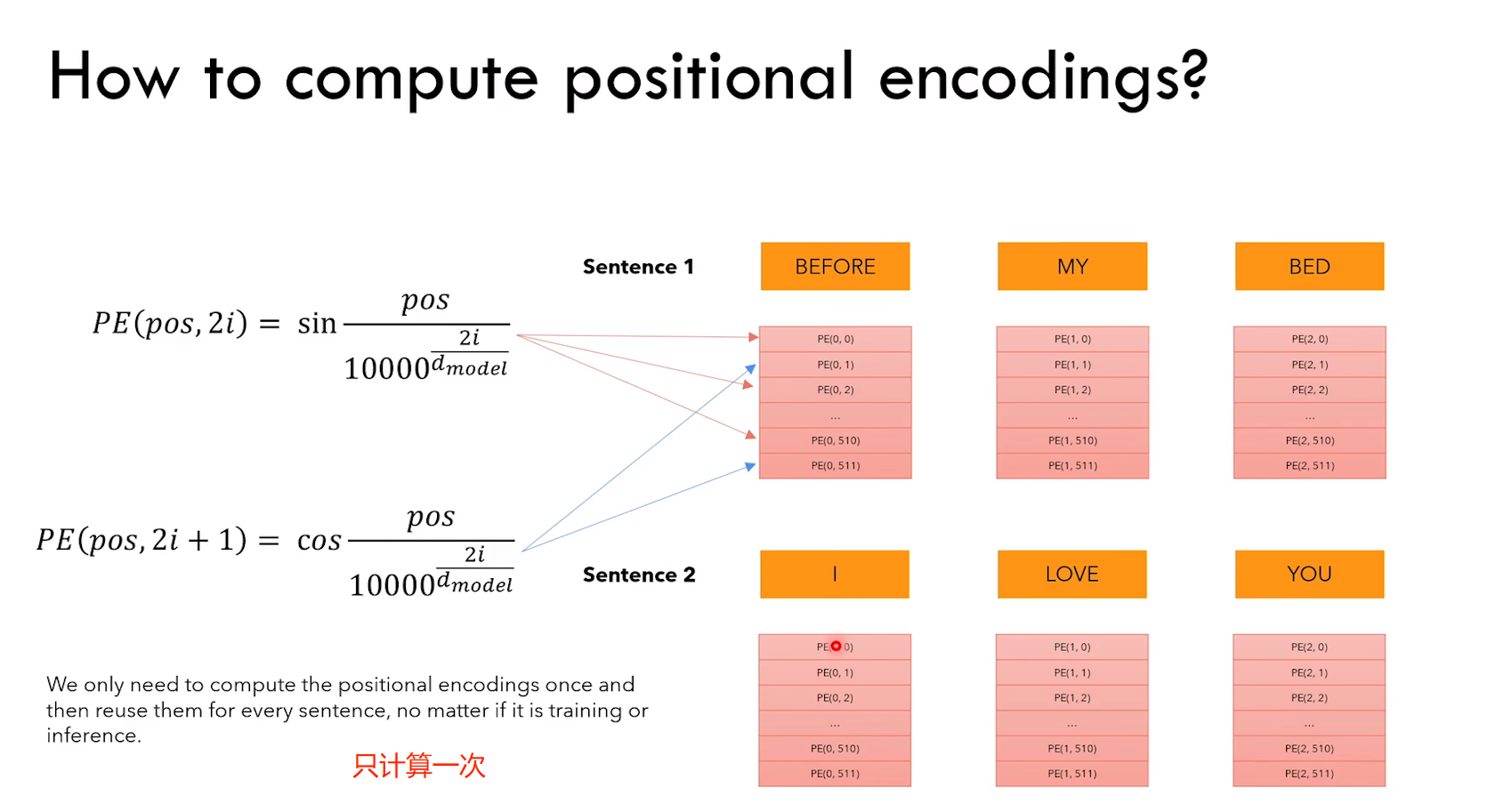
2.2.2 位置编码
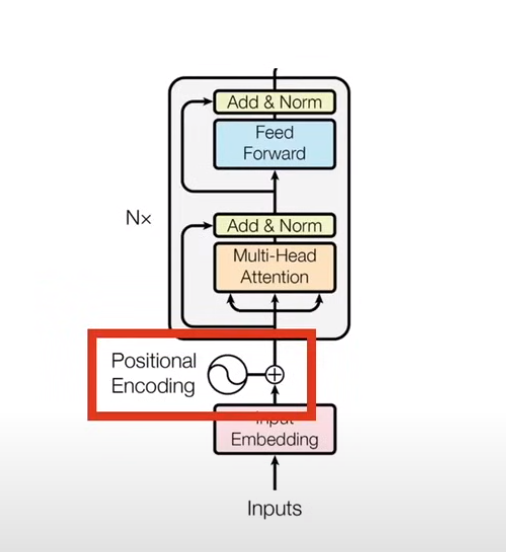
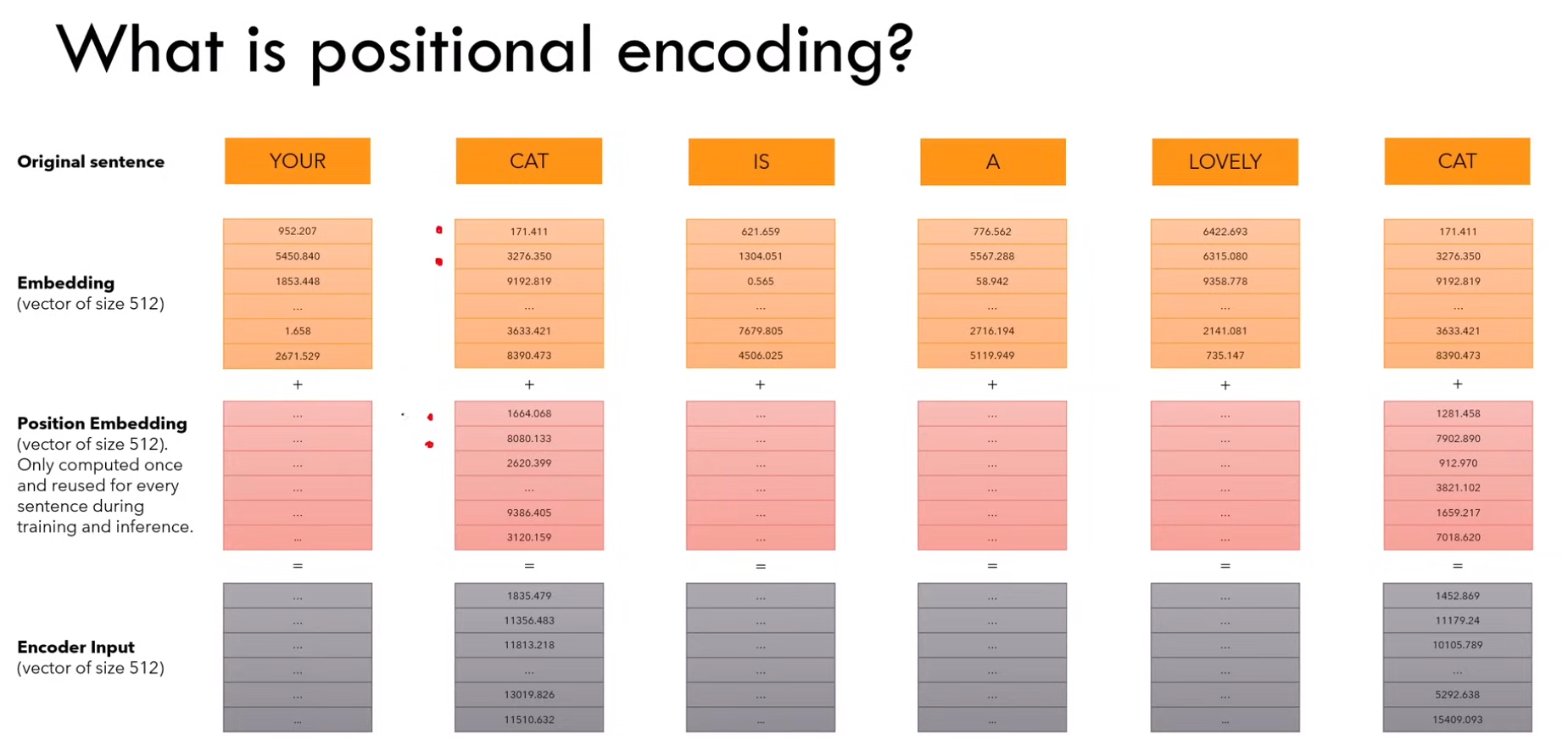
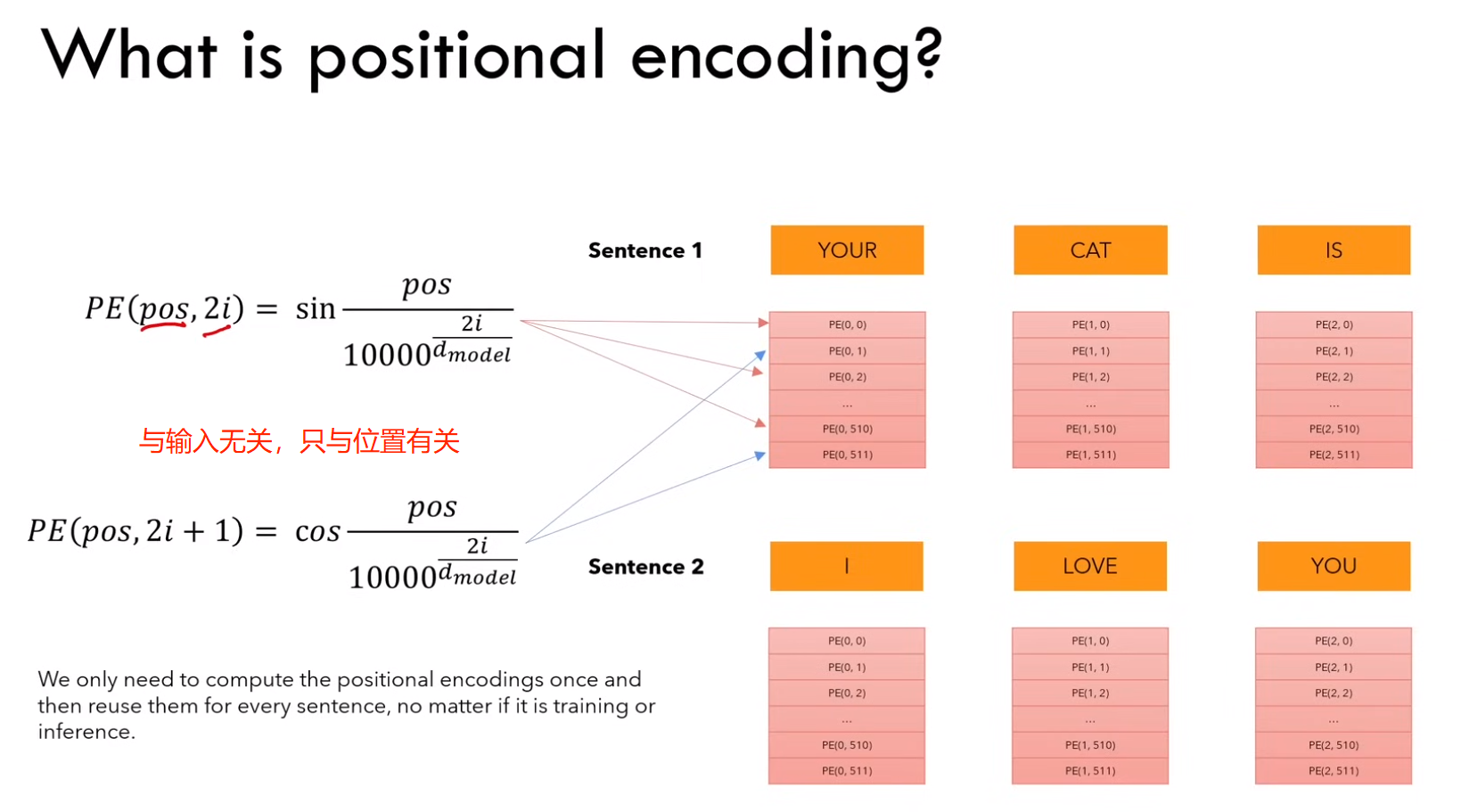
1)什么是位置编码?
