







近日在SemiAnalysis论坛看到一篇深度的DRAM分析文章,内容非常充实,小编截取部分亮点内容做个解读。如需直接阅读原文,可以在文章底部点击“阅读原文”查看。
此前针对内存墙相关话题,小编也有一些粗浅的总结,供各位读者对比参考!
世界越来越质疑摩尔定律是否已经消亡,但悲剧在于,它实际上在十多年前就已经悄然逝去,没有引起任何关注或头条新闻。人们通常只关注逻辑芯片的进步,但实际上摩尔定律也适用于DRAM。
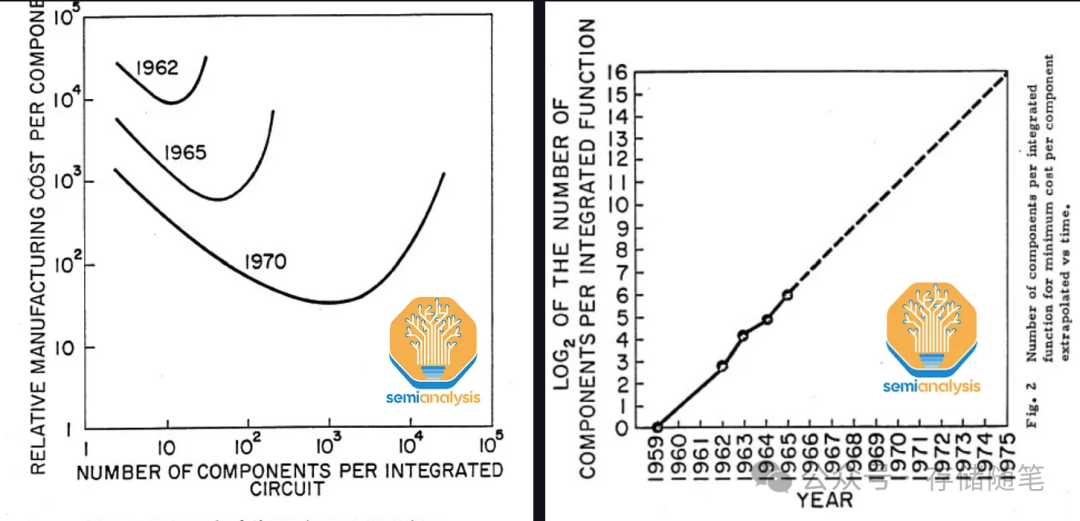
在辉煌时期,内存位密度每18个月翻一番——甚至超越了逻辑芯片的发展速度。这意味着每十年内存密度能增加超过100倍。但在过去的十年里,这种扩展已经显著放缓,密度仅增长了2倍。
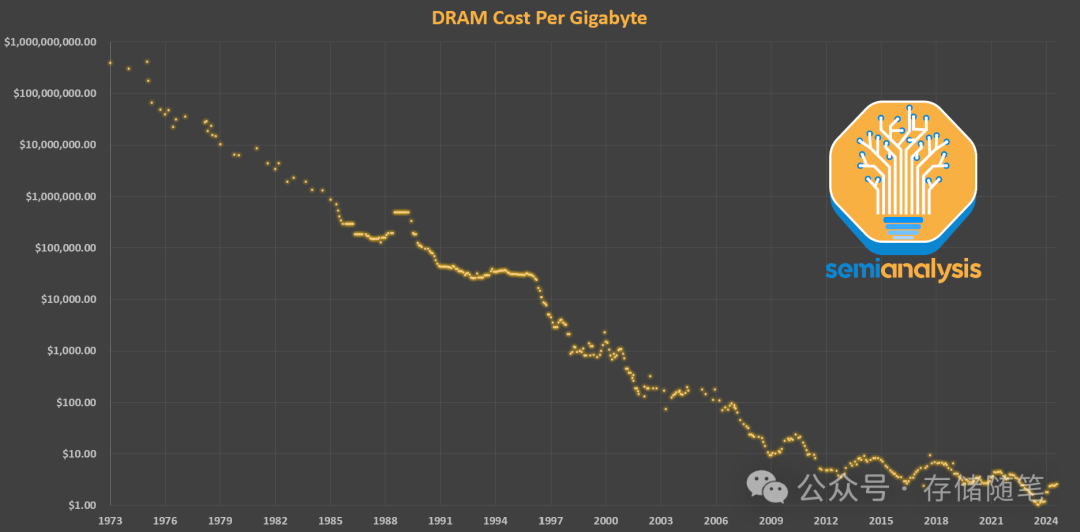
随着人工智能的爆发式增长,行业平衡进一步被打乱。虽然逻辑芯片在密度和每个晶体管的功能成本方面都有显著提升,但DRAM的速度改进却进展缓慢。尽管市场上存在大量的虚假信息,台积电3nm和2nm节点上的每个晶体管的成本仍在下降。而对于内存来说,带宽的增加主要是通过昂贵的封装来实现的。
