







由于"维数灾难"问题,在高维空间中处理最近邻查询是非常昂贵的;因此,近似方法,如局部敏感哈希(Locality-Sensitive Hashing, LSH),因其理论保证和经验性能而被广泛使用。当前基于lsh的方法的目标是L1和L2空间,而如之前的工作所示,分数距离度量(Lp度量)可以为数据挖掘和多媒体应用提供比通常的L1和L2指标更有洞察力的结果。然而,现有的工作都不能支持使用一个索引来支持多个分数距离度量。在本文中,我们提出了LazyLSH,它可以在理论上保证的情况下回答多个Lp指标的近似最近邻查询。与以往需要为每个查询空间建立一个专用索引的LSH方法不同,LazyLSH使用一个基索引来支持多个Lp空间的计算,大大减少了维护开销。实验结果表明,LazyLSH在分数距离度量下为近似kNN搜索提供了更准确的结果

背景:

1)无法估计稳定的密度分布值
2)导致较高的计算成本
方法:
LazyLSH在预定义的Lp0空间中构建LSH索引,该空间称为基础空间。使用这个物化索引,LazyLSH可以在特定于用户的查询空间中回答近似的kNN查询。LazyLSH意味着我们不为每个查询空间建立索引。相反,我们重用在基空间中构建的索引来回答查询空间中的查询。

为了得到更精确的结果,我们提出了一种以查询为中心的rehashing方法来搜索基索引并检索附近的对象。我们进一步观察到,在不同Lp度量下的查询处理过程中,会探测许多常见的索引条目。这一发现激励我们通过共享它们的I/ o来并发优化不同Lp指标下的多个查询的处理

总结:文中的思想是在建立一个索引,能够使用所有的Lp空间。


3. LAZYLSH
在本节中,我们将LazyLSH作为一种有效的机制来处理不同Lp空间中的近似kNN查询。我们从概述开始,然后说明LazyLSH的技术细节。在本文中,我们提出了一种新颖的方法——LazyLSH,它可以使用不同的分数距离度量和单个LSH索引处理近似最近邻查询
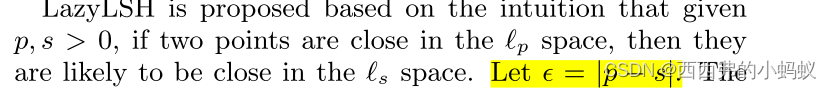
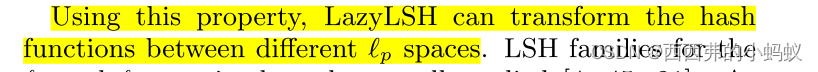

3.2 LSH in an Lp Space


3.3 Computing Internal Parameters
。。。。。。。。。。。。。。。。。
。。。。。。。。。。。。。。。。。
阅读者总结:这篇论文的思想很好,一个索引可以使用在所有的Lp空间中。















 6079
6079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