a)我们想要 word 带有一些它在句子中的位置信息
b)我们想要模型区分对待离得近的单词,和离得远的单词(因为离得近可能语义上更接近等等原因)
c)希望模型能够学到位置编码带来的 pattern
2)位置编码的特点
a)embedding + position embedding = encoder input
b)position embedding 只计算一次,然后在训练和测试期间使用
2.2.3 多头注意力
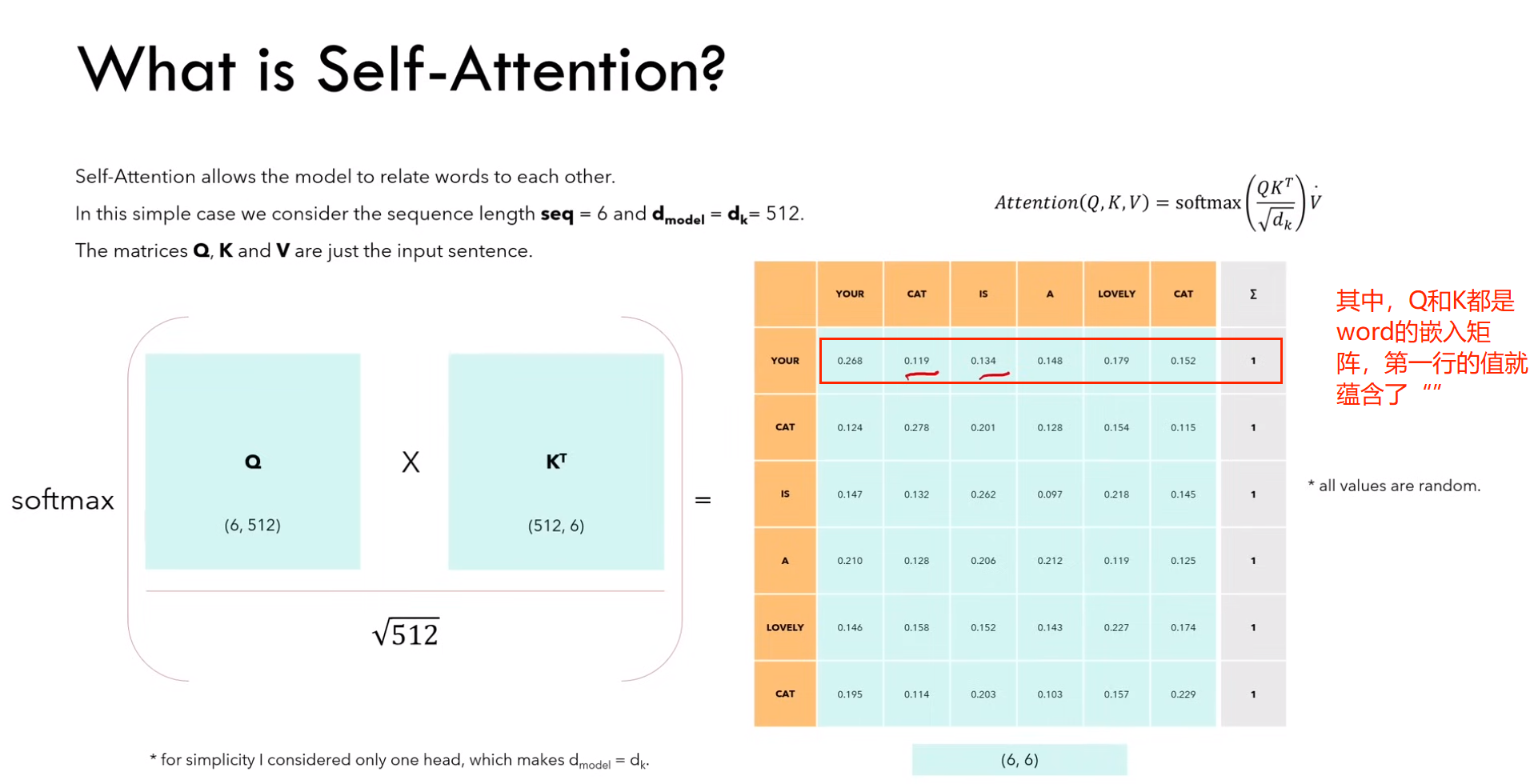
1)什么是 self-attention?(单头)
a)self-attention 允许模型将单词关联起来
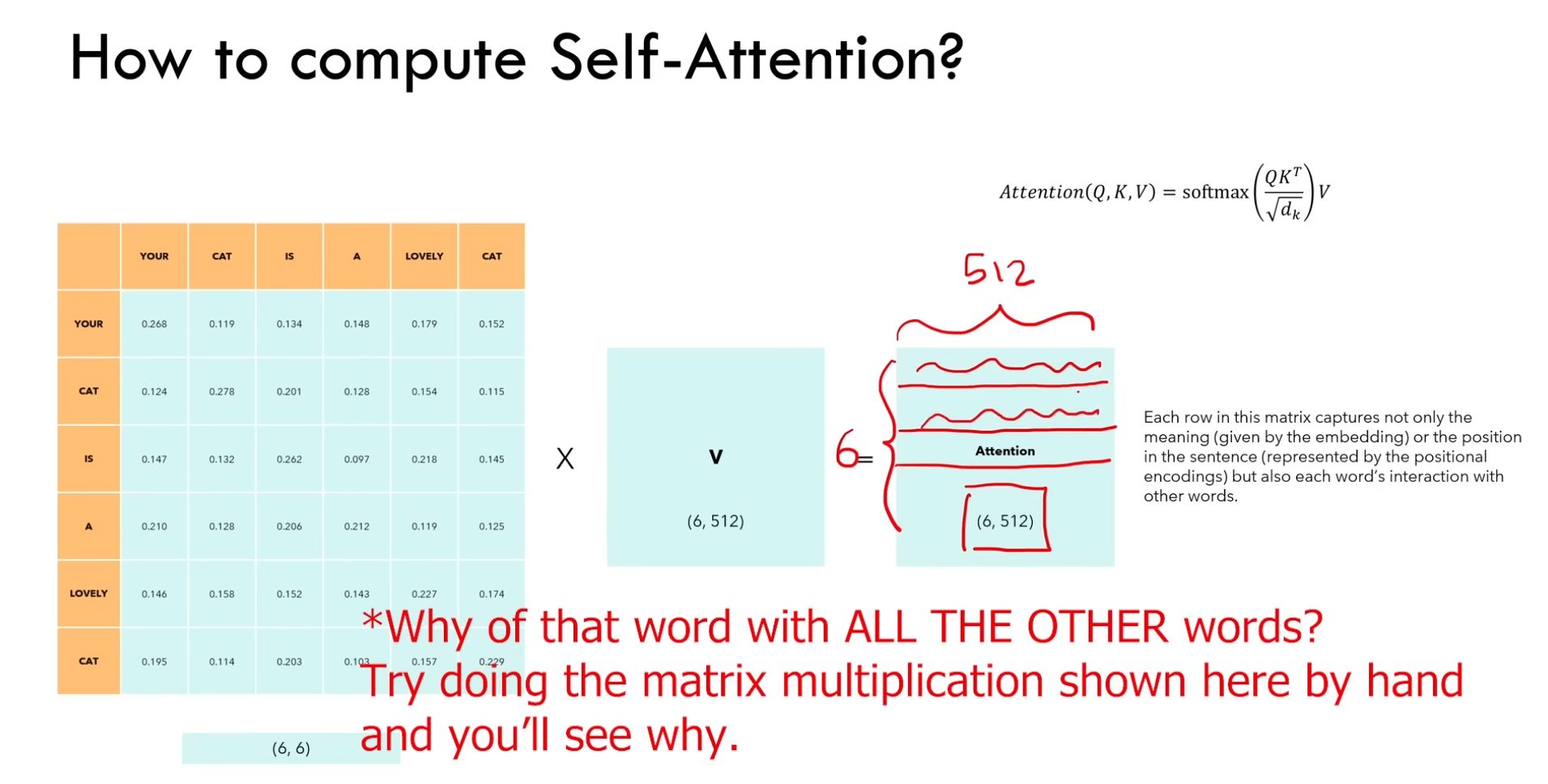
如上图 Q * KT 所示,Q 和 K 维度和单词的嵌入矩阵相同(也就是前面 embedding + position embedding)。
Ps:注意只是维度相同,Q K V 矩阵里面的参数应该是随机初始化的。
所以图中红色框的矩阵第一行中每个元素的含义可以看作单词 “your” 与其他单词之间的关系强弱。
b)再乘以 V 之后得到的矩阵,每个向量嵌入里面包含:语义嵌入、位置信息、与其他单词的交互(下图)
2)self-attention 的一些细节
a)具有排列不变性
eg:输入序列 ABCD 或者序列 ACBD。
其中 BC 的位置交换了,但是最终得到的 B 和 C 的嵌入向量也对应位置交换,向量值是不变的。
b)前面举例的 self-attention 不需要参数。截止到现在的笔记,单词之间的交互只由他们的 embedding 和 position embedding 驱动,后面的笔记会发生改变。
c)Q 和 K 相乘得到的矩阵对角线的值应该是最大的
d)如果我们不想让某些位置交互,可以在使用 softmax 之前,将他们两者对应的值设为 -∞,那么经过 softmax 之后那里的值就变成了0。decoder 中可以使用(eg:想取消“your” 和 “cat” 的交互,就将第一行第二列设置为 0)
3)多头注意力

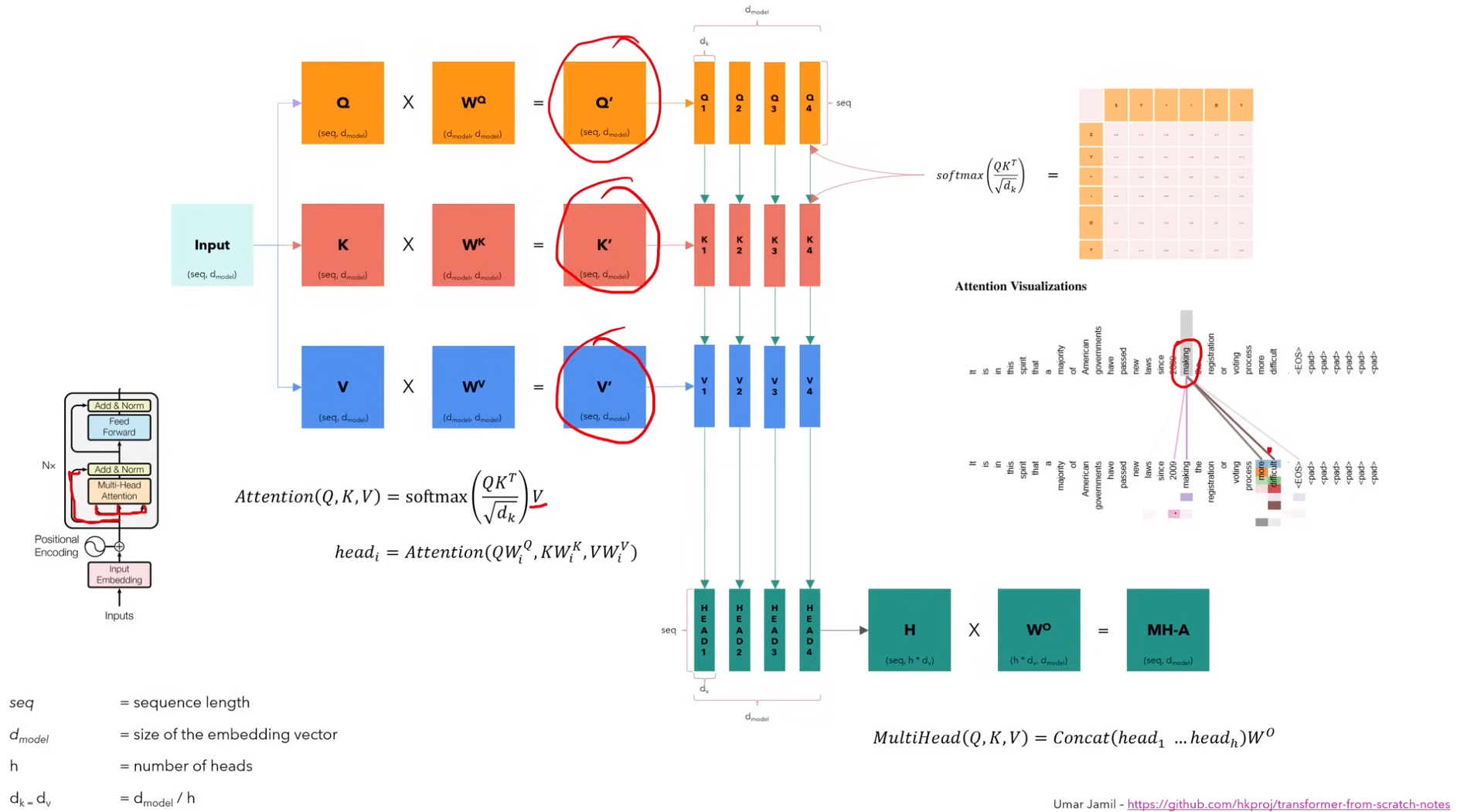
1)如下图所示,最初的 Q、K、V 就是经过positional encoding 的输入,也就是图中蓝色 input 的 copy。分别乘以不同的参数矩阵后,才变成不同的东西
2)其中,注意力头的个数是 h。每个注意力头对应的矩阵(seq,dv),这里dv = dmodel / h。(其中dmodel就是模型vector size)
3)不同头对应的现实含义即,不同的头可能会捕获某个单词的不同含义,不如图中单词图中,某个单词指向了很多的词,那该单词会有多种词义,这些不同的词义就是由不同的注意力头来捕获的
为什么这三个矩阵被称作 Q、K、V?