高带宽内存(HBM)作为加速器内存的支柱,每GB的成本比标准DDR5高出3倍以上。客户不得不接受这一事实,因为如果不这样做,他们就无法构建具有竞争力的加速器包。这种平衡是不稳定的——未来的HBM代际将继续变得更加复杂,层数更高。随着模型权重接近多TB规模,AI内存需求正在爆炸性增长。对于H100而言,约50%以上的制造成本归因于HBM,而在Blackwell上,这一比例增长到60%以上。

换句话说,DRAM产业已经遇到了瓶颈。尽管计算能力的提升速度虽然也在减缓,但仍然远超内存的改进速度。如何重新加速DRAM领域的创新步伐?哪些创新可以用来改善未来的带宽、容量、成本和功耗?
有许多可能的解决方案。鉴于数百亿美元的人工智能资本支出摆在桌面上,业界有强烈的动机推动这些解决方案向前发展。
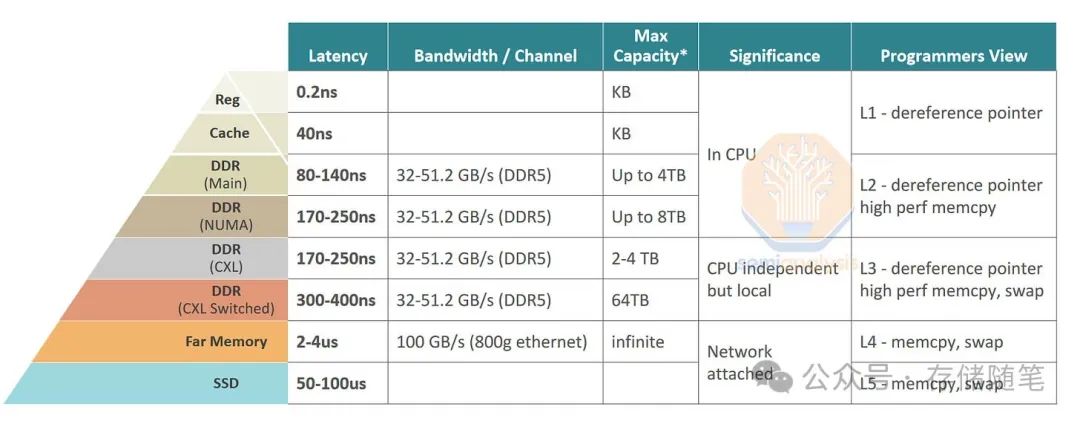
计算机中有多种类型的存储器,最快的是静态随机存取存储器(SRAM),它兼容逻辑处理技术,位于CPU或GPU上。因为它是在逻辑芯片上,SRAM也是最贵的一种内存——每字节的成本比动态随机存取存储器(DRAM)高出100倍以上,因此只少量使用。在另一端是非易失性的NAND固态硬盘、硬盘驱动器和磁带。这些便宜但速度太慢,不适合许多任务。DRAM则位于“金发姑娘区”,介于SRAM和闪存之间,速度适中,价格适中。
