






Towards Effective and Efficient Mining of Arbitrary Shaped Clusters
在大规模数据集中挖掘任意形状的聚类是数据挖掘领域的一个挑战。针对这个问题,人们提出了各种时间复杂度较高的方法。为了节省计算成本,一些算法试图将数据集的大小缩小到具有代表性的数据示例的数量。然而,用户自定义的收缩比例可能会显著影响聚类性能。本文提出CLASP算法,用于挖掘任意形状的簇。该算法在缩小数据集规模的同时,有效地保留了具有代表性数据实例的数据集中簇的形状信息。然后,调整这些代表性数据实例的位置,增强它们之间的内在联系,使聚类结构更加清晰、清晰;最后,在合成数据集和真实数据集上进行了大量的实验,结果验证了该方法的有效性和高效性。
主要贡献
针对挖掘任意形状簇的问题,提出了一种高效的解决方案CLASP (Clustering aLgorithm for任意形状簇)算法。
第一阶段(见图1(b))自动缩小数据集的大小,以减少计算成本,同时保留集群的形状信息。
第二阶段(见图1(c))使簇结构更加清晰、清晰,以提高聚类的准确性。为此,CLASP调整代表数据示例的位置,使每个代表数据示例更接近其同质邻居,同时远离其他代表数据示例。
第三阶段(见图1(d))完成任意形状簇的挖掘。为了实现这一点,CLASP采用一种新的相似性度量方法,以凝聚的方式对有代表性的数据样本进行聚类
最后 利用CLASP合并分布在每个任意形状簇不同部分的小簇,并将原始数据集中每个代表数据样例的簇标签分配给其代表数据样例。 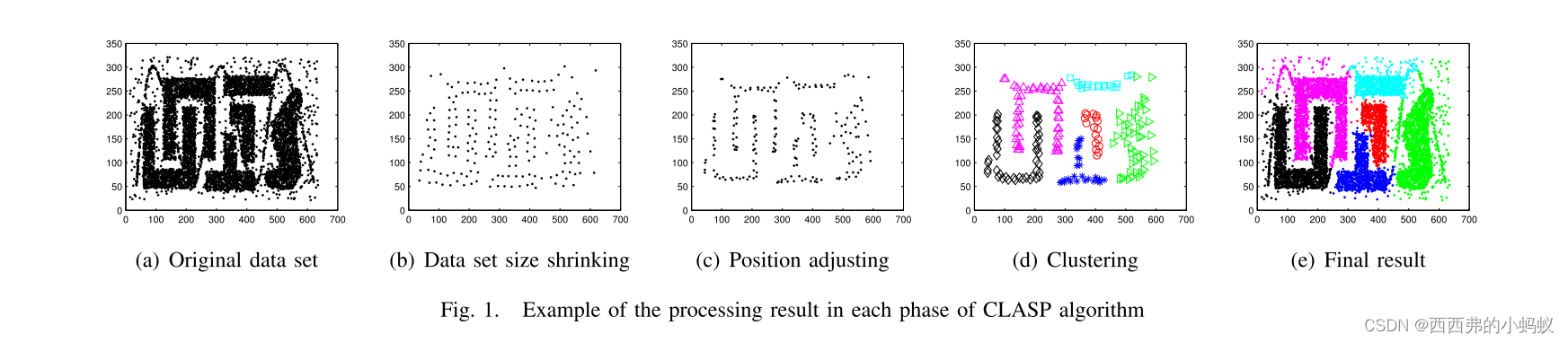
总而言之,我们的主要贡献如下。(1)提出了一种数据集的自动收缩方法,可以在几乎不影响簇形状的情况下显著减少数据集的大小。(2)针对任意形状簇的数据实例,提出了一种位置调整方法,使簇结构更加清晰,便于聚类。(3)提出了一种新的相似性度量Pk,使凝聚聚类更加有效地挖掘任意形状的簇。

















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