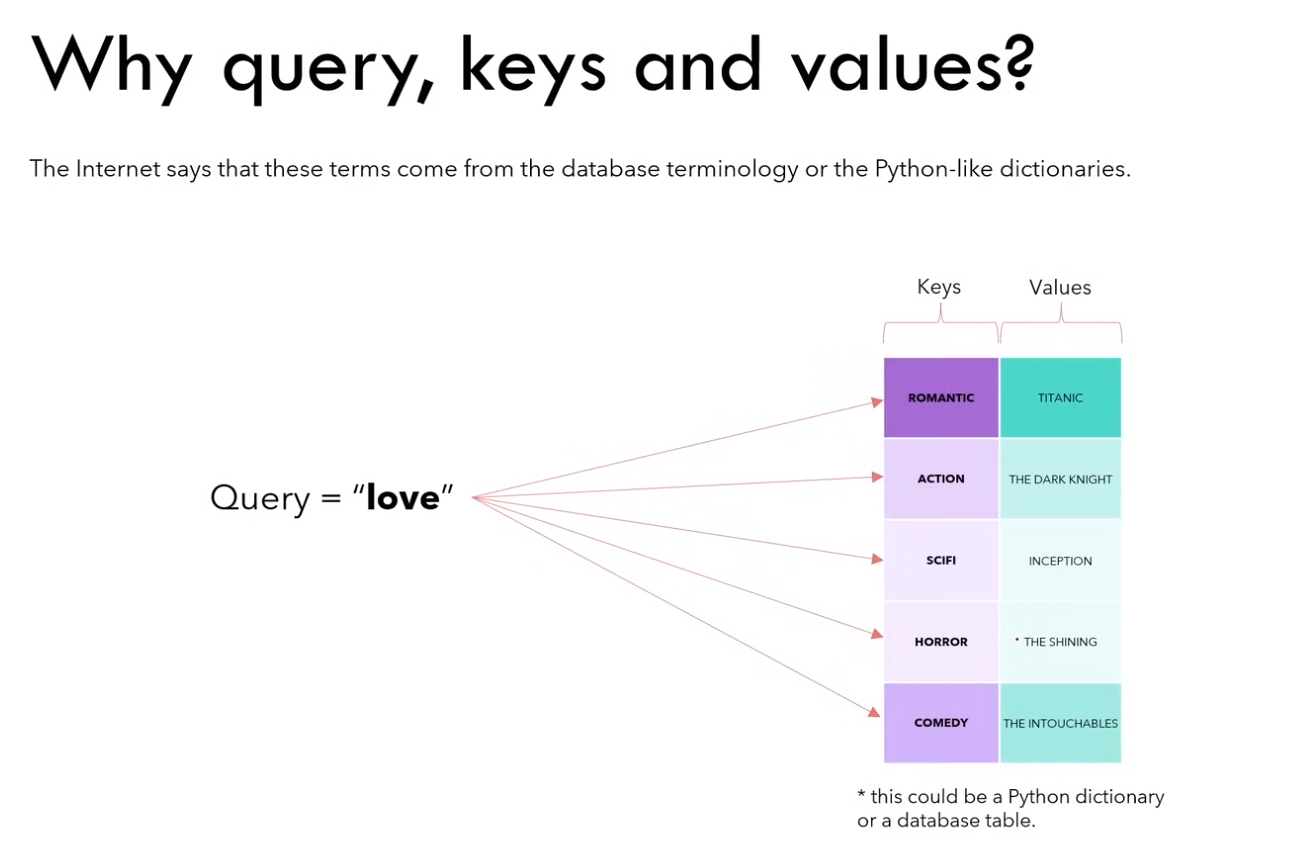
eg:以 python 字典的视角来看,图中的 query、keys 和 values 都是被表示成向量。通过 q 与 k 的运算,实际上是找与 “love” 这种类型的电影最相似的电影,最终 “romantic” 可能是最相似的。
2.2.4 Add & Norm
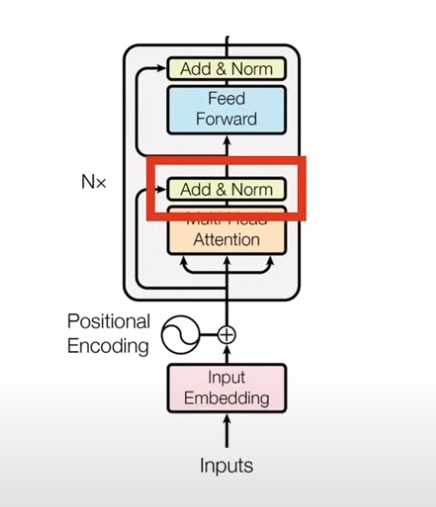

1)什么是 layer normalization?
对于一个batch中的所有item进行独立的归一化,利用均值和方差公式
2.3 Decoder
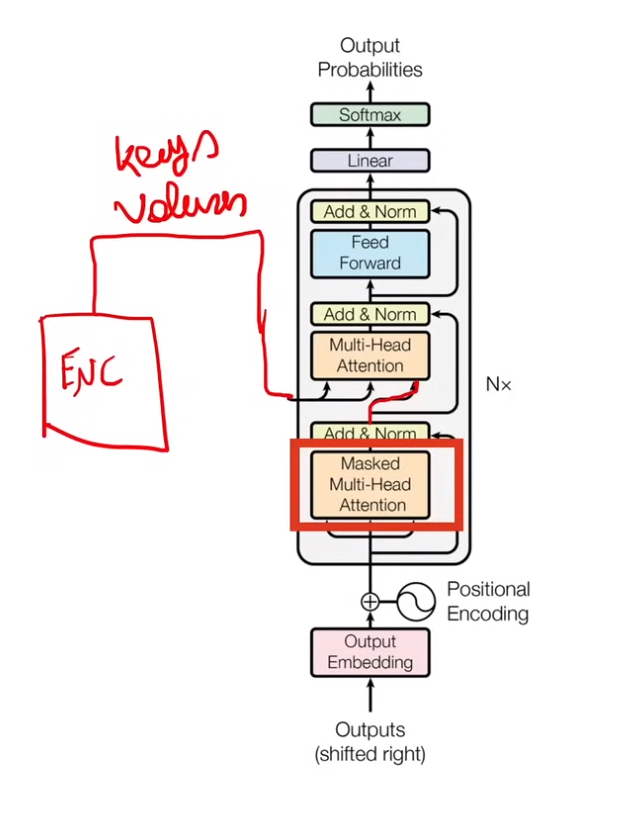
2.3.1 概览
1)首先 output embedding 和 positional encoding,与输入的时候类似
2)经过 masked multi-head attention (这里是decoder的self-attention)得到的是下一次multi-head attention的query
3)encoder 输出以 keys 和 values 的方式传入multi-head attention,querys是decoder。(这里是encoder 和 decoder 的cross-attention)
2.3.2 Masked multi-head attention
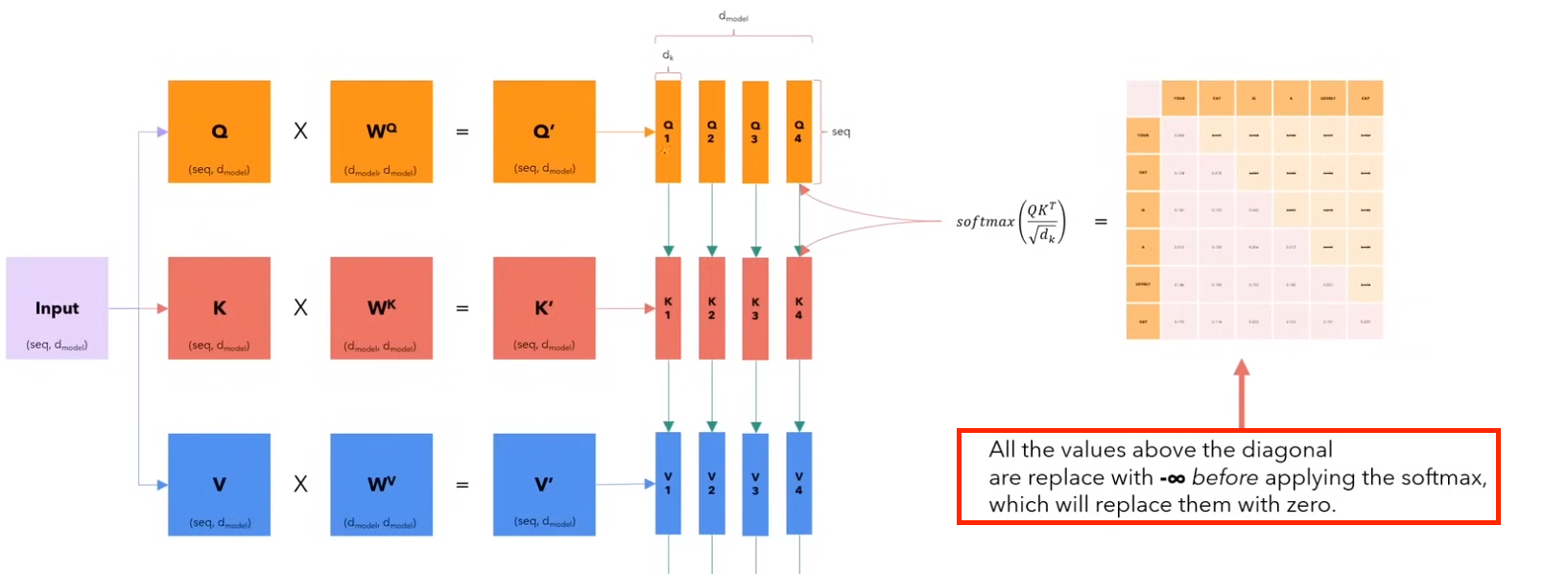