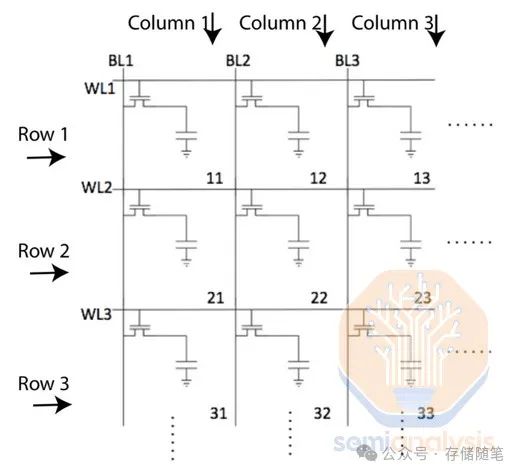
原则上,DRAM很简单。它由一个网格布局的内存单元阵列组成,每个单元存储一位信息。所有现代DRAM都使用1T1C单元,表示1个晶体管和1个电容器。晶体管控制对单元的访问,电容器则以微小的电荷形式存储信息。
在20世纪,摩尔定律和Dennard缩放规则主宰了半导体行业。在巅峰时期,DRAM的密度增长超过了逻辑芯片。DRAM每片的容量每18个月翻一番,这推动了日本工厂的崛起(1981年首次超过美国市场份额并在1987年达到顶峰,市场份额约为80%),随后是韩国公司(其市场份额在1998年超过了日本)。快速的代际替换和相对简单的工艺流程为新的参与者提供了机会,只要他们有足够的资金建立下一代工厂。
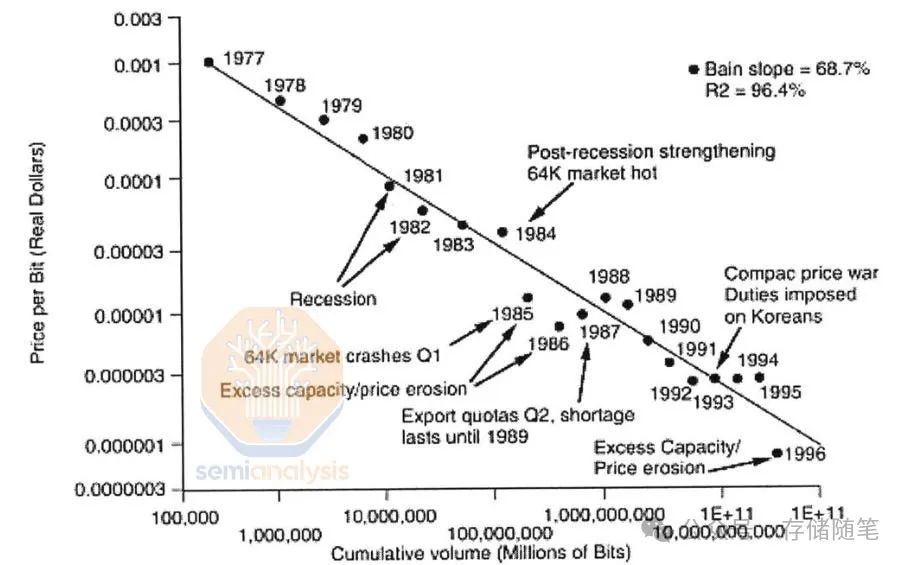
在“黄金时代”的20年内,DRAM的位单价降低了三个数量级。然而,这种节奏不可能长久持续,进入21世纪后,逻辑芯片的扩展明显超过了内存。最近的逻辑缩放已经放缓至每两年30%-40%的密度提升,但这仍然比DRAM快得多,DRAM现在需要大约10年的时间才能实现密度翻番。
