









2.1 内存架构
在现代多处理器系统架构中,CPU Socket、内存Channel以及NUMA Node这几个概念紧密相关,共同构成了系统的基础架构,对理解计算机性能和资源分配至关重要。
CPU Socket:CPU Socket,也称为插槽,是主板上安装CPU的地方。在一个多处理器系统中,可能有多个Socket,每个Socket可以插入一个或多个物理CPU(或多核CPU)。每个Socket直接连接到一组内存Controller,控制着与其相连的内存通道和内存模块。因此,Socket的数量直接影响着系统可以安装多少颗CPU以及CPU与内存的直接交互能力。
内存Channel:内存Channel是指CPU通过内存控制器与DRAM内存模块通信的独立通路。每个Socket通常配备多个内存Channel,以提高数据传输速率和整体系统性能。增加内存通道可以实现并行读写操作,减少内存访问瓶颈。例如,一个Socket可能有两条、四条甚至更多内存通道,每条通道连接一个或多个DIMM。通过多通道架构,系统能更高效地管理内存带宽。
NUMA Node:在非一致内存访问(NUMA)架构中,NUMA Node是CPU、其直接相连的内存以及I/O资源的一个集合。每个Socket通常构成一个NUMA Node,因为它直接控制着与其相连的内存通道和内存。NUMA设计承认并管理内存访问的非均匀性,即CPU访问其直接相连的本地内存比访问其他Socket相连的内存更快。因此,进程调度和资源分配必须考虑NUMA拓扑,以优化数据局部性和性能。
-
Socket与Channel的关系:每个CPU Socket通过其集成的内存控制器(IMC)管理着一定数量的内存通道。这些通道直接决定了Socket能连接多少条DIMM,以及数据传输的并行程度。
-
NUMA Node的整合:在NUMA系统中,一个Socket及其关联的内存通道和本地内存组成一个NUMA Node。这意味着,每个Node代表了一个局部资源池,其中CPU访问本地内存的速度快于访问其他Node的内存。
-
性能与资源分配:了解这三个概念的关联对于优化系统性能至关重要。在多CPU系统中,合理安排进程在不同Socket(即NUMA Node)上的分布,确保进程尽可能使用本地内存,可以减少跨Node内存访问带来的延迟,提升系统效率。

2.2 内存错误类型
-
软错误与硬错误:软错误由宇宙射线等高能粒子引起的随机位翻转导致,一般可通过ECC纠正,称为Correctable Errors, CEs。硬错误则是物理损坏导致的错误,错误位维持不变,需要通过硬件替换解决,称为不可纠正错误(Uncorrectable Errors, UEs)
-
错误分类:故障模式按错误发生的位置分为行故障、列故障、bank故障及位固定故障,这有助于定位错误并采取相应措施。
由于UE相较于CE对停机时间有更大影响,许多研究致力于修改或预测UE。传统方法在CE重复到一定频率时判定为UE。为了提高UE的检测率,一些RAS技术利用特定的CE模式。然而,由于很多判定的UE并非真实UE,传统RAS技术无法避免因错误位置的内存访问被禁用而导致的内存损失。
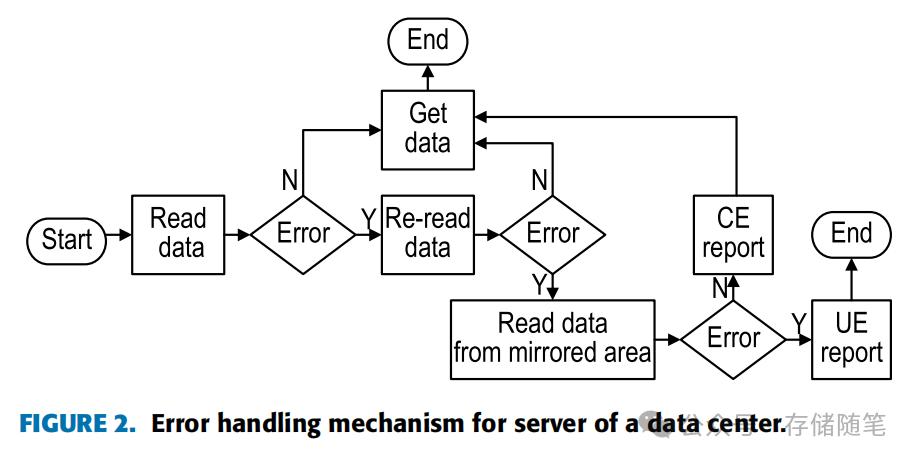
2.3 RAS技术
-
ECC技术:错误纠正码技术是RAS的关键组成部分,能够实时纠正单个错误并记录错误模式,预测未来可能的不可纠正错误(UE)。
-
高级ECC与多比特错误纠正:随着技术的发展,出现了如SEC-DAEC(单错误纠正-双相邻错误纠正)等技术,针对多比特错误和相邻错误进行纠正。此外,片上ECC(OD-ECC)和系统ECC的结合在新一代内存如DDR5中得到应用,显著降低了不可纠正错误率(UBER)。
-
预测性故障分析:通过对错误模式的分析,预测潜在故障,实现主动维护,减少停机时间。
-
高级CRC:循环冗余校验技术的进步,如SSC(单符号纠正),将特定比特转换为符号,结合SPC-RS码,实现了更高的错误检测和纠正效率,减少了延迟。
-
人工智能在UE预测中的应用:为减少因错误预测导致的内存损失,引入了基于人工智能的UE预测技术,尽管这可能增加计算开销。
数据中心内存系统的设计与优化是围绕提高系统可靠性和降低维护成本进行的。随着硬件规模的增长和工作负载的多样化,内存RAS技术不断演进,从基础的ECC技术到复杂的预测算法、人工智能应用,都在努力减少软硬错误带来的影响,确保数据中心的稳定运行和高效服务。
RAS特性广泛应用于数据中心的大多数硬件上,且硬件故障率受数据中心工作负载类型的影响。数据库和缓存服务因其频繁访问存储设备而可能导致更高的内存故障率。同时,Web服务、Hadoop处理和数据摄入等应用要求CPU进行大量计算和频繁内存访问,使得内存RAS在满足多数工作负载所需的扩展能力方面扮演着日益重要的角色。

















 1360
1360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