1)使用 masked 的意思是说,在输出的时候,一个词只能根据前面的词输出,而不能看到后面的词
2)也就是图中对角线上方的元素在softmax之前全为-无穷
3)而获取这个矩阵是Q 和 K 的运算来得到的
4)所以只能使用 decoder 的 query 矩阵,而用 encoder 的 key 矩阵
2.4 Transformer 模型的训练和推理
以翻译任务为例
2.4.1 训练
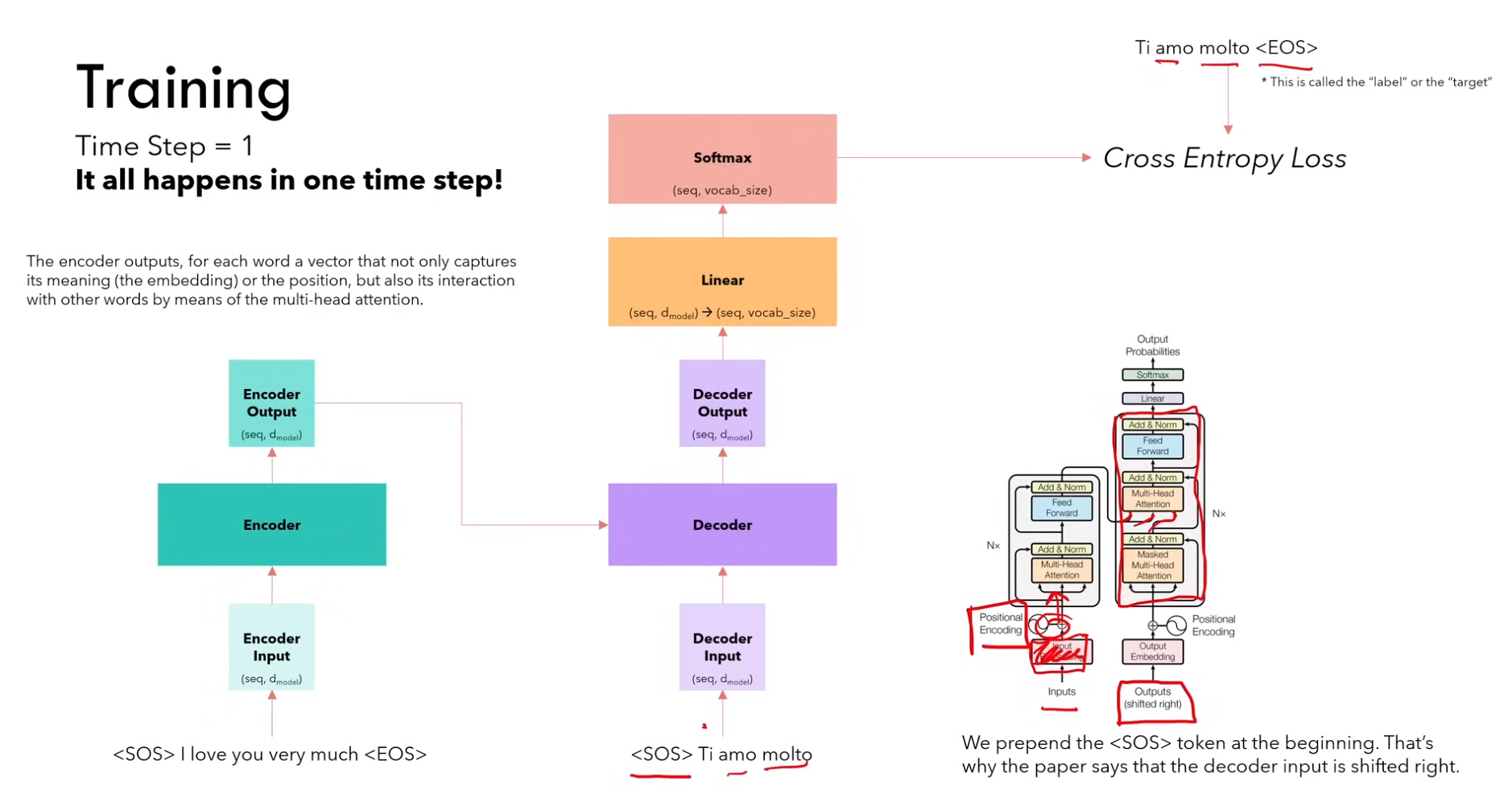
1)encoder输入:<sos> i love you very much <eos>
2)decoder输入:<sos> ti amo molto
decoder输出:ti amo molto <eos>
Ps:由于这种 masked 机制,所以可以一次性输入,输出的 ti 是根据\<sos>获得,输出的 amo 是根据\<sos> ti 获得,以此类推
PPs:当然,除了上面的单词输入,decoder 需要补全 token 来补充其模型需要的输入长度
2.4.2 推理
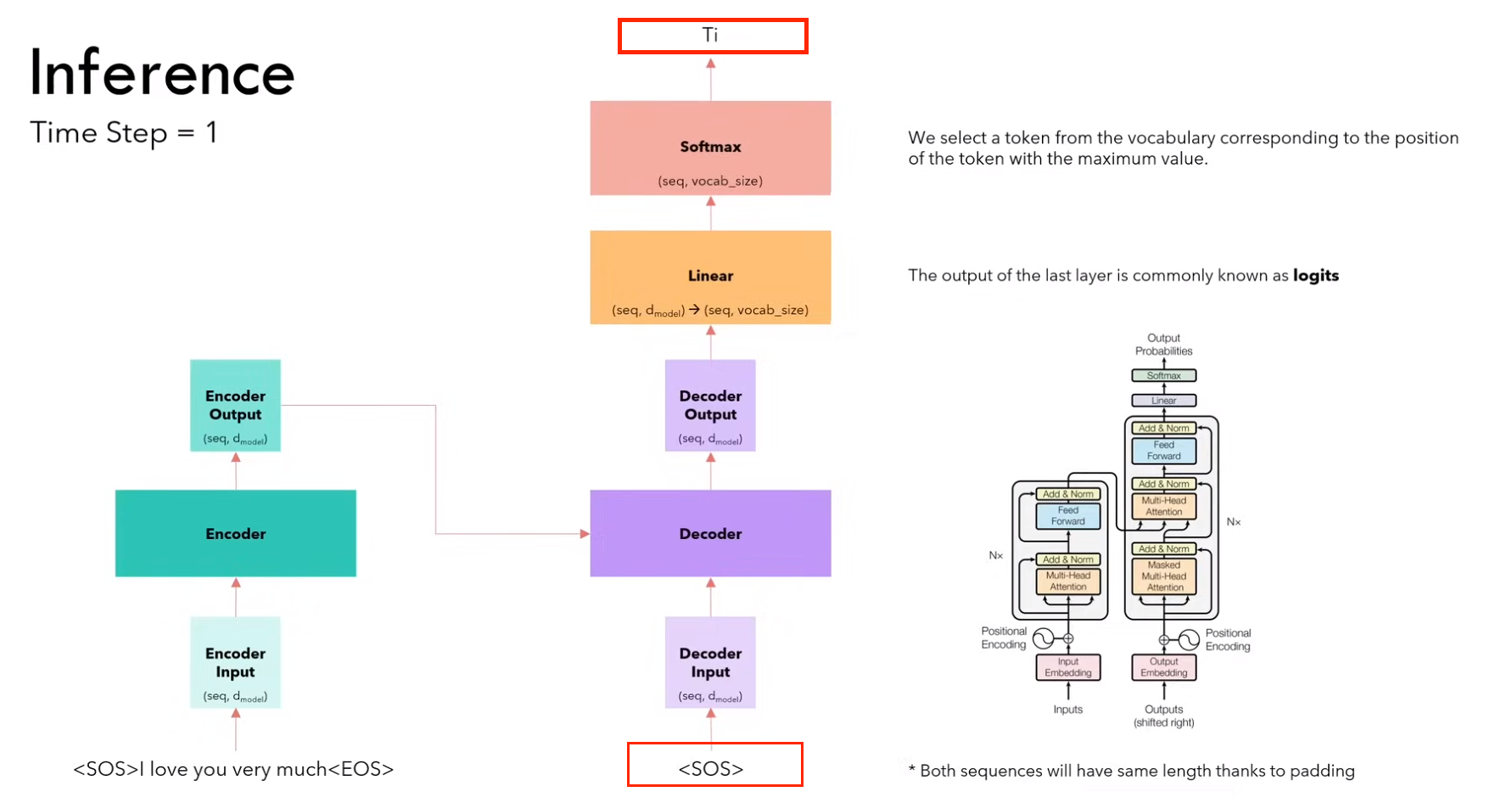
1)第一步:输入 <sos>,输出 ti
(需要进行 encoder 和 decoder 的计算)
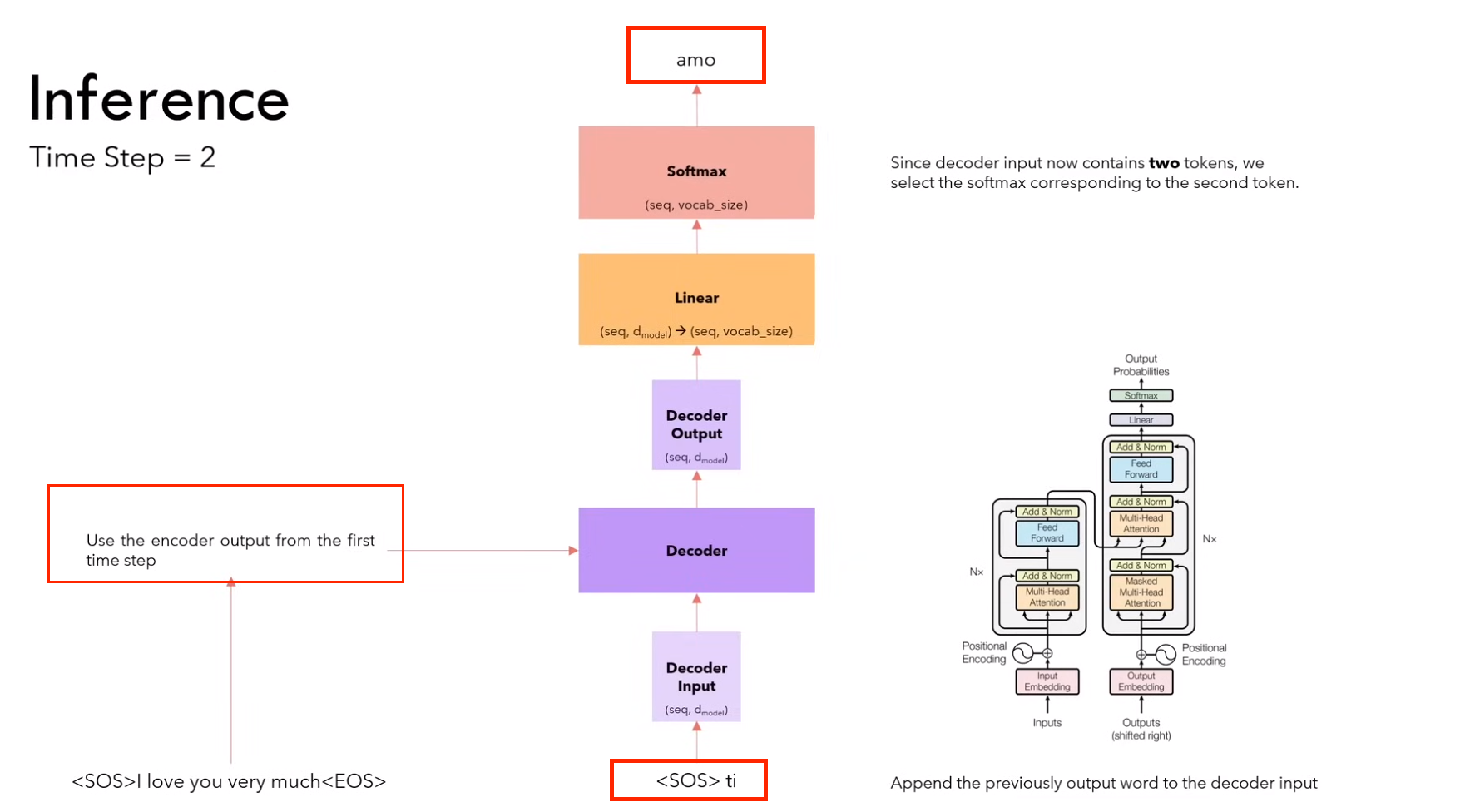
2)第二步:输入<sos> it,输出 amo
(因为encoder不变,所以不用计算encoder,只计算decoder)
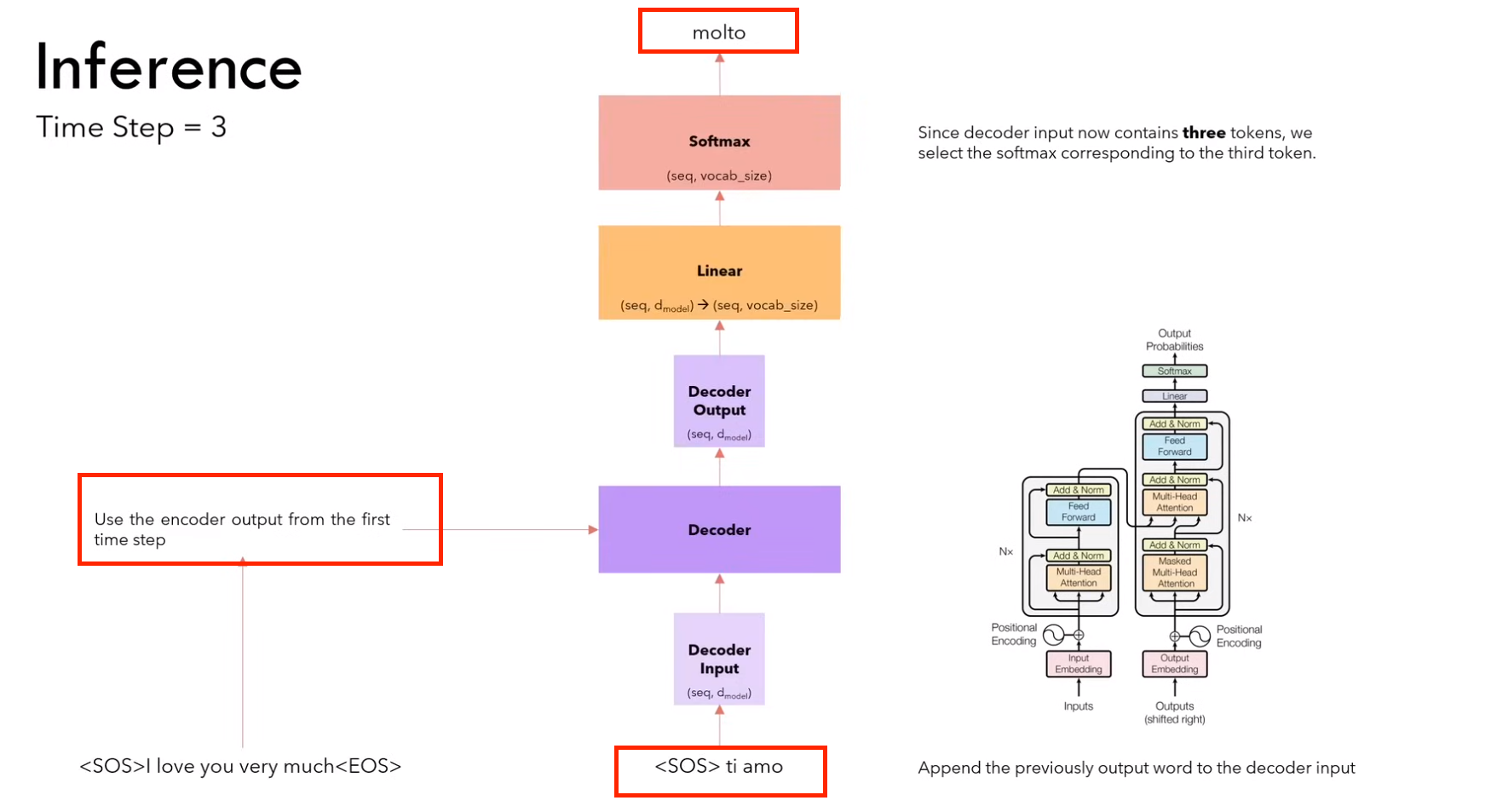