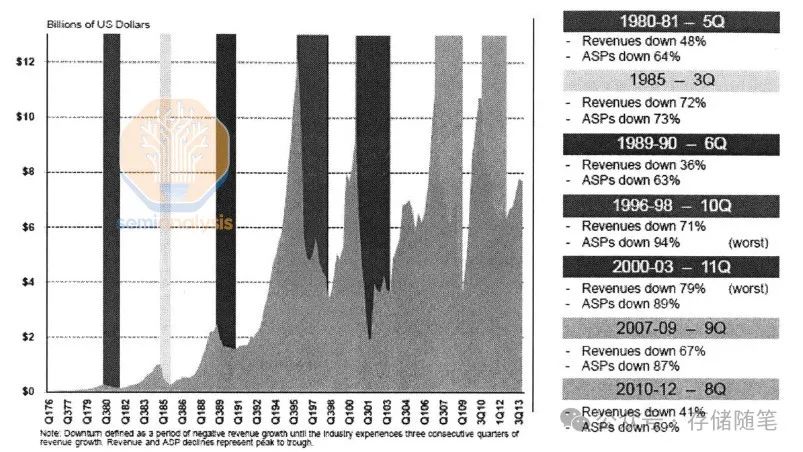
这种扩展放缓对DRAM的价格动态产生了连锁反应。虽然内存历来是一个周期性的行业,但缓慢的密度缩放意味着当供应受限时,几乎没有成本降低来缓冲价格上涨。唯一增加DRAM供应的方法是建造新的晶圆厂。价格的剧烈波动和高昂的资本支出意味着只有最大的公司能够生存下来:1990年代中期有超过20家制造商生产DRAM,其中前十大制造商占据了80%的市场份额。而现在,前三大供应商占据了超过95%的市场。
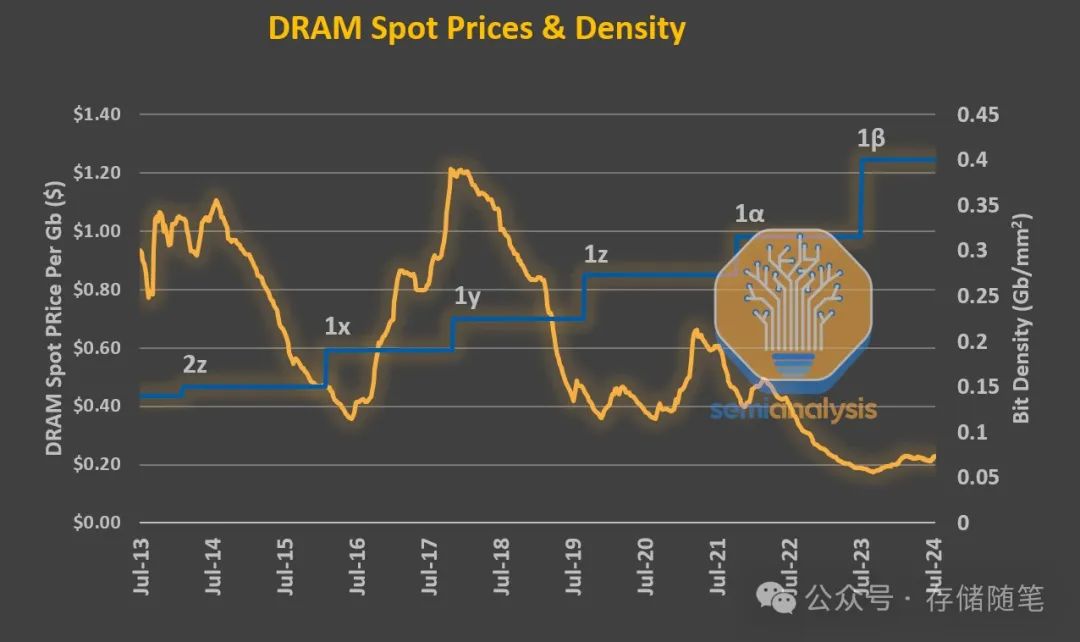
由于DRAM是一种商品化的产品,供应商对价格波动更加敏感,并且必须在市场低迷时主要依靠产品的原始价格进行竞争。逻辑芯片虽然保持了摩尔定律,但成本不断增加,而DRAM没有这样的奢侈条件。DRAM的成本很容易衡量,即$/Gb。相较于早些时期,过去十年的价格下降速度较慢——在一个十年内仅下降了一个数量级,而过去只需要一半的时间。DRAM特有的高峰和低谷行为也很明显。
自从进入10纳米节点以来,DRAM的位密度停滞不前。即使是三星在其1z节点和SK海力士在其1a节点中引入的EUV光刻技术也没有显著提高密度。两个值得注意的挑战在于电容器和感测放大器。
