









周宇翔
contrastive learning for unsupervised domain adaptation of time series
无监督域适应(UDA)旨在使用标记的源域学习机器学习模型,该模型在类似但不同的无标记目标域上表现良好。UDA在许多应用中都很重要,例如医学,它用于适应不同患者队列的风险评分。本文开发了一种新的时间序列数据UDA框架,称为clua。本文提出一种对比学习框架来学习多元时间序列中的上下文表示,以便为预测任务保留标签信息。在该框架中,通过自定义最近邻对比学习,进一步捕捉源域和目标域之间上下文表示的变化。据我们所知,我们的框架是第一个学习时间序列数据UDA的域不变上下文表示的框架。用广泛的时间序列数据集对所提出框架进行了评估,以证明其有效性,并表明其在时间序列UDA方面取得了最先进的性能。
1. 总结是基于对比学习的无监督迁移学
2. 完成的目标:
为实现这一目标,纳入以下组件:(1)通过对抗性训练最小化源域和目标域之间的域差异。(2)通过一组保持语义的增强来生成正对,然后学习它们的嵌入,从而捕获上下文表示。为此,我们利用对比学习(CL)。(3)通过自定义最近邻对比学习进一步对齐源域和目标域的上下文表示。
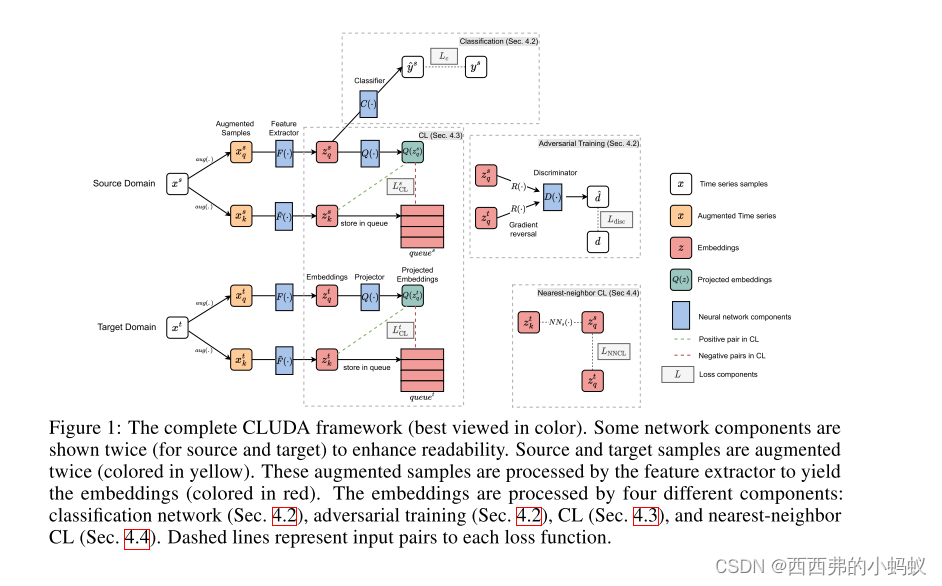

本文提出一种基于对比学习的时间序列UDA新框架,称为clua。据我们所知,CLUDA是第一种为UDA在多元时间序列中学习域不变的上下文表示的方法。此外,CLUDA为时间序列UDA实现了最先进的性能。重要的是,我们的两个新组件-即我们的定制CL和NNCL -产生了明显的性能改进。最后,我们希望我们的框架对于风险评分应该跨人群或机构转移的医疗应用具有直接实用价值。















 2273
2273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