3)第三步:输入<sos> it amo ,输出 molto
(因为encoder不变,所以不用计算encoder,只计算decoder)
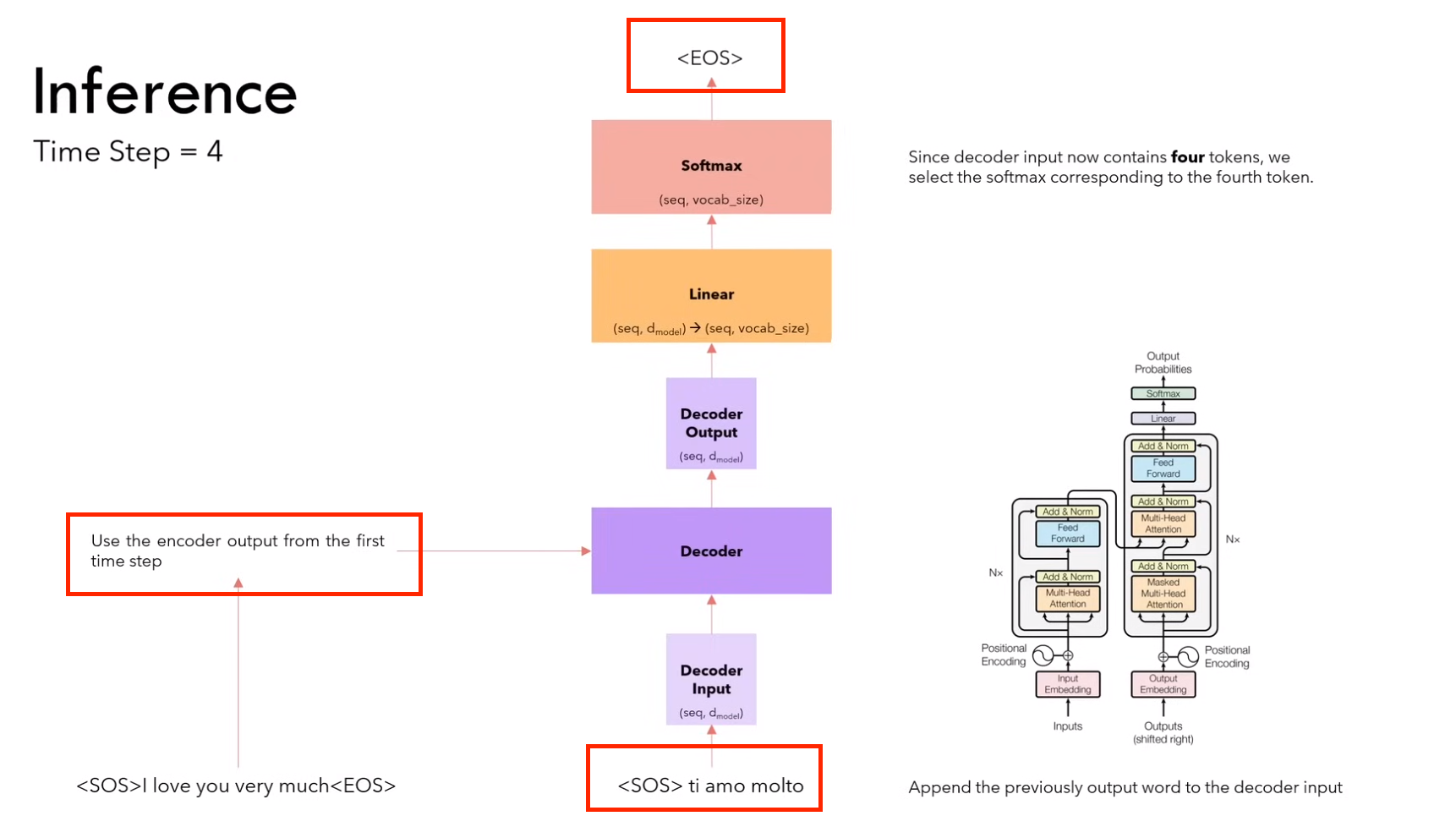
4)第四步:输入<sos> it amo molto,输出 <eos>
(因为encoder不变,所以不用计算encoder,只计算decoder)
推理策略
通常使用 beam search,而不是贪婪搜索

2.4.3 与 RNN 相比的优势
RNN对于长序列时间长,而 Transformer 的所有的输入都是在同一时间输入完成的,使得训练长序列变得简单和快速。
3. 复习
3.1 Language model

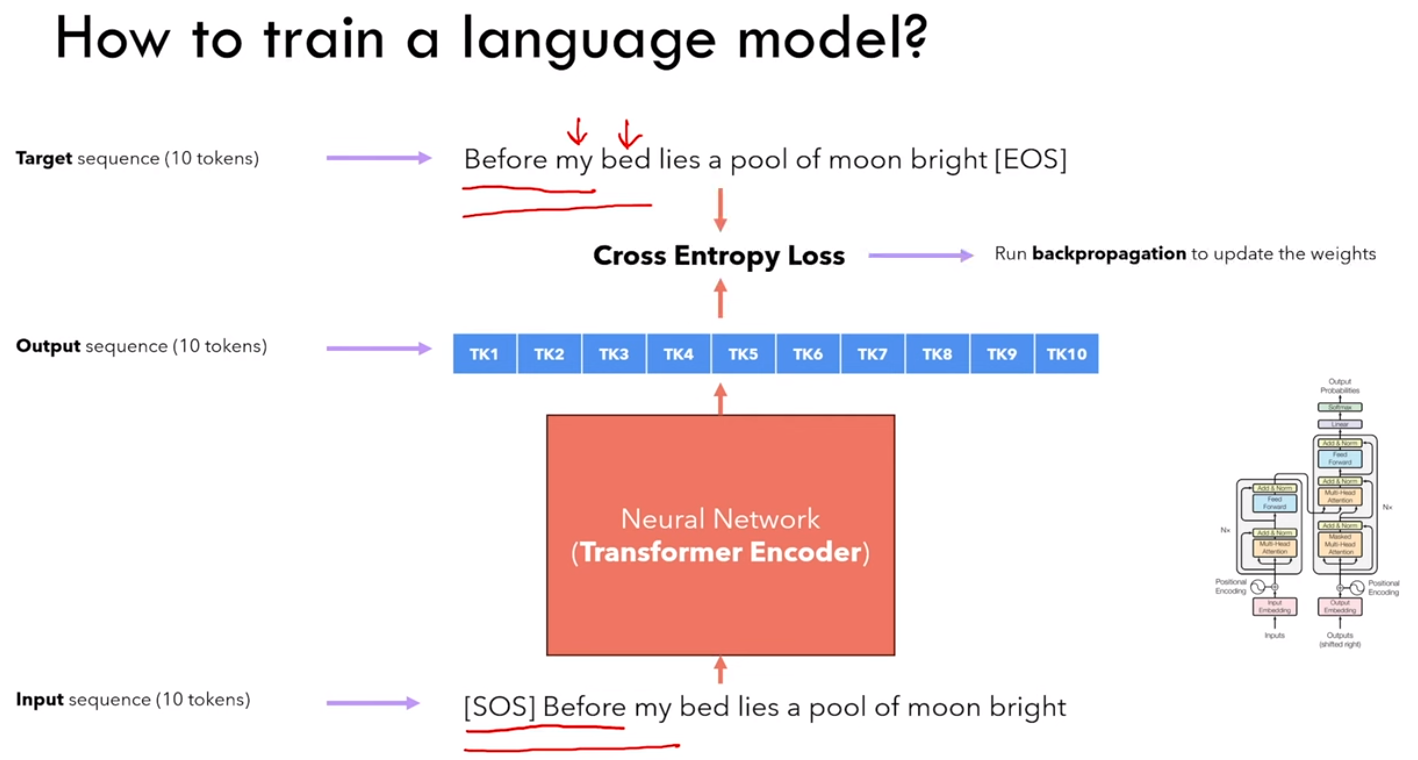
什么是语言模型 language model ?
语言模型是一个概率模型,预测一个 word 出现的概率。
eg:china 这个 word 出现在 shanghai is a city in 后面的概率。
3.1.1 训练
3.1.2 推理

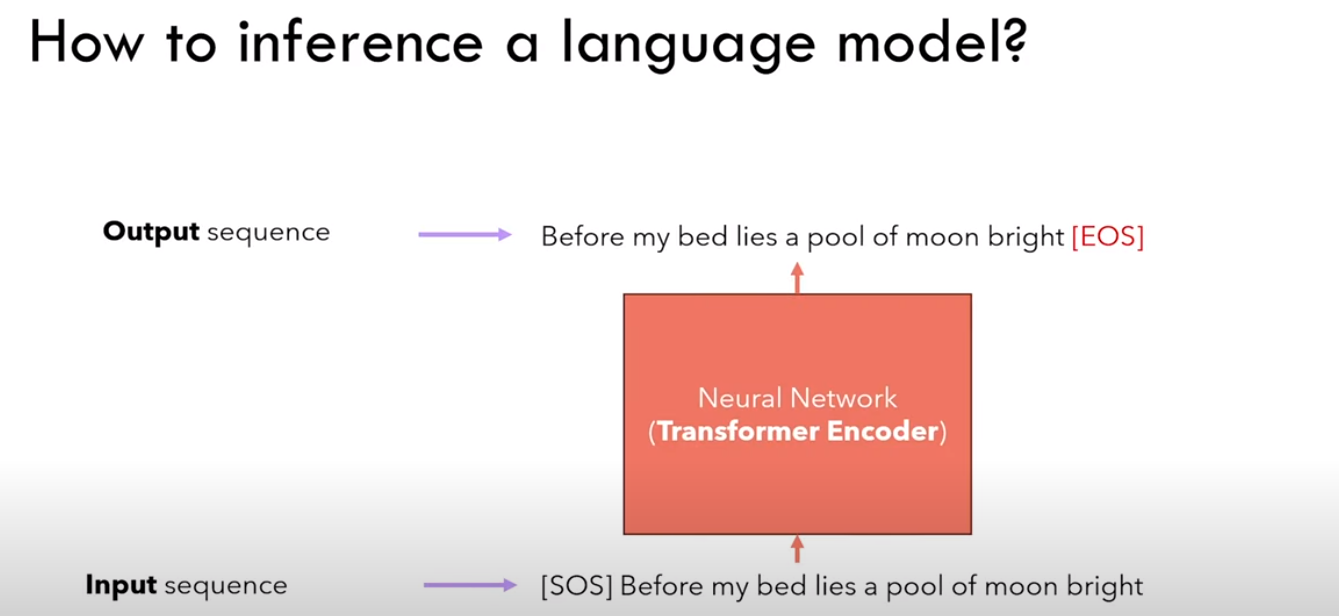
Ps:感觉应该是生成式模型
输入[SOS],输出 Before
接着输入 Before ,输出 my
······,以此类推
最后输入 bright,输出 [EOS]
3.2 Transformer 架构(Encoder)
3.2.1 嵌入向量
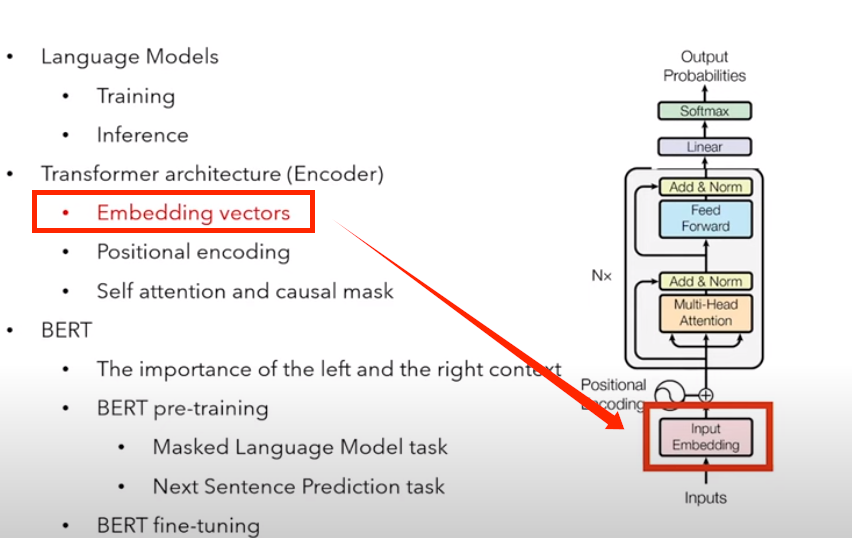

为什么使用向量来表示 word ?