电容器在很多方面都是困难的。首先,图案化要求很高,因为孔必须紧密排列,并且需要很好的临界尺寸(CD)和覆盖控制,以便接触下方的访问晶体管并避免桥接或其他缺陷。电容器具有非常高的长宽比,蚀刻一个直而窄的孔轮廓是非常困难的,特别是需要一个更厚的硬掩模以允许更深的蚀刻,而更厚的掩模又需要更厚的光刻胶,这使得图案化更加困难。
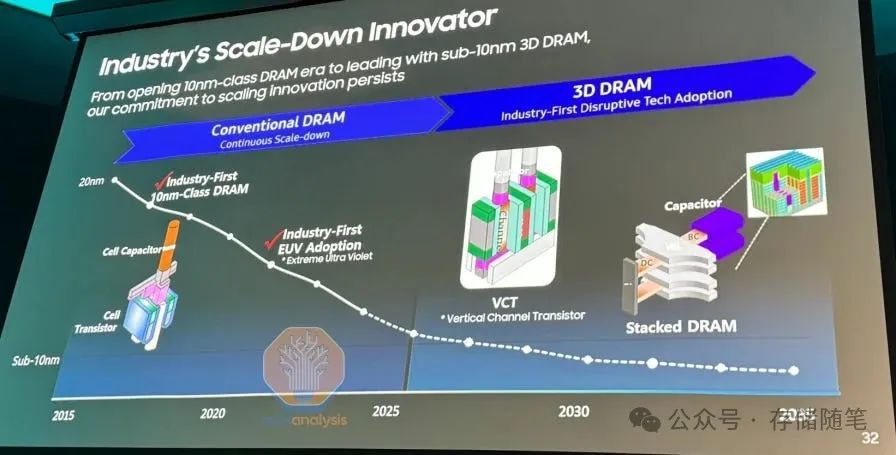
接下来,需要在整个孔轮廓上沉积几纳米厚度的多个无缺陷层以形成电容器。几乎每一步都使现代处理技术达到了极限。
感测放大器的故事与逻辑互连类似。曾经被认为不重要的它们,现在甚至比“主”特征(逻辑晶体管和内存单元)更难或同等难度。它们受到多方面的挤压。面积缩放必须与位线缩小相匹配,导致感测放大器变得更不灵敏,更易受变化和泄漏的影响。与此同时,更小的电容器存储较少的电荷,因此读取它们所需的感应要求变得更为困难。
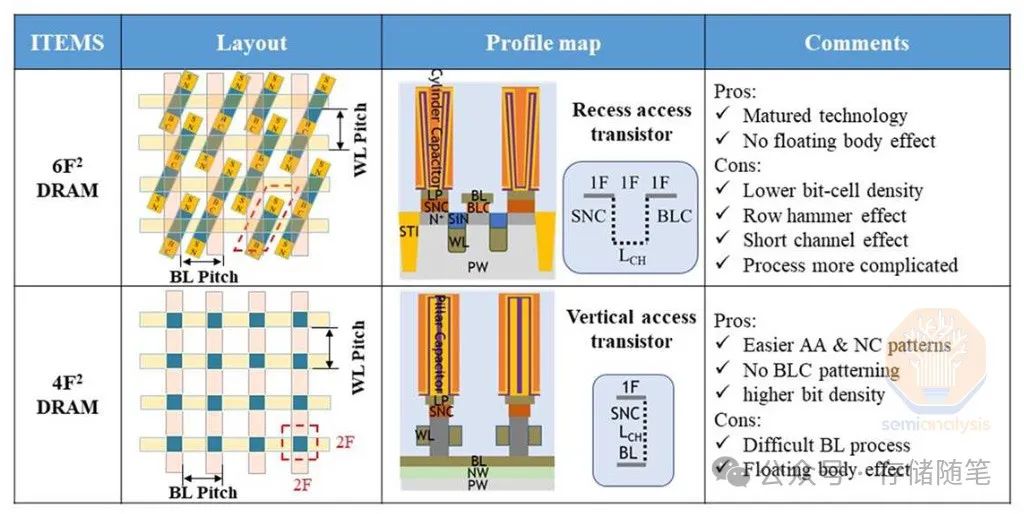
还有其他挑战,总体来说,用传统方法以经济的方式缩放DRAM正变得越来越困难。这为新思路打开了大门——让我们探索一些新的想法...
