







温馨提醒:本文主要分为5个部分,总计4842字,需要时间较长,建议先收藏!
-
P2P DMA简介
-
P2P DMA软硬件支持
-
CXL P2P DMA原理差异
-
P2P DMA应用场景
-
P2P DMA技术挑战
一、P2P DMA简介
P2P DMA(Peer-to-Peer Direct Memory Access)技术是一种允许连接到PCIe总线上的不同设备之间直接进行数据交换的机制,无需通过CPU和系统内存中转。这一特性极大地提升了数据传输效率,减少了CPU负载,并在特定场景下优化了系统性能。
P2P DMA的概念早在NVMe SSD和RDMA技术发展的初期就已出现。大约在2012年左右,Stephen Bates等人在研究NVMe、RDMA及NVMe over fabrics时发现了对设备间直接DMA的需求。早期实现主要依赖于一些具备可暴露内存区域(即现在的CMB - Controller Memory Buffer)的设备来实验性地支持P2PDMA。
Host与存储设备数据移动优化的技术中,控制器内存缓冲区(Controller Memory Buffer,CMB)是一个重要的概念。

自2014年以来,CMB被纳入到NVMe 1.2标准中,其目的是减少主机和设备之间的数据移动。CMB是控制器内部的一块专用内存,通过PCIe总线访问。当CPU需要访问存储设备的数据时,它可以通过内存读写事务层封装(MRd或MRw)直接访问CMB,而不需要将整个数据块传输到主机内存。
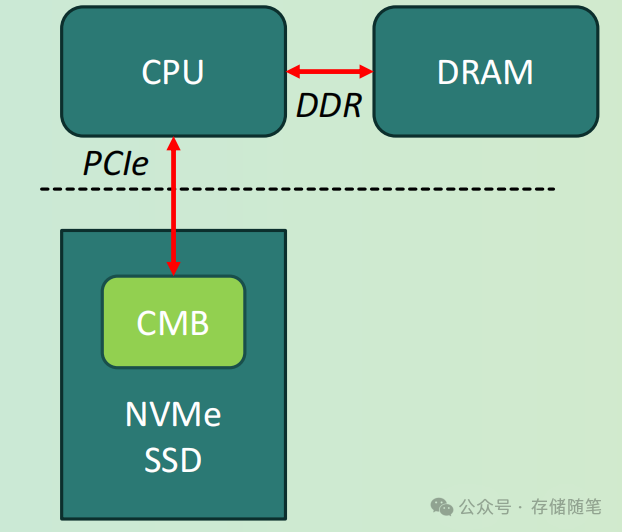
由于主机CPU无法像访问DDR内存那样高效地访问CMB,因此CMB通常被用作PCIe设备之间块数据传输的DMA(直接内存访问)缓冲区。这种方式减少了数据在主机和设备之间来回移动的次数,从而提高了数据传输效率。尽管CMB提供了一种优化数据移动的方法,但它仍然存在一些限制。例如,由于主机CPU访问CMB的效率低于DDR内存,且CMB的大小有限,因此对于需要频繁、大量数据交换的应用场景,CMB可能无法提供最佳的性能。
二、P2P DMA软硬件支持
随着时间的推移,随着硬件技术的进步以及软件栈的支持,如Linux内核从6.2版本开始提供用户空间对P2PDMA的支持,该功能逐渐成熟并应用在更多领域,例如NVIDIA GPUDirect Storage利用P2PDMA实现了GPU与NVMe命名空间之间的直接数据复制。
完整阅读:PCIe P2P DMA全景解读完整版本


















 2884
2884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