1)希望具有相近含义的 word 在向量空间中更接近
2)这里的接近使用余弦相似度来衡量,或者是点积(dot product)
(不同模型用到的 tokenizer:
LLama 使用 Byte-Pair Encoding tokenization
Bert 使用 WordPiece tokenization)
3.2.2 位置编码

3.2.3 自注意力和 causal mask
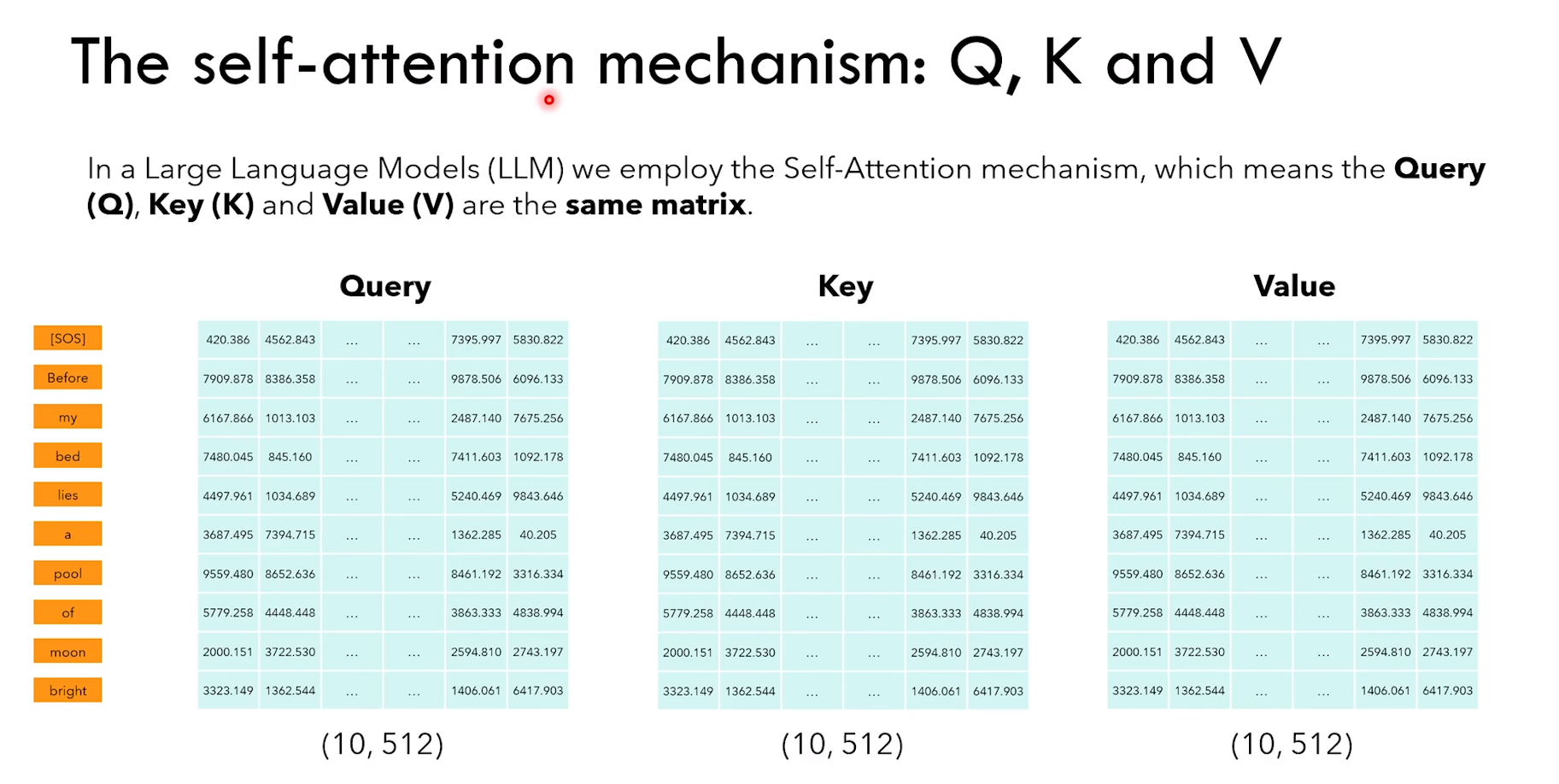
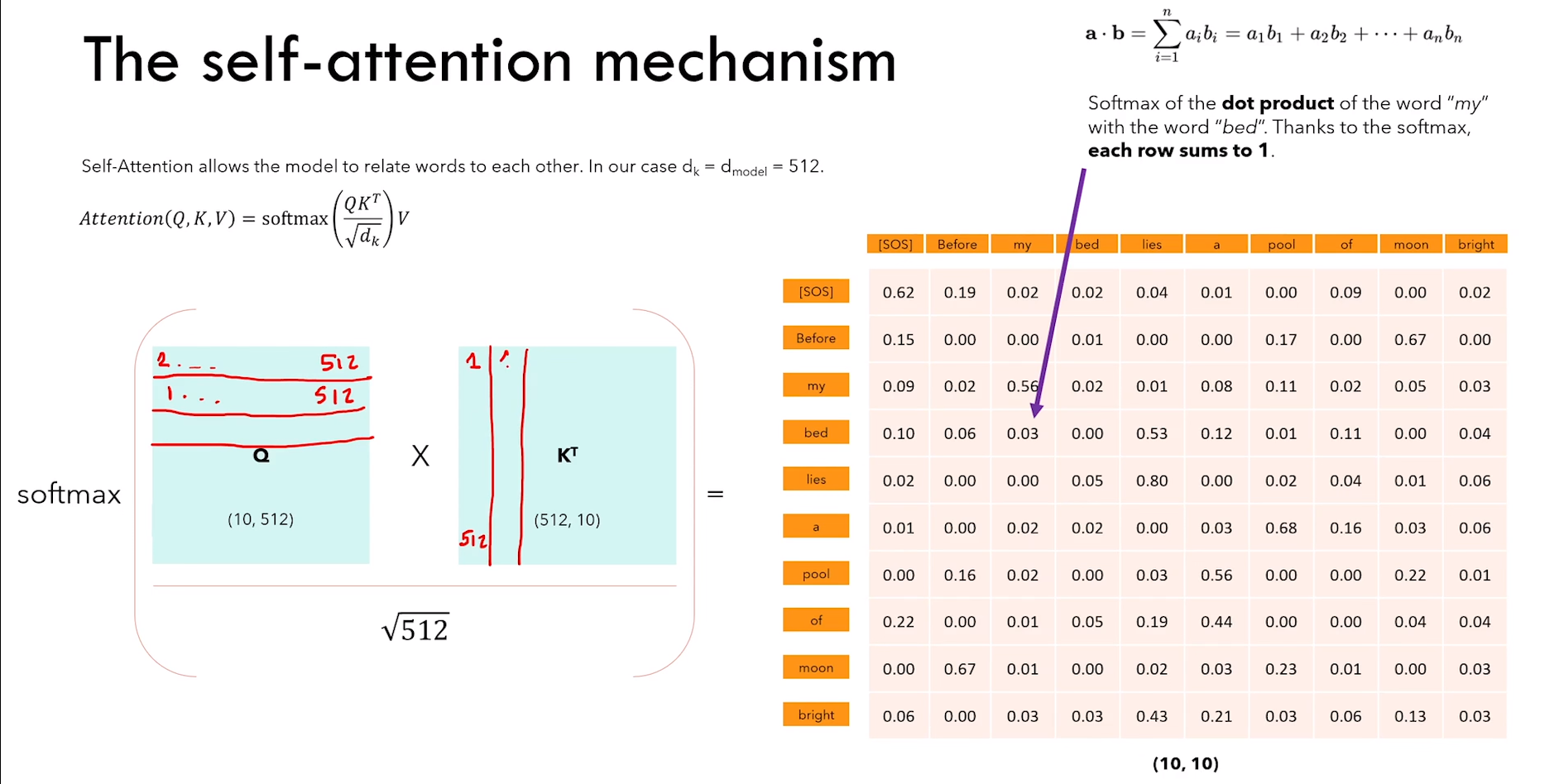

Self-attention(自注意力)
1)所以这里的 query、key、value,都是 encoder 输入矩阵的 copy 版本
Ps:翻译任务中会用到 cross-attention
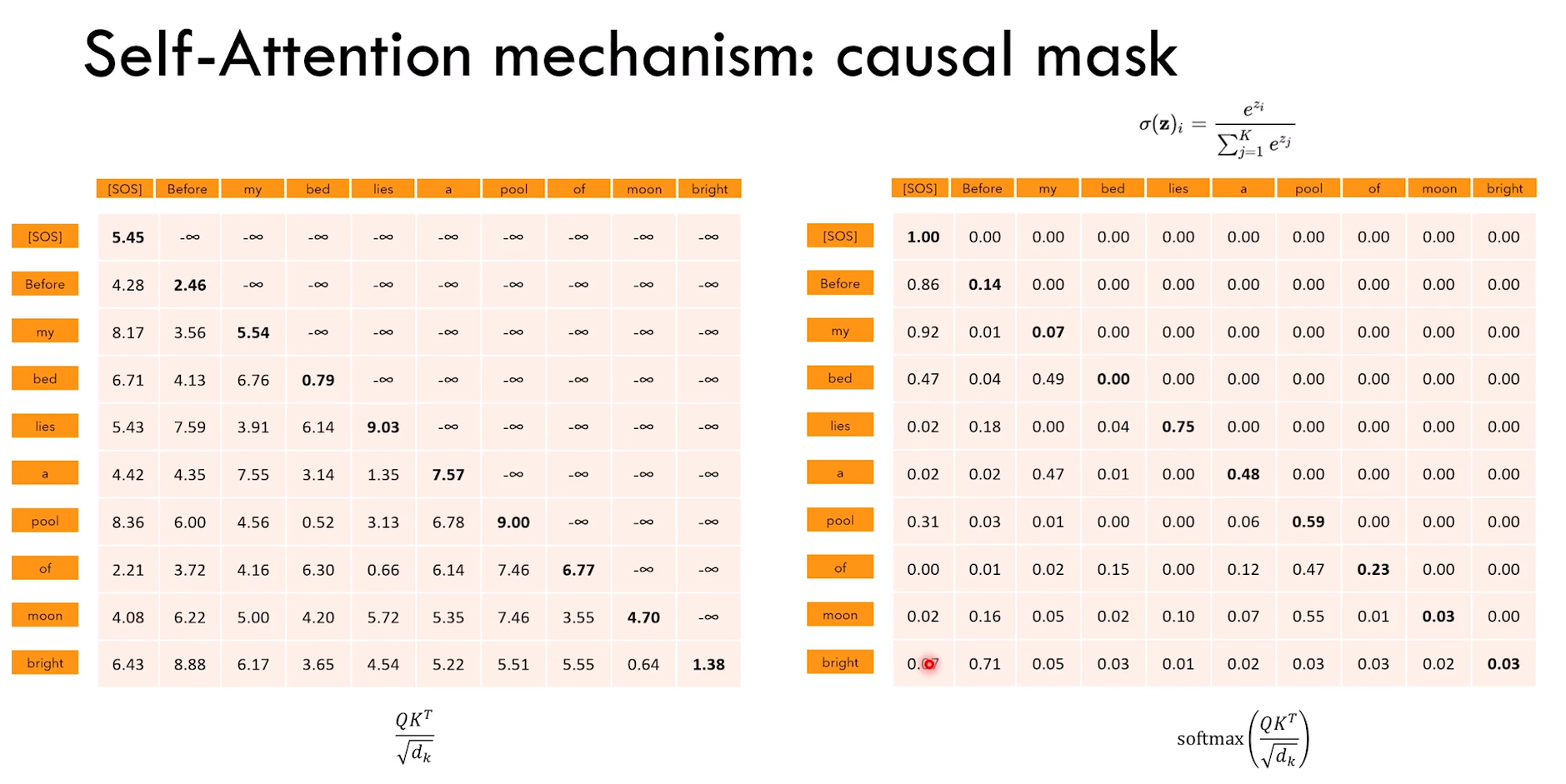
2)causal mask 使得 word 只能 “看到” 出现在它之前的 word
3)而 Bert 能够看到前后的 context
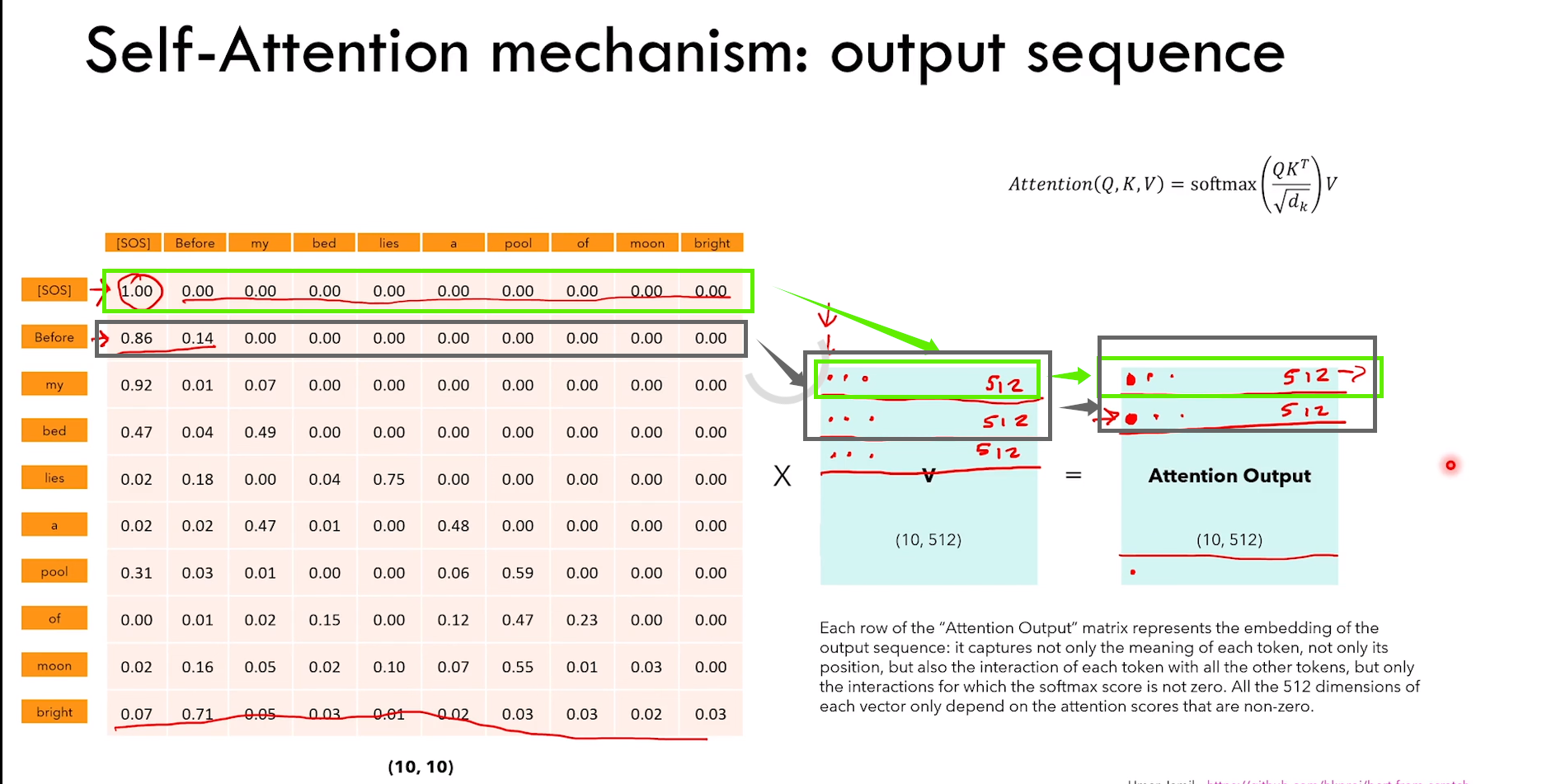
因为 token 只能看到它之前的 token
所以 QK转置 * V 的时候,第一个 token [SOS] 只能与 V 矩阵的第一行相乘(因为后面的元素全是0)
也就是 [SOS] 只有与自己 interaction
后面以此类推,Before 只能与 [SOS] 和 Before interaction