DRAM有很多种类,每一种都针对不同的目标进行了优化。相关的最新一代变种包括DDR5、LPDDR5X、GDDR6X和HBM3/E。它们之间的差异几乎完全在于外围电路。内存单元本身在各种类型中是相似的,制造方法也大同小异。
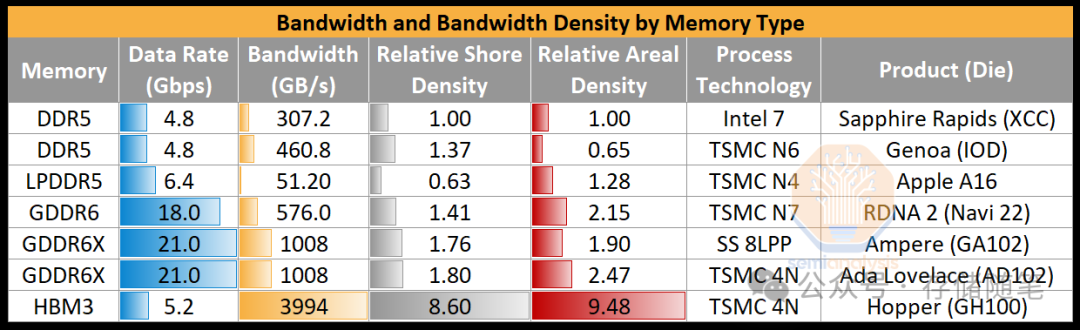
DDR5(双数据速率第五代)提供了最高的内存容量,因为它被封装在双行内存模块(DIMMs)中。LPDDR5X(低功耗DDR5,X代表增强版)提供了低功耗操作,但需要较短的距离和低电容连接到CPU,这限制了容量,因此用于移动电话和笔记本电脑,在这些设备中低功耗是有利的,并且布局约束是可以容忍的。
在加速器中,LPDDR已经成为“第二层级”内存的最佳选择,它以较低的成本和较低(较慢)的级别提供比昂贵的HBM更大的容量。它在构建最高容量和可靠性方面略显不足。
高带宽内存(High Bandwidth Memory, HBM)作为一种围绕传统DRAM理念构建的封装解决方案,旨在通过高密度和邻近性解决人工智能和其他高性能计算中的带宽和功耗问题。目前所有领先的AI GPU都采用了HBM作为其内存方案。预计到2025年,HBM3e将会采用12层堆栈,每层32Gb,总共48GB,数据传输速率可达8Gbps。在GPU服务器中,AMD的MI300A和Nvidia的Grace Hopper已经推出了带有支持CPU的统一内存的第一个版本。

Grace CPU配备了高容量的LPDDR5X,而GPU则配备了高带宽的HBM3。但是,CPU和GPU位于不同的封装中,通过NVLink-C2C以900GB/s的速度连接。这种模型虽然在集成方面较为简单,但在软件层面却带来了挑战。连接到另一个芯片上的内存的延迟较高,可能会对许多工作负载产生影响,从而使得内存并不完全统一。