4 BERT
1)允许的最大 input token 数量是 512,但是 token 的嵌入维度(base768,large1024)
2)positional embedding 是训练期间习得的


1)bert 不能处理带有 prompt 的任务
2)bert 使用 left 和 right context 进行训练
3)bert 不能文本生成
4)bert 没有经过 next token预测(生成任务),但是经过了 masked language model 和 next sentence prediction
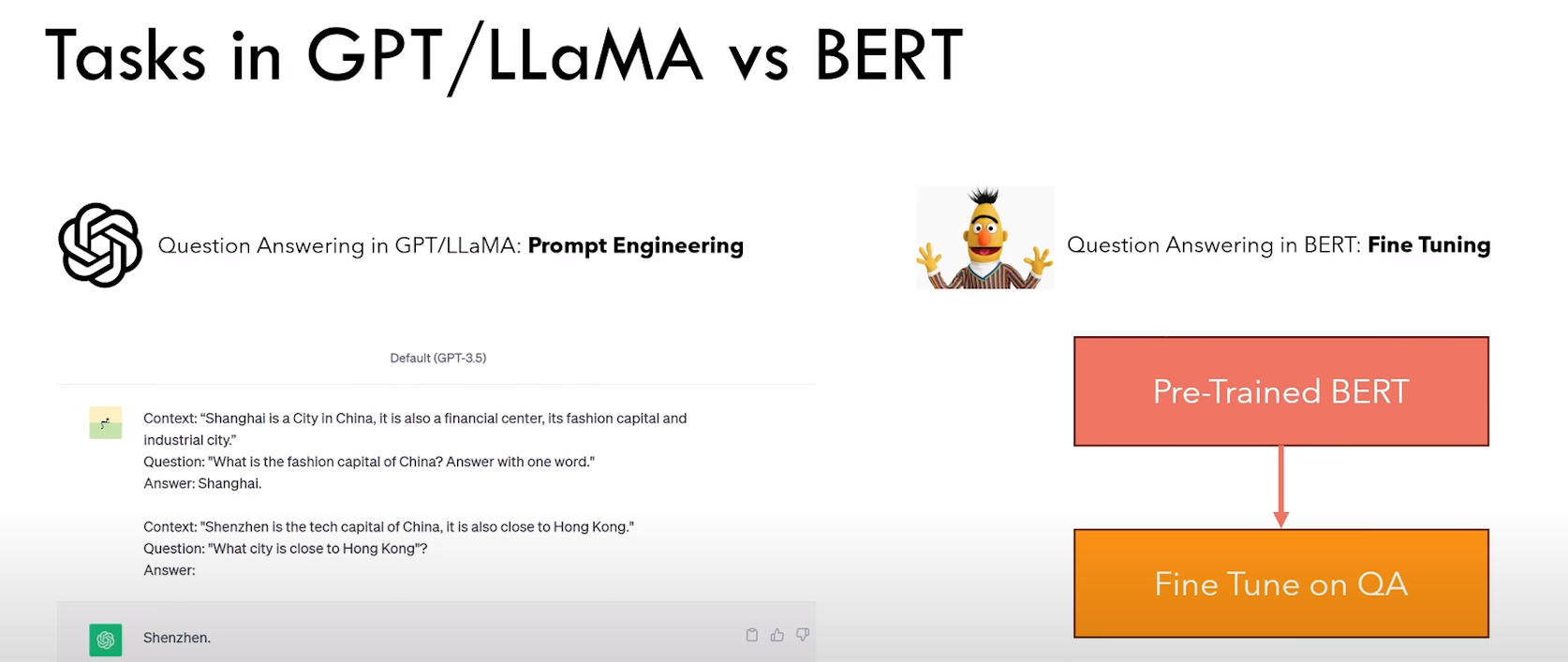
Bert 和 生成模型 使用方式的不同:
1)生成模型通过“上下文” + 提示工程
2)Bert 通过预训练 + 具体任务fine tune
4.1 左右 context 的重要性

4.2 BERT 预训练
4.2.1 Masked Language Model task

MLM 任务细节: 1)随机挑选一个 token,80% 概率用 [MASK] 替换,10% 概率用随机 token 替换,10% 概率不变
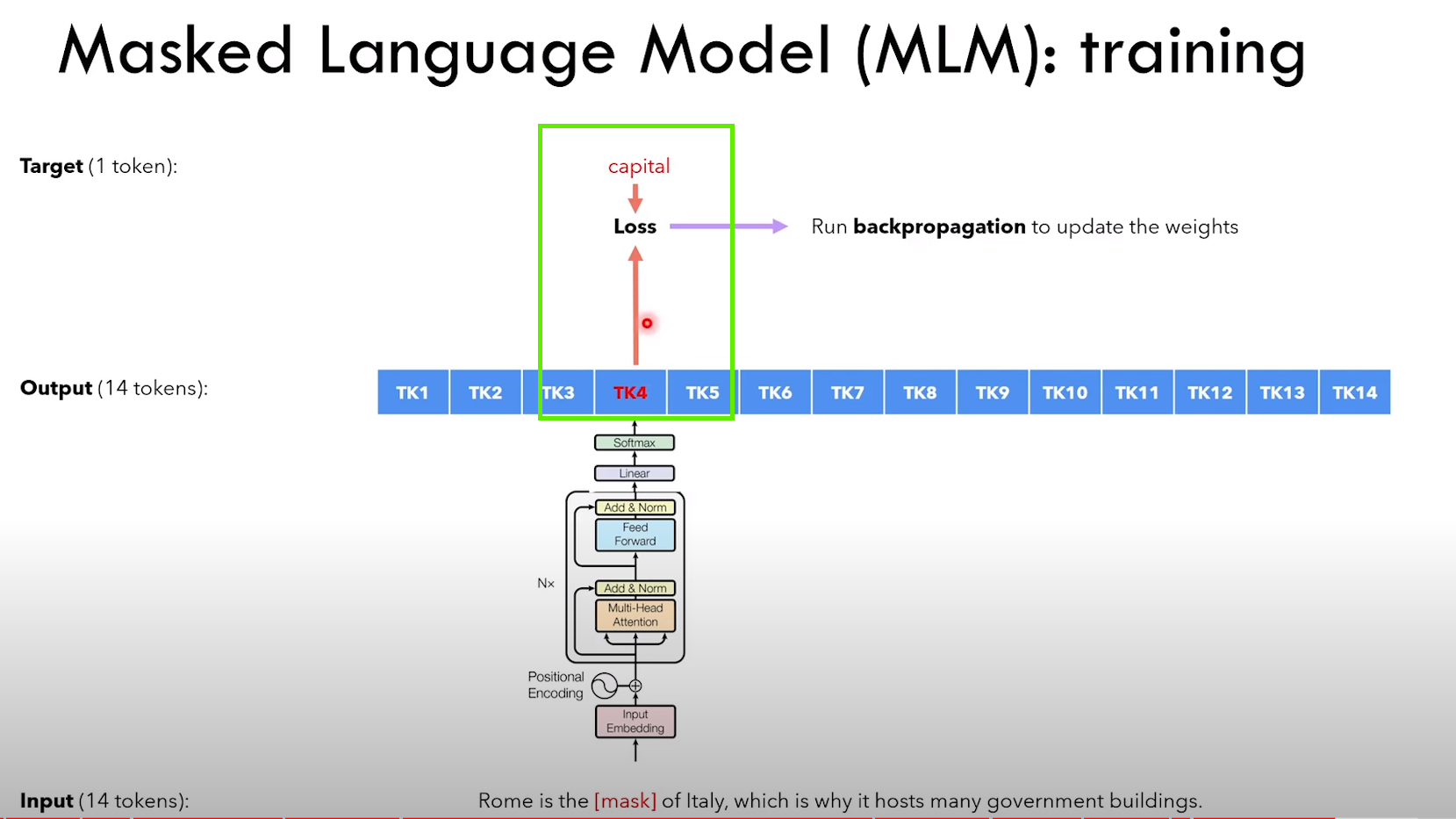
4.2.2 Next Sentence Prediction task
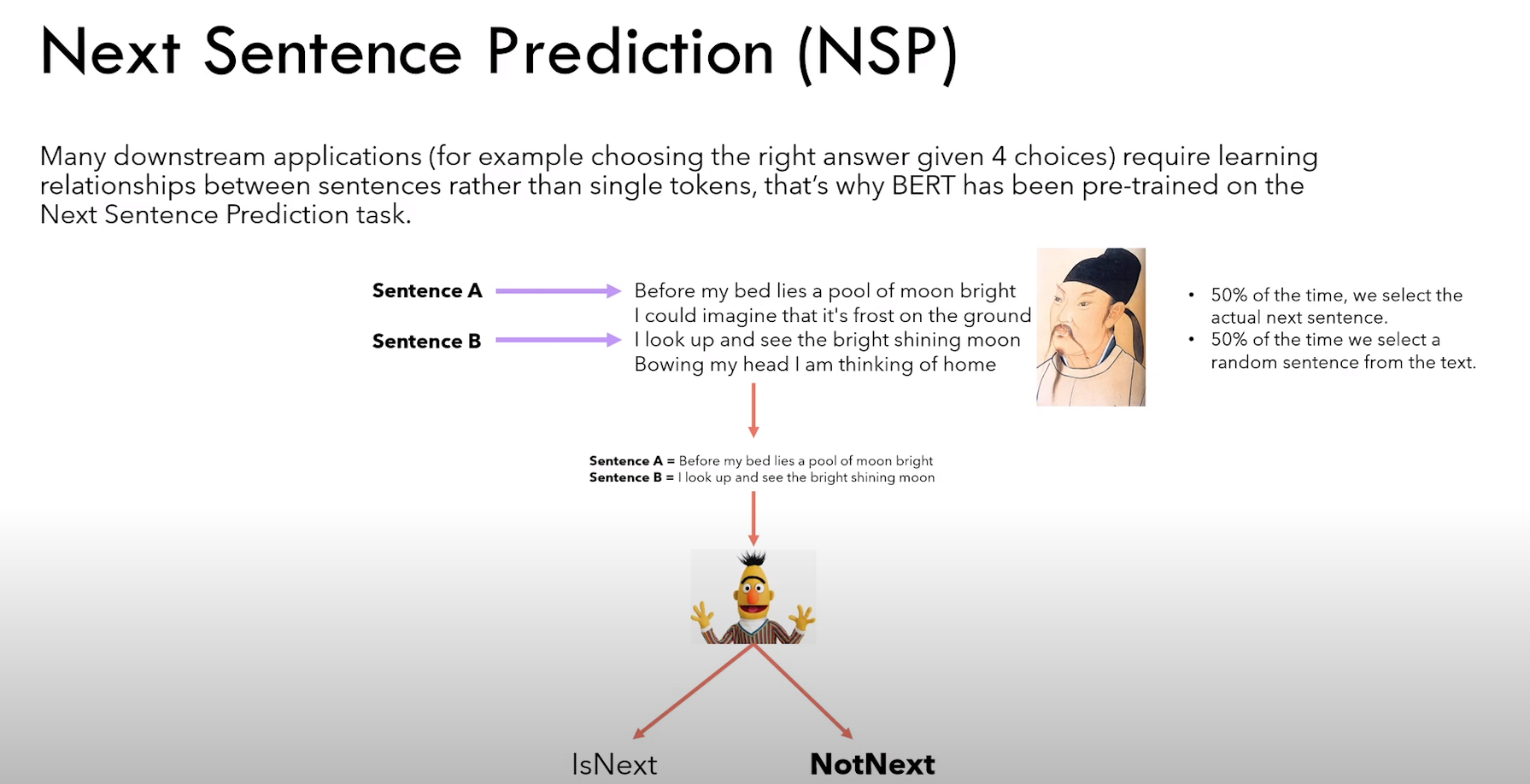
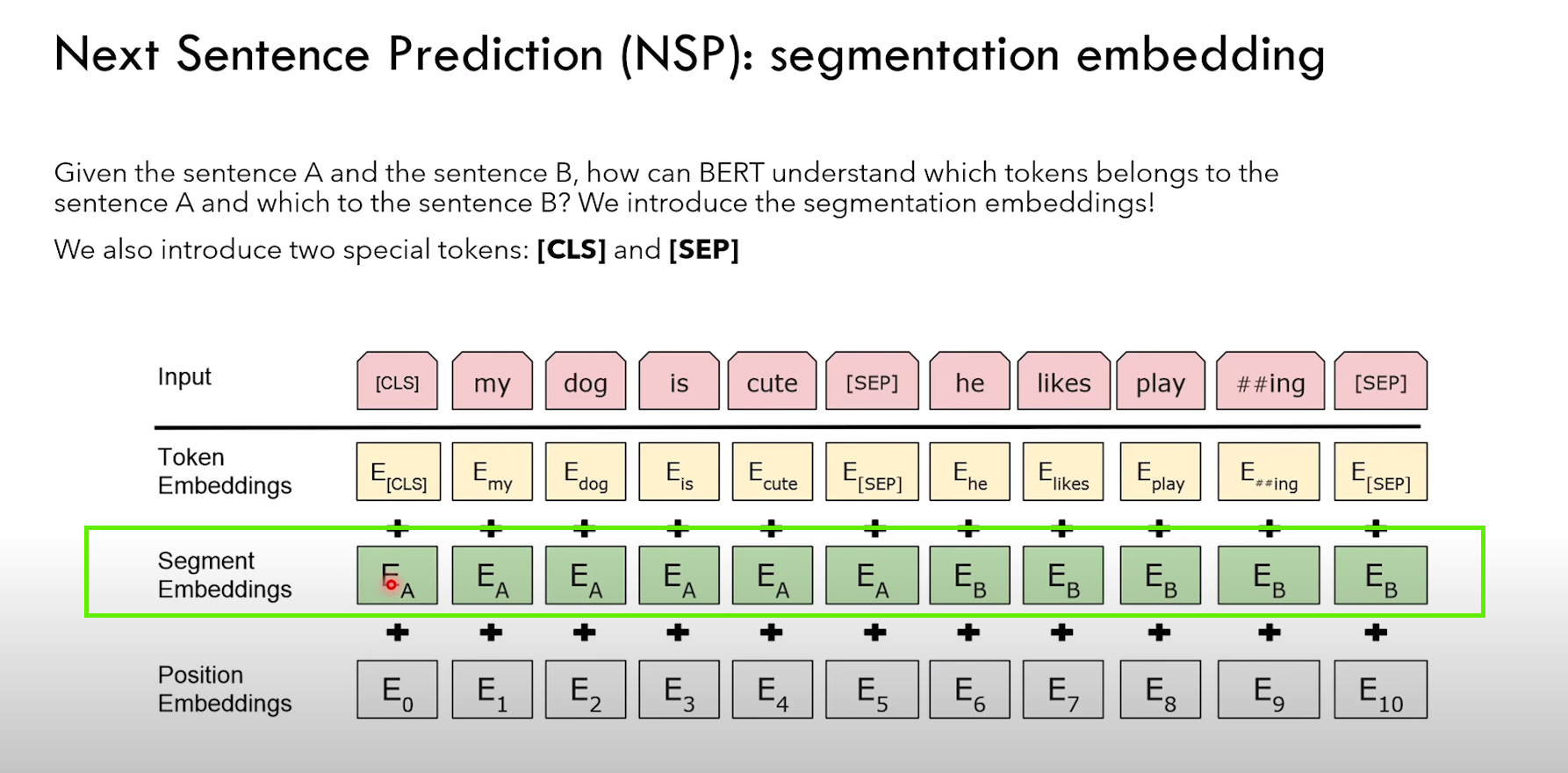
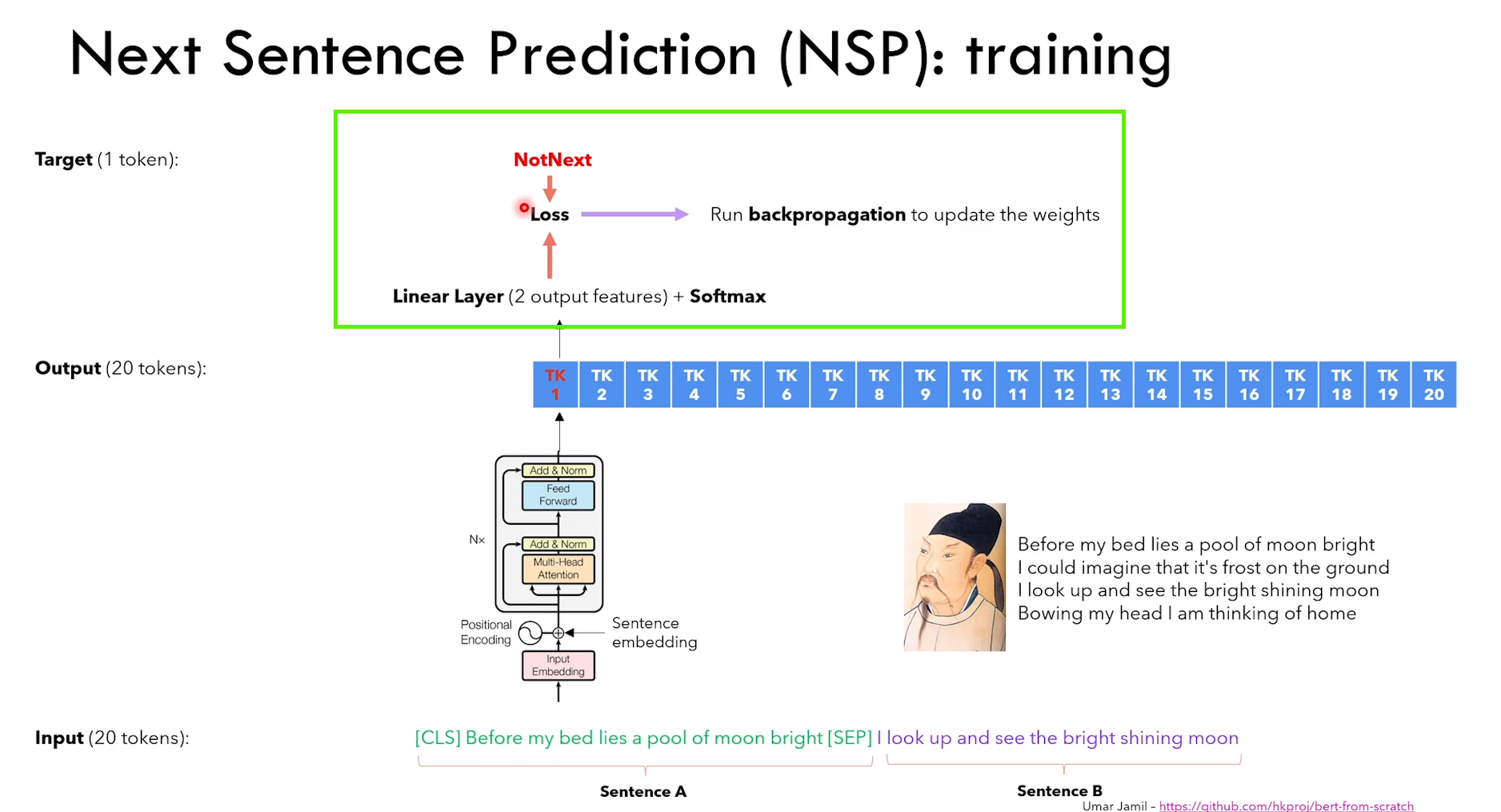
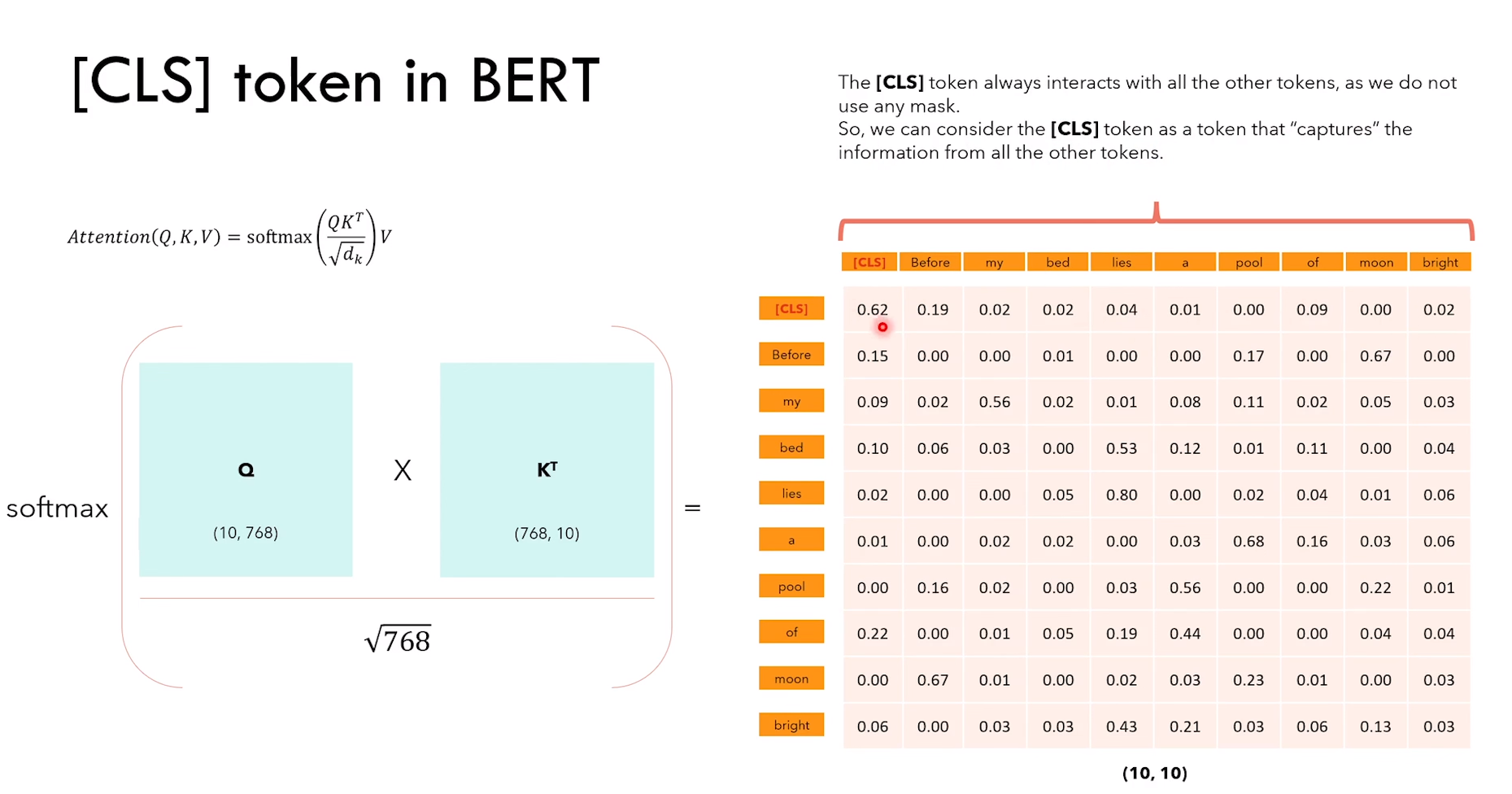

NSP 任务细节:
1)给定句子 A 和 B,判断 B 是不是 A 的下一句话
2)除了传统的 token embedding + positional embedding,还有 segment embedding(表征 token 属于哪个句子)
3)NSP 是一个分类任务,CLS 的输出进行二分类 IsNext or NotNext
4)CLS token 通过Q*K转置,可以看作捕获了所有 token 的信息
4.3 BERT 微调
4.3.1 文本分类任务
和上面的 NSP 任务类似,就是分类
4.3.2 问答任务
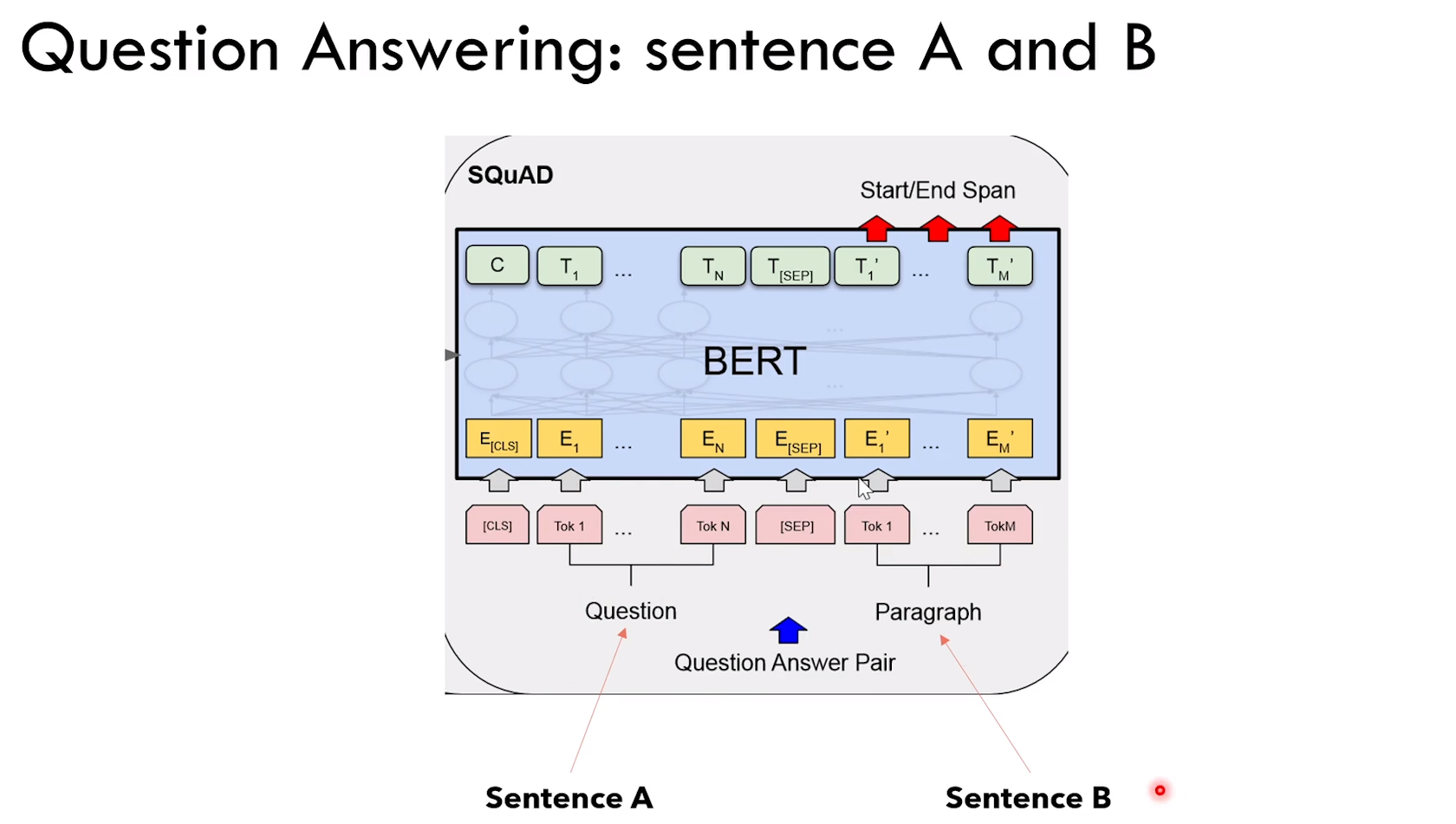
任务设定:给定 context + question,输出 answer
1)Bert 需要知道输入里面哪一部分是 context,哪一部分是 question
2)Bert 需要给出 answer 的开始和结束 token:线性层输出两个(起始token和结束token),然后计算损失
解决办法,分别看下面两图
















 529
529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