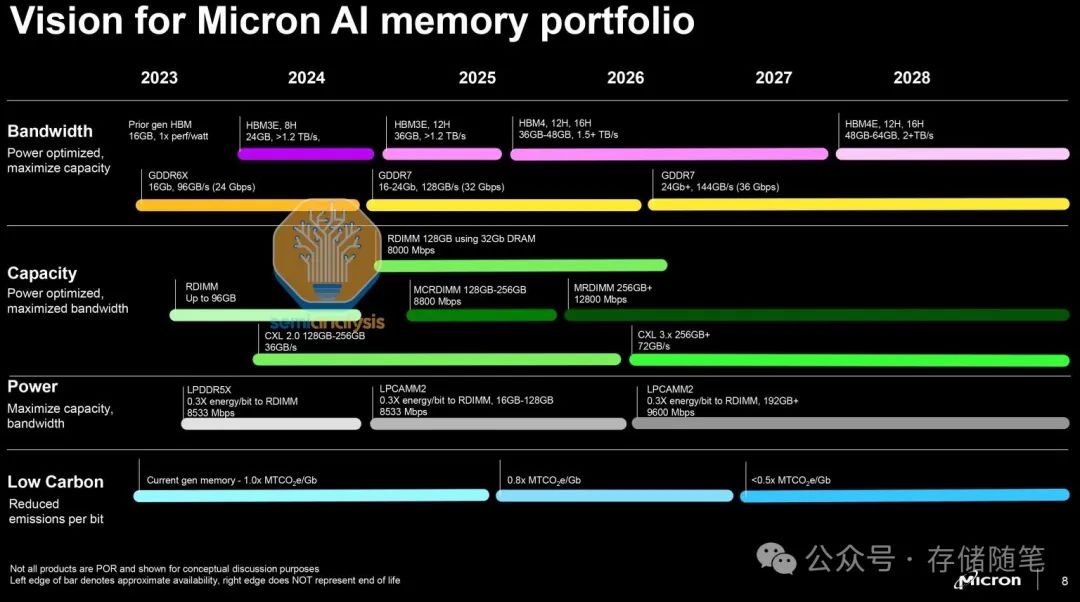
对于HBM4,三星和美光声称将在未来几年内推出高达16层堆栈,每堆栈带宽达1.5TB/s。这比目前的带宽提高了两倍以上,但仅以1.3-1.5倍的功率,这样的缩放比例仍不足以应对整体内存功耗持续增加的问题。HBM4还将转向2048位宽的堆栈,稍微降低数据传输速率至7.5Gbps,有助于减少功耗和改善信号完整性。预计HBM4E或类似的版本的数据速率会恢复到HBM3E的水平。
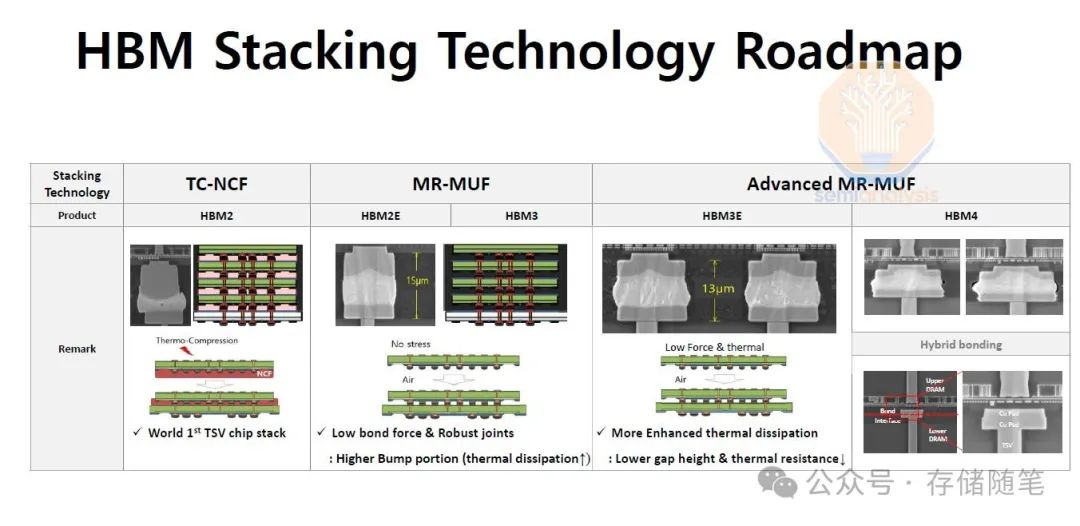
HBM4的另一个重大变化是在HBM基板(base die)上。基板将使用FinFET工艺制造,而非当前使用的平面CMOS技术。对于没有这种逻辑能力的美光和SK海力士来说,基板将由台积电等代工厂生产。此外,基板将根据个别客户的需求进行定制。
HBM4及后续版本可能会转向混合键合技术,这将允许更薄的HBM堆栈,因为消除了凸块间隙,从而改善散热。此外,它可以支持16-20层以上的堆栈高度。虽然信号传输的实际距离缩短可能会稍微减少功耗,但实现这一点的技术挑战依然很大,即在16层以上的堆栈中获得高产量并非易事。
最初的所有HBM4都不会使用混合键合技术,而且我们预计这种情况将持续很长时间。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











